上海交大测评具身智能,会是机器人的LMArena吗?

智东西
作者 陈骏达
编辑 漠影
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
在具身智能领域,一个越来越突出的现实是:Demo,似乎成为了技术能力的通用叙事方式。
在发布会、短视频和展台上,我们反复看到类似的场景,机器人在精心布置的环境里完成一次抓取、一段行走,流程流畅、效果惊艳。
然而,一旦离开展示场景,问题便变得复杂得多。换一个光照条件、换一个物体材质、稍微打乱顺序,系统是否还能稳定工作,外界往往无从得知。

不同厂商基于不同任务与展示方式来定义“领先”,使得这些Demo之间既难以横向比较,也难以被复现验证。在缺乏统一评测标准的情况下,Demo与实际落地之间的差异逐渐放大。
日前,图灵奖得主姚期智便在一场演讲中点破了这一现状:(具身智能行业)要从各说各话到统一评测,建立开放机制、安全规范等等,鼓励开源复现与挑战赛,让优秀的算法可以重复使用,可验证、可产业化。
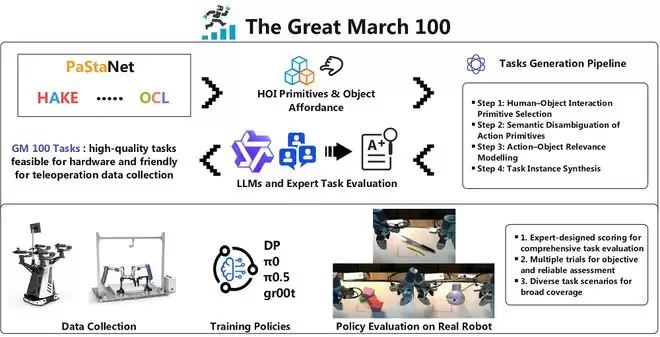
这一呼吁背后的核心,正是建立一套统一、科学且可被反复验证的评测体系。2026年开年,上海交通大学等机构联合发布的GM-100,正是目前国内少数试图在这一方向上给出系统性解决方案的尝试之一。
一、具身智能,缺一张“统考卷”
在一个仍处于早期探索阶段的技术领域,评测体系的意义并不止于给模型排个名次,更像是一张“统考卷”:它通过题目设置,明确哪些能力被认为是重要的,哪些问题值得被长期投入,从而在无形中塑造和引领整个行业的研究方向与技术路线。
但从现实情况来看,具身智能领域的评测体系仍然较为分散。不同企业和研究团队往往使用各自的任务集、评测流程和指标体系:有的侧重抓取成功率,有的关注路径规划,有的强调单一长任务完成情况。
现有的评测在一定程度上推动了行业早期的发展,但其任务设置多集中于高频、相对简单的场景。随着模型能力的提升,这类基准对真实应用的区分度正在下降,也越来越难以反映具身智能在复杂环境中的核心挑战。
