
机器之心发布
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
为什么 Claude 能 “吞下整本书”,但最新示例往往只展示几千字的文档?
为什么所有大模型厂商都在卷 “更长上下文”,而真正做落地的产品经理却天天琢磨 “怎么把用户输入变短”?
这些看似矛盾的现象,其实答案藏在一个长期被技术光环遮掩的真相里:
长序列,正在成为大模型应用里最昂贵的奢侈品
在当前主流的 Full Attention 机制下,计算开销会随着输入长度平方增长,序列一长,处理就变得 “又贵又慢”(见图 1)。针对这一核心难题,阿里 RTP-LLM 团队提出了一种全新的后训练压缩方案:RTPurbo。在不损失模型效果的前提下,实现了 Attention 计算5 倍压缩(见图 2)。
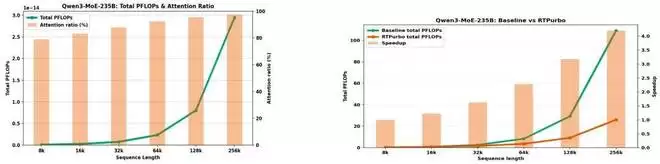
左图 1:长序列 Attention 计算成本瓶颈;右图 2:RTPurbo 极大降低 Attention 计算开销
总的来说, RTPurbo 采用了一种非侵入式的压缩方法:通过分辨 LLM 内部的长程 Attention Head,仅保留关键 Head 的全局信息,对于剩下冗余的 Head 直接丢弃远程 Tokens。这种 Headwise 级别的混合算法以其简洁的方案设计和优越的算子兼容性,极大地降低了大模型在长序列下的推理代价,为新一代 LLM 结构设计提供了一个新的视角和演进方向。
目前,项目模型与推理代码已经发布至 Huggingface、ModelScope 平台,感兴趣的读者可以阅读 RTP-LLM 相应的技术 blog 了解更多细节。
https://huggingface.co/RTP-LLM/Qwen3-Coder-30B-A3B-Instruct-RTPurbohttps://modelscope.cn/models/RTP-LLM/Qwen3-Coder-30B-A3B-Instruct-RTPurbo
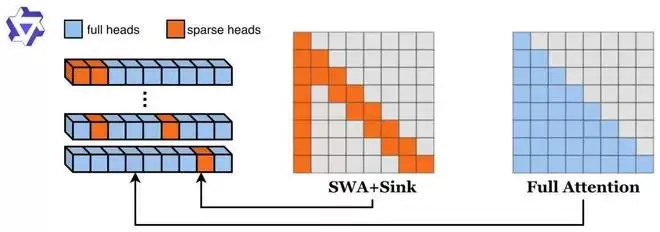
图 3:RTPurbo 采用混合压缩方案,仅有少数 Attention Head 使用全量 Attention)
化繁为简,被低估的 SWA

但在真实落地中,这两条路线都有较明显的共性代价:一方面,它们通常强依赖大量后训练,工程实现与适配成本也更高;另一方面,Linear Attention 在压缩信息后,长序列下的召回能力显著弱于 Full Attention [1],因此往往需要与 Full Attention 混合使用,带来性能与加速收益的双重上限。此外,Linear / Sparse Attention 的算子与调度设计相对复杂,也进一步影响其在工程生态中的通用性、可维护性与一致性。也正因如此,一些前期工作 [2] 反而把目光投向看似 “简单粗暴” 的 Sliding Window Attention(SWA),例如 gpt-oss 和 MiMo ,这在一定程度上说明 SWA 并非 “权宜之计”,而是一种可规模化复用的工程选择。
在进一步分析现有 LLM 的注意力模式后,团队观察到一个更细粒度的关键现象:绝大多数 Attention Head 天然更偏好局部信息,只有极少数 “长程头” 能在长文本中稳定地定位并召回关键关联信息。基于这一现象,团队提出了一个关键假设:
类似人类的阅读与写作过程,LLM 在处理长文本时,往往会先从长上下文中 “召回” 相关信息,再在相对局部的上下文范围内完成推理并输出答案
换句话说,模型内部可能只有少量 Attention Head 真正在承担 “信息召回” 的职责:它们通过注意力机制把远距离信息搬运到当前的 Residual Stream(信息通道)中,让后续层可以在更局部、更高信噪比的状态下完成推理。这也直接意味着:对于那些并不承担长程依赖的 Attention Head,其实并不需要使用 Full Attention—— 长序列场景存在可观的压缩空间。
为了验证这一假设,团队设计了一个直观的对比试验:
方案一:只有 15% 的长程头使用 Full Attention,剩余 85% 使用 SWA;方案二:15% 的长程头使用 SWA,剩余 85% 使用 Full Attention。
如表 1 所示,尽管方案二保留了 85% 的 KV cache,但是其长文能力仍然显著劣于方案一。

