马斯克开源推荐算法核心代码,自嘲虽不完美但将月更
就现在,GitHub已经能完整看到马斯克开源的推荐算法系统了。
开源文件里明确表示,这是一个几乎完全由AI模型驱动的算法系统。
我们移除了所有人工设计特征和绝大多数启发式规则。
消息一出,整个社区立刻沸腾了,最高赞上去就是一顿猛夸:
incredible!没有其他平台能做到如此透明。

马斯克本人也火速转发了工程团队原帖,不过一向言辞高调的老马,此番却低调表示:
我们知道这个算法很蠢(dumb),需要大幅改进,但至少您可以实时、透明地看到我们为改进它而努力。其他社交媒体公司都没有这样做。
早在2024年收购(原Twitter)之前,马斯克就多次批评该平台过于封闭。
自收购之后,他也兑现承诺多次公开Twitter核心推荐算法,这一次也算是不忘初心了。
原来纯AI驱动的推荐系统,是这样运作的!
话不多说,咱这就扒一扒整套系统的运作机制。
一句话概括这个系统即为:
基于Grok-1同款Transformer架构打造,能通过学习你的历史互动行为(点赞/回复/转发过什么),来决定给你推荐什么内容。
从用户打开“For You”开始,客户端会向服务器发送一个请求,触发整个算法流程。
然后系统会先做一件事——搞清楚你是谁、你最近在干什么、你平时对什么内容有反应。
为实现这一目的,系统会拉取两类用户信息:
行为序列(Action Sequence):一类代表最直接、最强烈的兴趣信号,比如最近点赞、回复、转发、点进、停留过什么。属性(Features):另一类代表长期属性,比如关注列表、声明的兴趣主题、地理位置、使用设备等。
这一步的目标并不是人工构造特征,而是尽可能真实地构建“实时用户画像”——
以前工程师可能会假设“某些属性很重要”,然后手动编写规则或公式去计算一个“用户兴趣得分”。
但这本质上是工程师的猜想,而非用户真实状态的反映。
于是马斯克的这套算法就决定不做任何预设假设,而是尽可能多地、原始地收集用户最真实的行为反应,然后将这堆数据直接喂给后续的模型,从而让模型自己去从原始数据中学习和发现规律。(即“去人工化”和“端到端”)
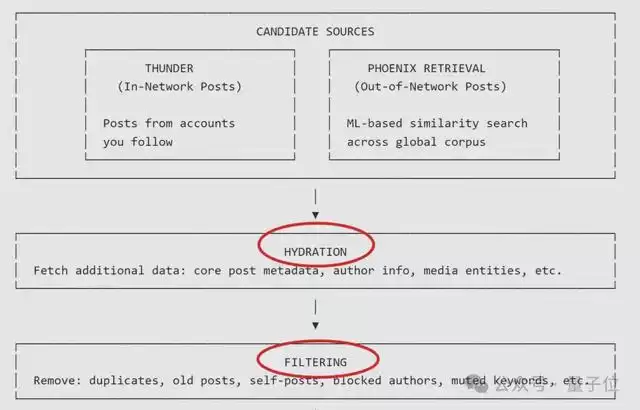
而拿到实时用户画像后,系统会接着兵分两路,从整个平台的海量推文中快速筛选出几千条“可能相关”的推文。
一条是通过熟人圈。即从Thunder模块,直接抓取你关注的所有人的最新推文。
另一条是通过外部。利用Phoenix Retrieval这一核心检索模块,抓取那些你可能感兴趣、但来自未关注账号的推文。
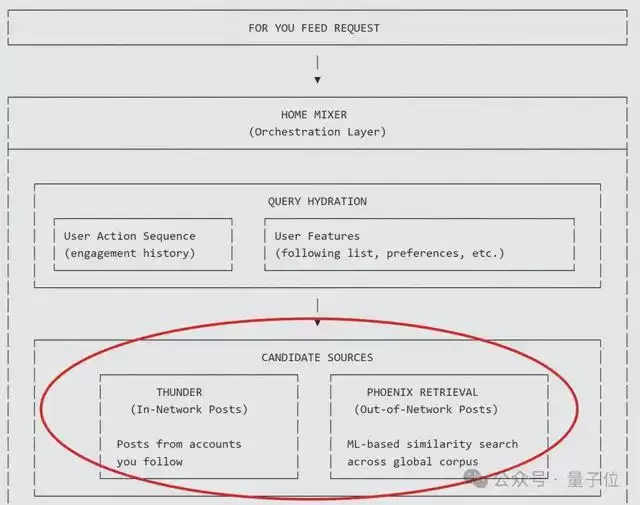
以上两类来源不同的信息,会在后续阶段被统一对待。
需要提醒,此时筛选出来的还只是推文ID。
于是系统会通过Hydration模块,补全每条候选推文的信息,包括推文全文、作者详情、图片/视频、历史互动数据等,以便后续深度评估。
而且在正式开始计算前,还会进一步通过Filtering模块淘汰那些明显不要的内容,例如:
重复或过期的帖子用户自己发布的内容来自拉黑或静音账号的帖子包含用户屏蔽关键词的内容已经看过或在当前会话中展示过的帖子用户无权限访问的订阅内容
记住,这一步只做一件事:回答某条内容“能不能出现,而不是值不值得推荐”。
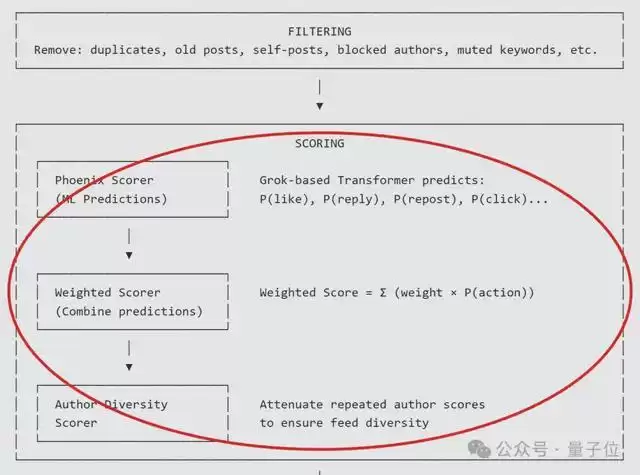
铺垫到这里,最终剩下来的内容会被逐条送入Phoenix排序模型进行打分。
这个模型是一个基于Transformer的模型,它会同时接收:
用户的行为序列与属性信息单条候选帖子的内容与作者信息
然后模型会预测用户对某条推文执行各种操作的概率,并将各种概率按照预设权重进行加权组合(如点赞类正向行为加分、拉黑类负向行为减分),并形成最终排序分数。
基于此,系统还会进行少量工程层面的调节——
比如控制作者多样性,避免单一账号在信息流中占据过高比例(防止某一大V刷屏)。
这里也需要提醒,为了保证送入的每条帖子都是独立评分的,所以系统还特意设置了“不允许候选帖子相互看见”(推文之间没有交叉注意力机制)。
所有候选帖子按最终得分排序,系统从中选出Top-K条帖子,作为本次请求的推荐结果。
而且在返回客户端之前,系统还会进行最后一轮校验,确保内容符合平台安全规范——
例如,移除任何已删除、被标记为垃圾信息或包含暴力血腥等违规内容的推文。
最终,经历重重筛选后的信息会根据分数高低,依次展示给客户端用户。

