Mamba团队SonicMoE:新增1个Token,MoE训练速度提升近2倍

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
机器之心编辑部
混合专家(MoE)模型已成为在不显著增加计算成本的情况下,实现语言模型规模化扩展的事实标准架构。
近期 MoE 模型展现出明显的高专家粒度(更小的专家中间层维度)和高稀疏性(在专家总数增加的情况下保持激活专家数不变)的趋势,这提升了单位 FLOPs 的模型质量。
这一趋势在近期的开源模型中表现尤为明显,例如 DeepSeek V3、Kimi K2 以及 Qwen3 MoE 等,它们均采用了更细粒度的专家设计(更小的中间层维度)和更高的稀疏度,在保持激活参数量不变的同时大幅增加了总参数量。
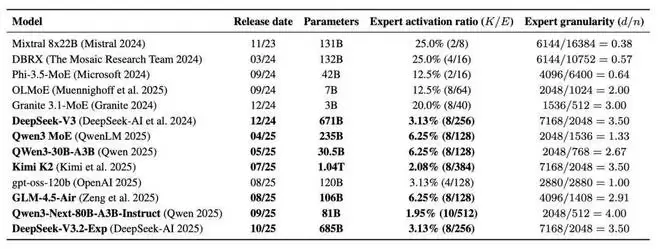
表 1:MoE 扩展趋势:在此,团队将激活率展示为每个 Token 激活的专家数 K / 专家总数 E;针对前沿开源模型,专家粒度展示为模型嵌入维度(d)/ 专家中间层大小(n)。在 MoE 稀疏度计算中未包含共享专家。趋势表明,新的开源 MoE 模型倾向于具备更高的粒度和稀疏度。
然而,这种追求极致粒度和稀疏性的设计导致了严重的硬件效率下降问题:
内存墙瓶颈:对于细粒度 MoE,激活内存的占用量通常随激活专家数量线性增长,导致前向和反向传播中的内存压力剧增。IO 瓶颈:由于专家变得更小且更分散,算术强度(Arithmetic Intensity,即计算量与数据传输量的比值)显著降低,IO 访问变得更加动态和频繁,导致模型训练进入「内存受限」区间。计算浪费:在高稀疏性场景下,由于 Grouped GEMM(分组通用矩阵乘法)内核中的 Tile 量化效应,输入数据往往需要进行填充以对齐硬件 Tile 大小,这直接导致了计算资源的浪费。
针对这些问题,普林斯顿大学助理教授 Tri Dao(Mamba、FlashAttention 的核心作者)团队提出了一套名为 SonicMoE 的系统性解决方案。该方案专为 NVIDIA Hopper 和 Blackwell 架构 GPU 量身定制,其核心贡献包括:
内存高效算法:团队通过重新设计 MoE 的计算图,提出了一种在计算路由梯度时不缓存激活值的方法。该方法在保持与原始 MoE 公式数学等价的前提下,大幅减少了反向传播所需的激活显存。对于细粒度 7B MoE 模型,每层的激活内存占用减少了 45%,且随着专家粒度的增加,其内存占用保持恒定,效率比现有基线高出 0.20-1.59 倍。计算与 IO 重叠:利用 Hopper 架构 GPU 的 WGMMA 指令与生产者 - 消费者异步范式,SonicMoE 设计了新型 GPU 内核。该内核能够将 GEMM 计算与从 HBM 加载数据的 IO 操作并行执行,有效掩盖了细粒度 MoE 带来的高昂 IO 延迟。Token 舍入:这是一种即插即用的创新调度策略。它将分发给每个专家的 Token 数量四舍五入为 Grouped GEMM Tile 大小(例如 128)的倍数。算法保证每个专家的偏差最多仅为一个 Tile,从而在期望意义下保持总 token 数不变。这一策略有效减少了因填充导致的算力浪费。
实验数据有力地证明了 SonicMoE 的性能优势,在针对细粒度 7B MoE 模型的测试中:前向传播相比高度优化的 DeepGEMM 基线,速度提升43%;反向传播相比最先进的 ScatterMoE 和 MoMoE 基线,速度分别提升了 83% 和 115%;端到端训练仅依靠内核优化即可将训练吞吐量提升 50%,若配合 Token 舍入路由,在扩展专家数量时可进一步获得 16% 的额外吞吐量提升。