表 1:方案一只用 15% 的 Full Attention,长文效果显著优于方案二
进一步地,在不做任何微调的情况下,方案一在长文本指标上也非常有竞争力(表 2),几乎无损:

表 2:方案一不经过训练,在 Ruler 上无损
不过,在某些特定的长文任务上,未经微调的压缩模型仍会出现明显的性能退化(见表 3)。其根源在于:压缩前后注意力模式的直接切换会对模型输出造成一定扰动,需要额外训练来 “消化” 这种变化。

表 3:方案一在特殊 benchmark 上仍然存在显著负向
因此,为实现更接近 “无损” 的压缩,团队进一步提出了一个面向 RL 后模型的压缩训练范式:在不依赖高质量标注数据的前提下,仅通过轻量级微调,就能显著提升压缩后模型在长文任务上的表现。
自蒸馏,从根本上解决数据问题
当前主流 LLM 通常采用 “预训练 + 后训练 + RL” 的训练范式,如果直接使用长文 SFT / 预训练语料进行续训,会带来两方面挑战:
RL 后模型在经过 SFT 会出现过拟合甚至灾难性遗忘,损伤短文本任务上的原有能力(见表 4);高质量的长文本语料难以获取。

表 4:Qwen3-30B-A3B-Instruct RL 后模型继续 SFT 会过拟合,造成灾难性遗忘
为解决这两点,RTPurbo 使用 “模型自蒸馏” 作为关键训练策略:让压缩后的模型对齐原模型输出,从而同时化解数据与能力保留问题:
仅对模型自身的输出进行对齐,避免依赖特定领域的问答数据,从而确保短文本下游指标基本无损;只需使用长文本预训练语料即可完成训练,使模型快速适应 headwise 稀疏的工作模式。
实测中,仅使用约 1 万条 32k 长度的预训练语料(训练时间小时级),RTPurbo 就能让长文任务表现与原模型持平。
结果对比
在长文本测试场景下,RTPurbo 仅保留约 15% 的 Attention Heads 使用 Full KV cache,压缩后的 Qwen-Coder-Plus、Qwen3-30B-A3B-Instruct 在多项长文指标上可与未压缩模型齐平,充分验证了压缩后模型的精度保障。
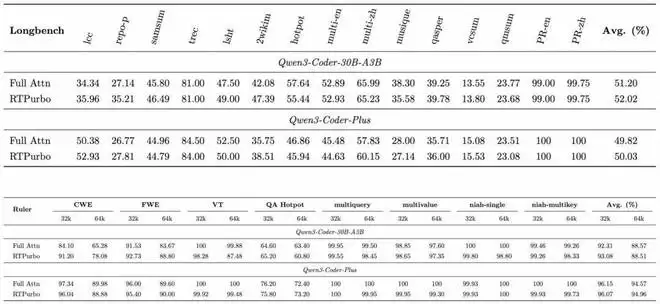
更重要的是,这种压缩并非以牺牲通用能力为代价。在多项短文本(通用)Benchmark 上,采用自蒸馏范式训练后的模型并未出现性能衰减,原有对话、推理和代码理解等能力都得到了良好保留。
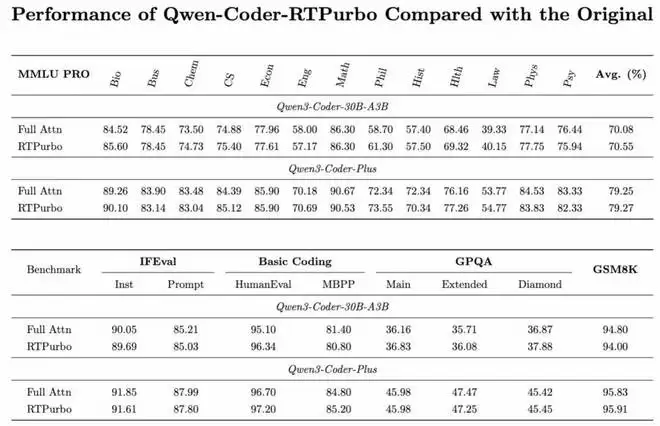
这表明,RTPurbo 不仅是一种单一模型的 “特定优化技巧”,而是一套具有良好可迁移性和通用性的长序列加速方案,可为更大规模、更多架构的 LLM 提供高性价比的推理加速路径。
从大模型可解释性到 LLM 压缩
早期可解释性工作 [3] 已指出:模型内部存在很强的 “召回” 机制,一部分特定 Attention Head 能稳定定位前文相关信息。团队成员的前期工作 [2] 也观察到这些 Head 在长文场景仍保持类似行为。
与此同时,在 [4] 中,作者指出 Softmax 本身在长序列存在熵增的问题。更具体的,随着序列变长,每个 Token 的注意力不可避免的变得更加弥散(信噪比降低),如下图所示:
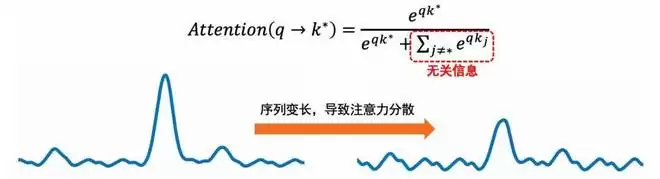
图 4:Attention 在长序列下存在信噪比下降的问题
因此,为了避免远程信息干扰模型本身的推理能力,LLM 内部实现了一种非常巧妙的机制:
多数 Head 只处理局部信息,以获得更高信噪比;少数 Head 负责从远处 “召回” 关键信息并搬运到当前位置,使后续层能在局部范围内完成推理。
这与 RTPurbo 的 headwise 设计高度一致:把 “全局召回” 能力集中保留给少量关键 Head,其余 Head 则用工程收益更稳定的 SWA 来承载。
RTP-LLM:RTPurbo 在长文上的极致性能优化
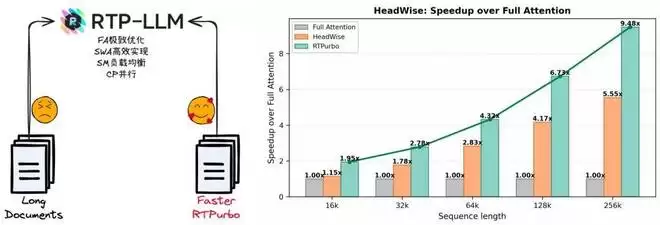
图 5:RTPurbo HeadWise Attention 性能加速结果,图上结果仅使用 15% 的 Full Attention
RTPurbo 按固定比例划分 SWA Head 与 Full Head 虽然直观有效,但工程上必须解决一个问题:不同 Head 计算模式与计算量不一致,会导致负载不均衡,影响 GPU 并行效率与端到端吞吐。
为此,RTP-LLM 围绕该不均衡在算子层与框架层做了针对性优化,核心包括:
Full Attention Head 的 PTX 级优化:对仍需全量计算的 Full Head 深入 PTX 指令层,利用 gmma::mma_async_shmA 等异步拷贝与矩阵乘指令提升效率;融合 IO warps 与 P/V 计算阶段,优化 Ping-Pong 流水与调度,减少空转等待。稀疏度感知的负载均衡调度:针对 Tail Latency,采用稀疏度感知动态调度(如反向拓扑排序),优先分配重 tile 给 SM,使各 SM 更同步完成任务,降低尾延迟、提升吞吐。SWA 的高效实现:避免传统 SWA 常见的 “三段式 KV 拼接” 或 “Custom Mask” 做法(访存与调度开销大),通过重塑数据布局与计算路径减少冗余访存与额外算子开销。用 CP(Context Parallel)替代 TP(Tensor Parallel):在 headwise 稀疏场景下,TP 易导致算力利用率低且不够灵活;采用 CP 让单卡完成全部 head 的 attention 计算,提高 GPU 利用率,并通过计算 - 通信重叠降低通信开销。
综合以上优化,RTP-LLM 能将 Attention 稀疏带来的理论收益稳定、可复现地转化为端到端加速;在 256k 长序列下实现单算子最高 9× 加速(见图 5,图中仅 15% Head 使用 Full Attention)。
团队介绍
RTP-LLM 是阿里巴巴智能引擎团队自研的高性能大模型推理引擎,支持了淘宝、天猫、高德、饿了么等核心业务的大模型推理需求。智能引擎源自阿里巴巴搜索、推荐和广告技术,是阿里 AI 工程领域的先行者和深耕者。团队专注于 AI 工程系统的建设,主导建立了大数据 AI 工程体系 AI・OS,持续为阿里集团各业务提供高质量的 AI 工程服务。
RTP-LLM 项目已开源,欢迎交流共建: https://github.com/alibaba/rtp-llm
参考文献:
[1]: Repeat After Me:Transformers are Better than State Space Models at Copying.
[2]: RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
[3]: In-context Learning and Induction Heads
[4]: 苏建林,“注意力机制真的可以集中注意力吗?”,https://www.spaces.ac.cn/archives/9889