总结下来,这套系统能够成功运转的五大关键在于(最新划重点版):
(1)纯数据驱动,拒绝人工规则。
彻底摒弃人工定义“什么内容算好”的复杂规则,改由AI模型直接从原始用户数据中学习。
(2)采用候选隔离机制,独立评分。
AI模型在给内容打分时,每条内容“看不见”其他候选内容,只能看到用户信息。这确保了每条帖子的分数不会因为同批次其他帖子而变化,分数一致且可高效缓存复用。
(3)哈希嵌入,实现高效检索。
检索和排序都使用多个哈希函数进行向量嵌入查找,提高效率。
(4)预测多元行为,而非单一分数。
AI模型不直接输出一个模糊的“推荐值”,而是对多种用户行为同时预测。
(5)模块化流水线,支撑快速迭代。
整个推荐系统采用模块化设计,各个组件可以独立开发、测试、替换。
“是的,这算法太烂了”
不过,虽然众人对老马开源的姿态表达了赞赏,但奈何这套算法还是有一些“缺陷”。
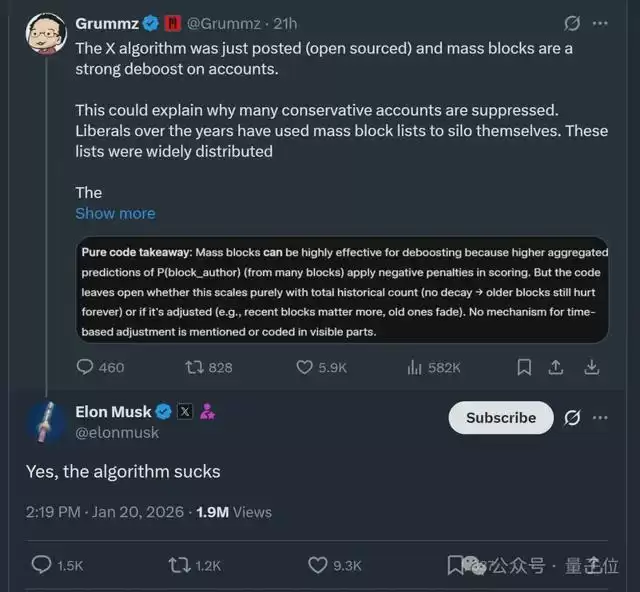
有网友就在推荐算法开源后吐槽道:
由于API访问受限且成本高昂,现在屏蔽列表的做法已经很少见了,但以前这种做法非常普遍。算法必须让较旧的屏蔽列表随着时间推移而逐渐消失,这样这些较旧的屏蔽列表就不会再被恶意利用。
言下之意是,算法代码显示“被大量用户屏蔽”是一个强负面信号,会直接导致账号被“降权”,即内容更难获得推荐,但代码中没有明确看到针对“屏蔽”信号的时间衰减机制。
这意味着,历史上的屏蔽记录可能至今仍在影响账号的推荐分数。
此番言论也引得马斯克本人现身评论区吐槽:
是的,这算法太烂了。
但不管怎样,老马想要改变的态度已经明确——
不仅过去开源、现在开源,而且接下来还会持续开源,未来每4周将重复一次开源更新。
开源仓库:
https://github.com/xai-org/x-algorithm
相关攻略