论文标题:SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations论文地址:https://arxiv.org/abs/2512.14080
更直观地看,团队仅使用 64 台 H100 运行 SonicMoE,便实现了每日 2130 亿 token 的训练吞吐量,这一表现已能与使用 96 台 H100 运行 ScatterMoE 的效率相媲美。此外,在高稀疏性场景下(如 1.4B 参数模型),其 Tile 感知的 Token 舍入算法在验证了不损失下游任务精度(如在 2B 规模上的推理质量)的同时,显著提升了内核执行速度。
目前,团队已将相关内核代码开源,为大模型社区加速高性能 MoE 训练提供了强有力的工具。
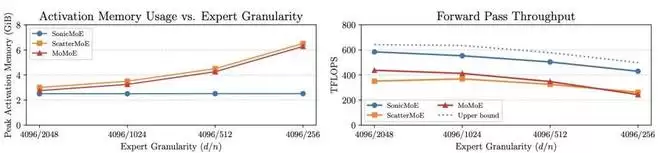
图 1: 即使专家粒度(d/n,其中 d 为嵌入维度,n 为专家中间维度)增加,SonicMoE 的每层激活显存占用(左图)仍保持恒定;相比其他基线,其显存效率提升了 0.20 倍至 1.59 倍。SonicMoE 的前向计算吞吐量(右图)平均达到了理论上限的 88%(最高 91%,最低 86%),该上限基于 H100 GPU 上的 「cuBLAS BMM + 激活函数 + cuBLAS BMM + 聚合操作」 计算得出。请注意,cuBLAS 上限基线未包含路由计算部分。在此,我们使用的是 30B 参数量的 MoE 配置,微批次大小为 32768 个 token,并且从左至右依次将「激活专家数 / 总专家数」设置为 2/32、4/64、8/128 和 16/256。
内存高效的 MoE 算法

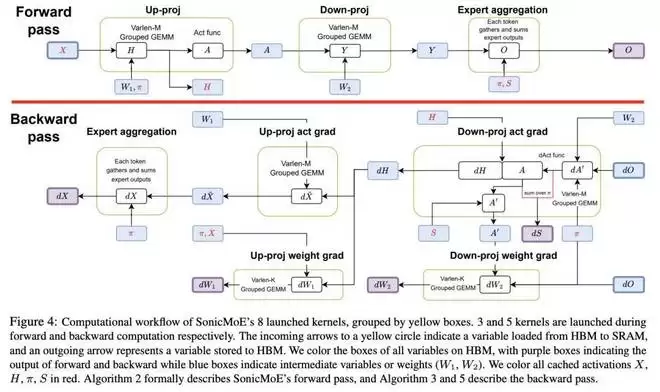
团队提供了一个高效的基于 Tensor Core 的 top-K 路由,以及一个可以接受任意路由输入的接口。但需要注意的是,SonicMoE 的 MoE 计算与路由的选择无关,因此与任意路由逻辑兼容。
SonicMoE 的 MoE 计算实现具有高度模块化特性,仅由以下两部分组成:
经过优化的分组 GEMM 内核(带有模块化融合)经过优化的专家聚合内核
主机会根据最佳 GEMM 配置和加载 / 存储策略来调度并启动上述 8 个内核。
结果显示,尽管采用了如此高度的模块化设计,SonicMoE 仍然展现出业界领先的训练吞吐量和最低的激活内存使用量。
面向 IO 的内核设计
细粒度 MoE 的表达能力来自于每个 token 在专家选择上的多样性,但这种多样性同时带来了与专家粒度线性增长的 IO 开销,为了保持高吞吐,需要尽可能做到:
通过融合(fusion)减少 IO 访问将 IO 延迟与计算重叠
在融合这一块有两种方式,一是利用 HBM 加载进行 Gather 融合。SonicMoE 的 Grouped GEMM 既可以接受连续打包的输入,也可以接受从不同位置 gather 得到的输入。对于第二种情况,团队将输入 gather 与从全局显存(GMEM,通常是 HBM)到共享内存(SMEM)的加载过程进行融合,从而能够将这些数据批量化,利用 Tensor Core 执行 GEMM。
这一过程包括两个步骤:
获取每个 expert 对应的被路由 token 的索引;使用这些索引,通过 Blackwell 和 Hopper 架构的 cp.async 指令,从 HBM gather 激活值。
二是 Epilogue 融合,通过以下设计充分利用 epilogue 计算,以最大化减少不必要的 IO 访问:将 SwiGLU 以及 SwiGLU 的反向(dSwiGLU),分别与前向 up-proj 内核的 epilogue、反向 down-proj 激活梯度内核的 epilogue 进行融合;在反向 down-proj 激活梯度(dH)内核的 epilogue 中计算 dH 和 dS。
结果显示,这种「重量级 epilogue 融合」使 SonicMoE 相比其他方案获得显著加速。
Token rounding 路由方法
团队在分析稀疏 MoE 训练模式下的硬件效率时发现,随着 MoE 变得更加稀疏,因填充而产生的 GEMM tile 计算浪费会累计到不可忽略的程度,这被称为「tile 量化效应」。为此,团队提出路由方法「token rounding」来消除这种效应,从而实现更高效的训练。
Token rounding 算法首先计算基础的 TC(token-choice)路由结果,并对每个 expert 对应的 token 按路由分数进行排序,之后在第二步排序中选择:要么丢弃第一步 TC top-K 选择中的部分 token,要么在第二步排序中为某些 expert 补齐额外的 token(填充)。