当模型已经可以稳定完成这些“标准动作”时,继续在同一类任务上刷分,往往只能体现工程调优或场景适配能力,而难以揭示模型在复杂条件下的真实表现。行业在判断技术成熟度时,仍然缺乏一个被广泛认可的客观参照。
面向具身智能的未来,一个好的评测体系不只考“常见题”,还应覆盖偏题、难题和综合题,结构上既有基础能力测试,也有对长尾行为和复杂交互的检验。
它的目标不是让模型看起来“很强”,而是清晰呈现模型在真实执行中的能力边界——在哪些条件下可以稳定工作,在哪些情况下会失败,失败模式又是什么。
同时,随着具身任务从单一动作走向长序列、多步骤协作,评测也不能唯结果论。是否完成任务固然重要,但完成过程中的决策质量、异常处理方式、对环境和人类行为的响应,同样是衡量系统成熟度的关键维度。
过去一段时间里,学术界和工业界已关注到这一问题,并着手解决。从李飞飞教授的BEHAVIOR,到HuggingFace联合业内打造的RoboChallenge,各种新的评测体系,恰恰折射出了行业对更全面评测的迫切需求。他们希望通过更具挑战性和解释力的测试体系,为技术演进提供清晰坐标。
二、让机器人穿糖葫芦、开抽屉,如何揭示具身智能的能力边界?
GM-100由100个任务组成,每个任务大约有100条训练轨迹和30条测试轨迹,总计13000条操作轨迹,规模已经不小。不过,相比单纯追求规模的数据集,真正让GM-100与其他测评集打出差异化的,是其任务多样性和评估系统性。
GM-100的主要作者与项目牵头人、上海交通大学副教授李永露告诉智东西,其实验室践行的理念是“以数据为中心的具身智能”。
他认为在这个时代,数据集和评测对科研的贡献超过了60%,加些数据,或是让数据的分布更为健康,便有可能大幅推动模型能力的提升。
研究中,团队对现有的海量数据集和任务进行了统计,发现大部分任务仍以 “pick, hold, place”这三大类为核心。因此,GM-100选择了以长尾任务和精细操作为重点,力图展现当前具身智能在真实世界操作中的能力边界。
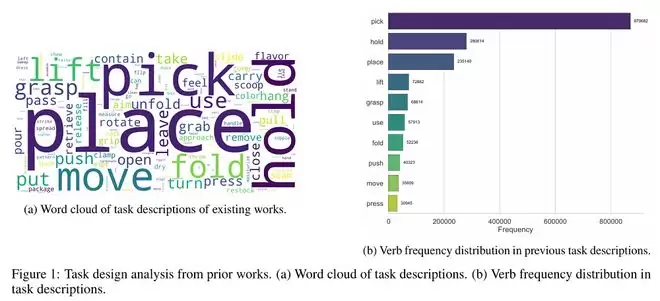
任务设计过程中,研究团队先对人类与物体的交互原语进行了系统分析,然后借助大语言模型生成候选任务,再经过专家筛选与优化,最终形成100个任务。这些任务从日常常见到罕见,从简单到复杂。
