

4日晚间,上海人工智能实验室宣布,开源全球首个基于“通专融合”架构的万亿参数科学多模态大模型——Intern(书生)-S1-Pro。这是全球开源社区中参数规模最大的科学模型,其性能表现稳居全球第一梯队,为AI for Science从“工具革命”的1.0阶段迈向以“革命的工具”驱动科学发现的2.0时代,提供创新的系统性开源基座。
值得一提的是,书生万亿科学大模型验证了从原创模型架构到国产算力基座自主技术的完整链路。通过开源开放,书生万亿科学大模型旨在降低全球科研门槛,与学术界和产业界共同推动以通用人工智能驱动科学发现的范式革命。
创新底层架构:突破万亿参数科学模型边界
上海人工智能实验室主任、首席科学家周伯文提出:可深度专业化通用模型是实现AGI的可行路径,其关键挑战在于:专家化模型在训练过程中需要低成本、能规模化的密集反馈;能够持续不断地学习与主动探索,并具备为同一个问题提供多视角、多种解决方案的能力;并能引入对物理世界规律的考量,兼顾多项差异化能力的学习效率与性能。
资料图:上海人工智能实验室主任、首席科学家周伯文 摄影:陶磊
新民晚报记者了解到,此次发布的书生万亿科学大模型通过多项SAGE基础模型层的技术创新,拓宽了模型应用边界、提升了超大规模训练可行性,推进了可深度专业化通用模型的探索。
为构建能更深层次理解物理世界规律的科学大模型,研究团队引入了傅里叶位置编码(FoPE)并重构时序编码器。FoPE为AI赋予双重视角:既能像看“粒子”一样捕捉文字之间的相对距离,又能像分析“波”一样把握科学信号的整体规律与频率。
研究团队还革新了内部的“路由机制”。传统方法存在训练低效和算力浪费两大痛点,新技术通过“路由稠密估计”,让模型在高效运行的同时能进行更充分的学习,提升了稳定性;进而通过“分组路由”策略,像智能交通系统一样使海量计算芯片实现负载均衡,避免了资源闲置。
“书生万亿科学大模型不仅在规模上刷新了科学多模态模型的参数规模上限,也为SAGE架构所提出的‘通用能力与专业能力协同演进’提供了可落地的实现路径。”上海AI实验室科研人员表示。
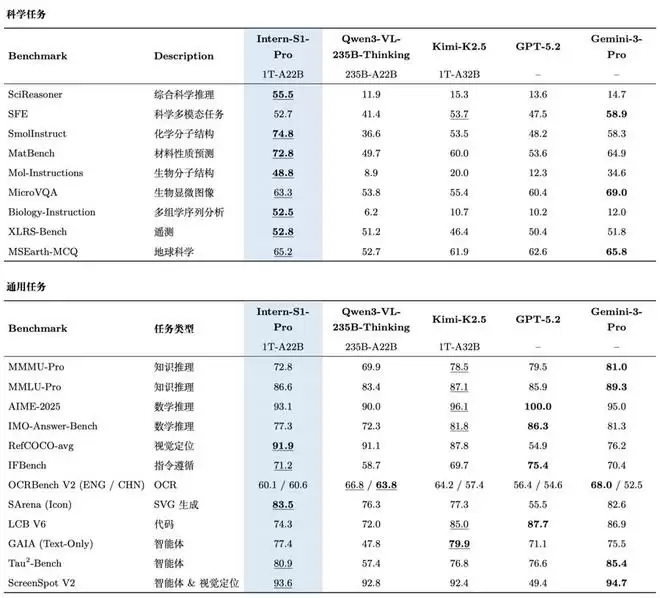
书生万亿科学大模型在评测基准中的表现:通用能力表现出色,科学能力达国际领先水平
科学能力再进化,通用能力协同演进
得益于创新的底层架构设计与万亿参数超大规模训练策略,书生万亿科学大模型的科学能力进一步升级。
在国际数学奥林匹克(IMO-Answer-Bench)和国际物理奥林匹克(IPhO2025)两大权威基准测试中,书生万亿科学大模型均展现出竞赛级别的解题能力。
而在AI for Science关键垂类领域,书生万亿科学大模型成功构建了一个跨越化学、材料、生命、地球、物理五大核心学科的全谱系能力矩阵,涵盖100多个专业子任务,不仅单学科成绩优异,更是在SciReasoner等高难度的综合学科评测基准中,取得了与顶尖的闭源商业大模型相当,甚至更优的成绩,稳居第一梯队。
新民晚报记者获悉,在基础理解维度,书生万亿科学大模型能够精准解析复杂的分子结构图及各类实验图表;深入到逻辑推理层面,书生万亿科学大模型能够处理高阶科学问答,如反应条件推断、理化性质预测,精准捕捉数据背后的因果规律等。
随着理解与推理能力的持续增强,书生万亿科学大模型的能力边界不断向真实科研场景延伸,其应用范围从微观层面的化学逆合成、蛋白质序列生成,拓展至宏观尺度的遥感图像分析等复杂任务。
“模型正展现出从‘解题’迈向‘解决问题’的科研生产力价值,为前沿科学探索提供了坚实支撑。”科研人员透露。
筑牢“算力—算法”一体化基座
在规模、性能提升的同时,书生万亿科学大模型构建了原创的“算力—算法”一体化基座。模型从架构设计之初,便与昇腾计算生态确立联合研发路线,实现了从最底层的算子、编译优化到上层的训练、推理框架的深度全栈适配。此外,它还与沐曦联合研发利用模型加速算子适配。

值得一提的是,自2024年书生大模型首次发布以来,上海AI实验室已逐步构建起丰富的书生大模型家族,包括科学多模态模型、大语言模型书生·浦语、多模态模型书生·万象、强推理模型书生·思客等;同时首创并开源了面向大模型研发与应用的全链路开源工具体系,覆盖数据处理、预训练、微调、部署、评测与应用等关键环节,形成覆盖数十万开发者参与的活跃开源社区。
自发布以来,科学多模态模型多次登顶HuggingFace全球多模态榜单,累计下载超41万次,并获得近200家科研机构和企业的合作申请。其卓越的跨模态科学理解能力不仅为科研提供了高效工具,也通过开源降低了全球科研团队迈入AGI for Science的门槛。
原标题:《从“解题”到“解决问题”!上海开源万亿参数科学大模型,AI成为科研合伙人》
栏目编辑:马丹