过程中,团队会对路由权重矩阵进行处理,使得 TC 选中的 token 始终优先于 EC token。结果就是,无论是丢弃还是填充,都只会影响每个 expert 的最后一个输入 tile。
实验表明,这种方法在实现更高训练吞吐量的同时,并不会影响模型质量。
更多内容,可查看论文获悉!
相关攻略

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修

Discord接入:让OpenClaw成为你的社区智能管家 对于全球数亿的游戏玩家和社群爱好者来说,Discord几乎等同于线上“大本营”。那么,有没有可能让你精心搭建的Discord服务器也拥有一个聪明能干的AI助手呢?答案是完全可行。通过创建Discord Bot(机器人),你可以将OpenCl
热门专题







热门推荐

峡谷区域唯一唱片需集齐三个碎片合成。首个碎片位于地图西北角木箱木桶旁,外观如跳动火焰。集齐碎片可解锁新内容并提升游戏体验,探索时留意细节可能发现更多隐藏惊喜。

《遥遥西土》中,西土唱片需集齐三个碎片合成。首个碎片位于地图东南角的管子洞内,获取过程简单,无复杂谜题或战斗。整体流程清晰,玩家按指引收集全部碎片即可合成唱片,轻松完成收集任务。

《鸣潮》联动《赛博朋克:边缘行者》,推出五星角色露西与丽贝卡,可通过限定卡池与活动免费获取。联动包含专属剧情、夜之城风格场景及高难度BOSS战,并植入动画经典音乐。参与预热活动和完成剧情任务可获得限定奖励,全方位打造沉浸式赛博朋克体验。

鼻噶流”玩法围绕“混沌爪牙”基因展开,开局以小体型角色灵活发育,注重走位与策略而非堆叠体型与伤害。该玩法在较高难度下提供了与传统平推思路不同的趣味体验,适合追求新鲜操作感的玩家尝试。

《异环》S级气态弧盘“好狗狗走四方”可提升充能与全队攻击,适合早雾等辅助。完成主线任务“成交?成交!”后解锁番外副本“月光当铺”,首次击败BOSS墨菲克斯即可免费获取。战斗时建议中距离拉扯,优先清理小狼,搭配破韧与输出角色更易通关。