这些任务中有不少“反直觉”的存在——人类觉得非常精细困难的任务,机器人反而能够较好完成;而人类认为非常简单的操作,机器人却经常失败。
该实验室成员、上海交通大学博士生王梓宇告诉我们,像穿糖葫芦这样人类认为对机器人比较复杂的任务,机器人已经能够做到一定水平,而开抽屉、按台灯开关或整理小物体等直觉上简单的任务,却因为机械臂构型、物体材质、位置摆放以及指令理解等因素而变得困难。
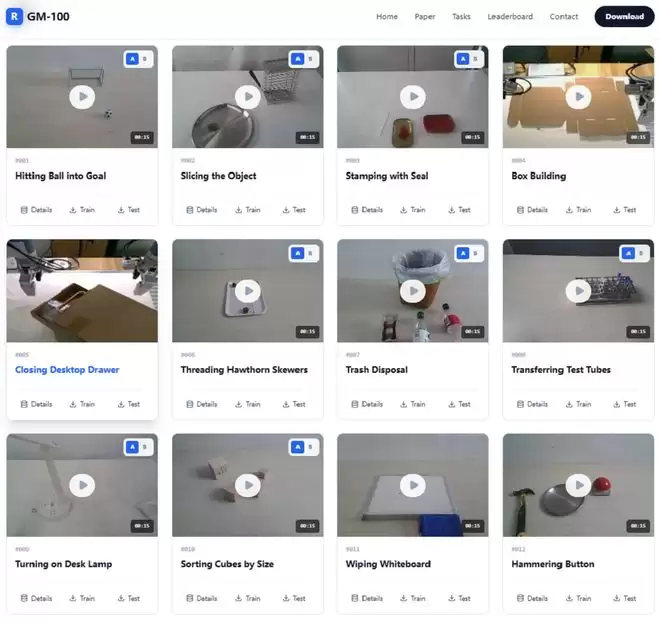
▲GM-100中的部分任务
在现有评测体系普遍面临任务同质化、容易被针对性优化“刷榜”的背景下,GM-100通过高度多样化且长尾的任务来贴近真实物理世界。这拉高了针对性优化的成本,进而有效引导模型发展通用能力,避免模型仅在简单任务上过拟合的倾向。
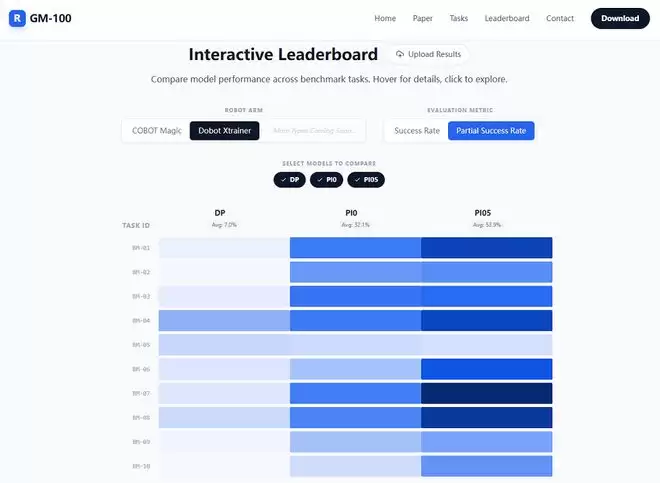
在研究论文中,GM-100背后的团队已经验证了这一测评集的有效性。他们对Diffusion Policy(DP)、π₀、π₀.₅及GR00T等主流具身学习模型进行了测试。值得注意的是,GM-100评估指标不止于传统的任务成功率(SR),还引入了部分成功率(PSR)和动作预测误差。
PSR让多步骤任务的细节完成情况可量化,动作预测误差则衡量模型在新轨迹上的模仿精度。这种多维度指标使研究者能从不同角度衡量模型表现的强弱,遏制了模型通过“作弊”、“走捷径”完成部分动作,鼓励研究者关注模型真正的泛化和模仿能力。
结果显示,GM-100的任务在许多机器人平台上都可执行,但也没有过于简单,不同模型在GM-100上的表现拉开了区分度,这证明任务设计本身是合理的。跨平台测试也表明,这些任务在不同机器上具有一定的泛化价值,为评估模型能力提供了可靠参考。
三、不做“爹味很浓”的测评集,Benchmark不只靠权威说话
不过,对一个测评集来说,打造出来仅仅是第一步。如何让更多的人用起来,对它产生信赖,可能是更为关键的一步。
在与李永露的沟通中,我们了解到,GM-100团队在打造这一测评集的时候就意识到,一个真正有生命力的评测体系不能只靠“权威”,而应走向“社区共建”。