近日,开源具身智能原生框架Dexbotic宣布正式支持以RLinf作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着VLA模型研发中长期存在的「SFT与RL割裂」问题,正在被真正打通。 这是一种典型的「乐高式协作」:双方不强行Fork、不粗暴揉合代码,而是保持清晰边

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修
热门专题







热门推荐

《梦幻西游》每月“武神坛”服战流程分为报名、投票、备战与比赛四个阶段。报名于每月1日至第二周周日进行,随后是玩家投票期。第三周周三至周四为战神附体备战阶段,周四至周五完成档案复制与记者指定。正式比赛于第三周周六开始,参赛者需登录游戏传送至赛场。

潜水电梯蓝图是《深海迷航2》中建造垂直交通的关键。玩家需从初始点朝240度方向直线前进,抵达一处小型残骸营地。该营地并非主线必经,但必定产出潜水电梯蓝图。到达后可直接扫描获取蓝图,其他普通资源可忽略。

《大神绝景版》风车村隐藏着丰富支线任务,如寻找藏宝图、解开雕像谜题、调查村民失踪等。这些任务涉及解谜、探索与互动,通过完成特定条件可触发隐藏场景或剧情,让玩家深入体验村落细节与背景故事,增强沉浸感。

在《深海迷航2》开局阶段,获取石英的关键在于救生舱附近的浅海区域。玩家可向东、南或东南方向游动30至150米,寻找醒目的橙红色珊瑚穹顶。其内部固定生成石英,无需工具即可徒手采集。该区域深度适中、环境安全,同时便于顺路收集钛、铜等其他前期资源,高效满足建造需求。

开局拿到黑匣子后,建议优先解锁“消化基因”。从救生舱向正北偏东约25度方向前进150至180米,在浅海区找到发粉光的巨型植物“天使栉”。靠近其核心互动即可解锁。该被动技能能永久解决食物问题,让玩家更专注于探索与建造。