谷歌180组实验揭示Scaling Law,颠覆传统模型炼金术

机器之心报道
编辑:Panda
智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。
尽管其已被广泛采用,但决定其性能的原则仍未被充分探索,导致从业者只能依赖启发式经验,而非有原理依托的设计选择。
现在,谷歌的一篇新论文填补了这一空白!
他们通过大量实验找到了智能体的 Scaling Law,只不过他们将其称为quantitative scaling principles,即定量扩展原则。

论文标题:Towards a Science of Scaling Agent Systems论文地址:https://arxiv.org/abs/2512.08296
具体来说,他们将这种扩展定义为智能体数量、协作结构、模型能力和任务属性之间的相互作用。
他们在四个不同的基准测试中对此进行了评估:Finance-Agent(金融推理)、BrowseComp-Plus(网络导航)、PlanCraft(游戏规划)和 Workbench(工作流执行)。
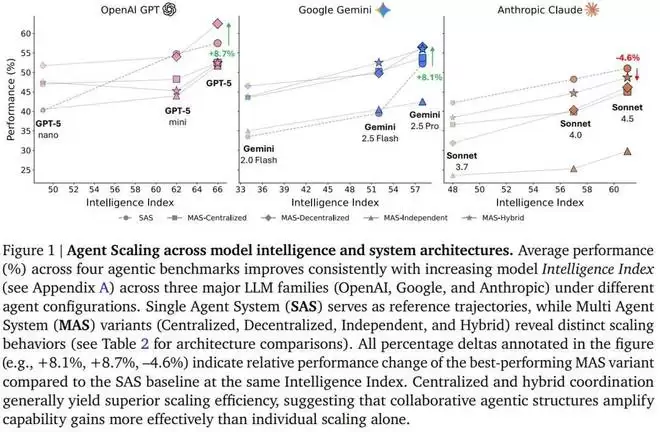
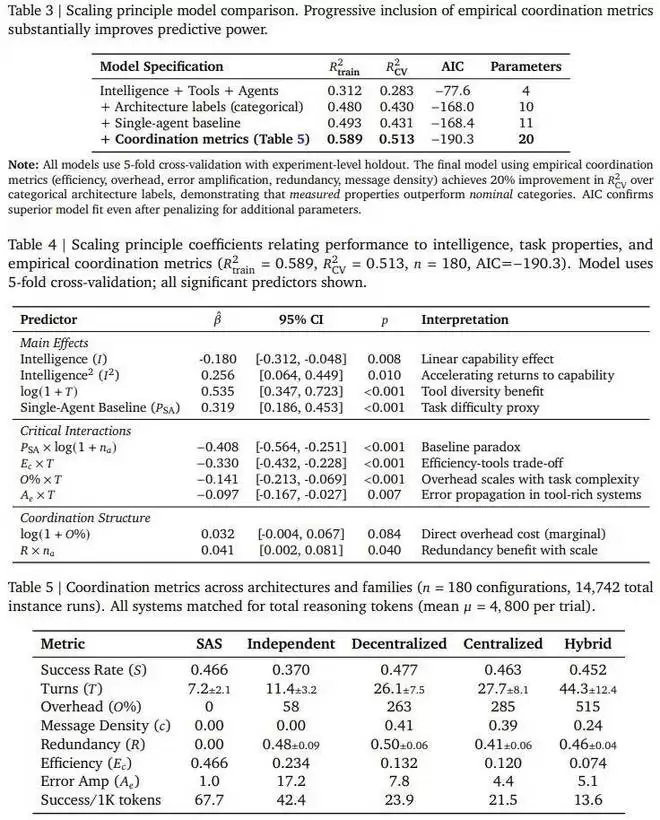
利用五种典型的智能体架构(单智能体系统以及四种多智能体系统:独立型、中心化、去中心化、混合型),并在三个 LLM 家族(OpenAI, Google, Anthropic)中进行实例化,谷歌这个团队对 180 种配置进行了受控评估,标准化了工具、提示结构和 token 预算,以将架构效应从实施混杂因素中隔离出来。