▲李永露
换言之,他们似乎并未将自己定位为“裁判”,而是“搭台者”。
当前的机器人学习模型仍显著受到测试者能力和环境条件的影响,GM-100不是要成为一个绝对公平的物理测试环境,这在当前的产业发展阶段也不现实。GM-100打造了一个开放平台,研究人员可以自主上传测试结果与证据视频。
为了让更多人参与这一评测,GM-100开源了全部100个任务的详细说明,需要购买的物料清单精确到了淘宝链接,还上传了每个任务约130条真实机器人操作数据,极大降低了复现门槛。
对于开源模型,GM-100团队进行验证与作者身份确认,要求提交模型权重以供审核,并为符合标准的提交打上“已验证”标签。未来,GM-100还会丰富社区的功能,让用户可以点评、收藏,表达自己的见解。
李永露说,他们不想成为一个“爹味很浓”的组织,来告诉大家应该怎么做,因为这样很有可能丧失公信力。相反,他们希望让研究社区以“悠悠众口”的模式,长期讨论并建立共识,最终形成对模型能力的客观评价。这种模式也有望让“刷榜”、“作弊”的模型在群众监督下现出原形,最终建立起透明、可信的基准测试体系。

▲GM-100的数据采集工作(图源:RHOS)
对熟悉大模型评测的读者来说,GM‑100在理念上让人联想到LMArena。
LMArena 的公信力来自一种去权威化的评测机制:平台通过匿名双盲对比和真实用户投票,让性能评估不依赖单一指标、不受品牌影响,再用Elo排名体系动态反映真实偏好,而非靠构建者主观设定的权威分数。
在这一点上,GM 100同样强调机制而非权威背书。它通过跨平台数据、详尽的交互说明和多维度指标体系,使评估结果具有可复现性和解释性,而非依赖实验者主观裁定。
两者都探索了一种面向社区与实际表现的评估范式,试图让评测结果既透明可检验、又不受单一权威框架制约。
结语:GM-100将进一步扩展,不怕干“脏活累活”
李永露告诉我们,团队不会止步于GM-100数据集的发布。GM取自“Great March”,寓意“长征”,团队将逐步把任务库扩展至300乃至1000项,并推进跨机器人平台评测,以增强评测的覆盖面。
长远来看,他们希望通过任务设计的系统化、评测维度的多元化(如引入进度评分、安全性、社会价值等指标),打造更科学、更工程化的具身智能评测“奥林匹克”。
数据集和评测的构建是公认的“脏活累活”。正如李永露所说:“评测其实是一个挺苦的事情,这类工作并非在空调房里写写代码就能完成,而需要实实在在动手操作,甚至拧螺丝。但完成后,对整个世界的贡献却非常巨大。”他希望更多年轻人、研究团队和企业能够参与,共同推进这一事业。
相关攻略

作为的主编,我每天都在思考:AI能在内容生产中承担什么角色?思来想去,还是认为一些重复性的工作,可以交给AI,比如早晚报。整个科技领域,包含人工智能、PC数码、手机、互联网、新能源等等,每天都有数不

在人工智能快速发展的今天,我们经常听说AI助手能够调用各种工具帮助人类完成任务,比如查询信息、计算数据或生成文档。然而,在现实应用中,这些AI助手必须在各种限制条件下工作——就像一个厨师不仅要会做菜

IT之家 3 月 17 日消息,科技媒体 Android Authority 今天(3 月 17 日)发布博文,报道称三星承认 Galaxy S26 Ultra 旗舰手机的“防窥屏”(Privacy

(文 张志峰 编辑 周远方)3月12日,2026年中国家电及消费电子博览会(AWE)在上海拉开帷幕,这场以“AI科技慧享未来”为主题的行业盛会,不仅是家电家居前沿技术与新品的展示舞台,更成为洞察行业

一、前言:比OLED更优秀的显示技术在很多老玩家的印象中,OLED价格贵,是高端的象征!但忽视了OLED的很多硬伤!受限于有机材料过热保护,OELD电视的峰值亮度难以突破3000nit,否则极易烧屏
热门专题







热门推荐

IT之家 3 月 27 日消息,今晚,华为 Mate80 Pura 70 等多款机型陆续推送鸿蒙 HarmonyOS 6 0 0 328 SP52 更新,沉浸光感功能下放。IT之家整理主要内容如下:

PPT交互图表核心是观众主动选择,2026年主流用触发器控制显隐、超链接实现页间跳转、Excel数据链接保障动态更新,三者均不依赖插件且兼容稳定。在PPT里做交互图表,关键不是让图

宠物相机app怎么用,打开软件,点击首页,里面提供了点击拍照、拼图、相册三个选项,点击拍摄,你可以在里对宠物进行抓拍,并且可以添加水印和滤镜。宠物相机app使用教程:1、打开软件,

《我的咸鱼卡组》战斗机制:阵容由1英雄卡和8士兵卡组成,场上5名士兵,3名候补补位,士兵全灭后可直接攻击英雄。卡牌将攻击与生命合为力量值,近战力量高但攻击会被反击,远程无反击但力量

追剧追得脸盲?别慌,这张“美人地图”直接帮你拎清谁是谁,还能偷学90年代穿搭,一举两得。先说最接地气的谭松韵。镜头里她顶着半素颜、眼圈青黑,法令纹都不遮,活脱脱一个熬夜做PPT的女老板。但仔细扒,她