他们使用经验性的协作指标(包括效率、开销、错误放大和冗余)推导出了一个预测模型,该模型实现了交叉验证 R²=0.513,通过对任务属性建模而非过度拟合特定数据集,实现了对未见任务领域的预测。
是的,智能体的 Scaling Law 找到了!并且准确度还相当高,谷歌表示:「我们的框架在预测保留任务的最佳架构方面实现了 87% 的准确率。」这样一来,智能体的部署决策将第一次获得强有力的原则支撑。
实验与结果:打破「人多力量大」的迷思
为了找到这套定量原则,谷歌团队没有仅仅停留在理论推导,而是进行了一场堪称暴力穷举的实证研究。
他们动用了三大模型家族(Google Gemini、OpenAI GPT、Anthropic Claude),在金融、网购、游戏规划等不同场景下进行了 180 组受控实验。
实验结果不仅令人意外,甚至颠覆了许多开发者的直觉。简单来说,他们发现了一些规律。
任务决定成败:有的场景是神助攻,有的是猪队友
过去人们常说「三个臭皮匠,顶个诸葛亮」,但这篇论文告诉我们:这完全取决于你们在干什么任务。
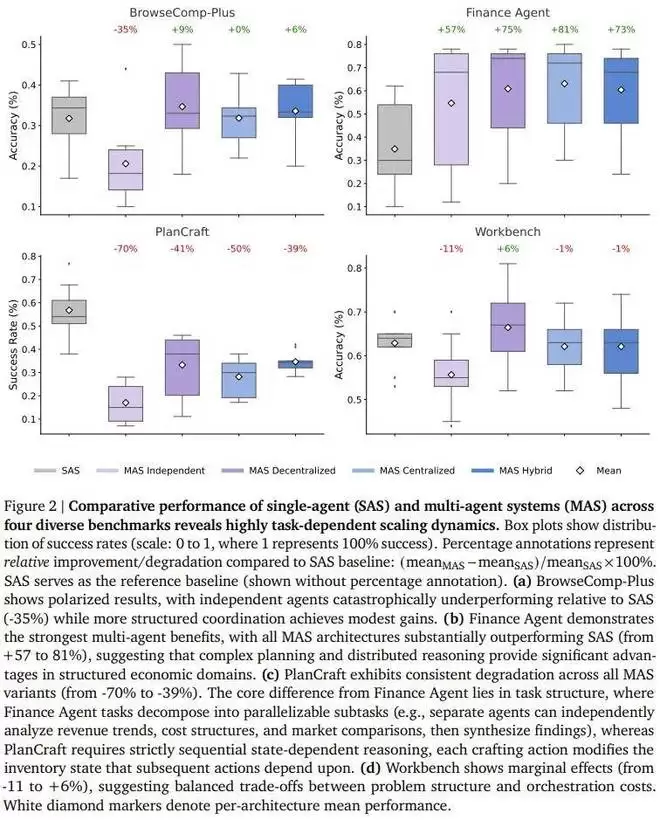
红榜(适合组团): 在金融分析(Finance-Agent)这类任务中,多智能体协作是大杀器。中心化架构(有一个「指挥官」分派任务)能让性能暴涨 80.9%。为什么?因为这类任务可以拆分 —— 你查财报,我算汇率,他做总结,大家并行工作,效率极高。
黑榜(切忌组团): 在游戏规划(PlanCraft)这类任务中,所有多智能体架构都翻车了,性能惨跌 39% 到 70%。原因在于这类任务环环相扣(必须先砍树,才能做木板),强行把流程拆给不同的人,光是沟通成本就把推理能力消耗殆尽了。
三大隐形杀手:什么在阻碍智能体变强?
通过对数据的深度挖掘,谷歌团队量化了阻碍智能体扩展的三大核心因素:
第一,工具越多,协作越难(工具-协作权衡)
如果任务需要用到大量工具(比如 16 个以上的 API),再引入多智能体协作就是一场灾难。实验数据显示,工具密集的任务会因巨大的沟通开销而不仅没变快,反而变慢、变笨。
第二,能力有天花板(能力饱和效应)
这是最反直觉的一点:如果单个智能体已经够聪明了,就别再给它找帮手了。 数据表明,当单智能体的基线准确率超过 45% 时,再增加智能体进行协作,收益往往是负的。所谓「帮倒忙」,在 AI 世界里是真实存在的。
第三,没有指挥官,错误会指数级放大
如果你让一群智能体各自为战(独立型架构),错误会被放大 17.2 倍 —— 因为没人检查,一个人的错会传给所有人。但如果引入一个「指挥官」进行中心化管理,错误放大率能被控制在 4.4 倍。这证明了在多智能体系统中,架构设计比单纯堆人数更重要。
模型性格测试:谁是最佳指挥官?
除了任务和架构,论文还发现了一个有趣的现象:不同厂商的模型有不同的协作性格。在选择团队成员时,你不能只看智商(IQ),还要看它们合不合群。
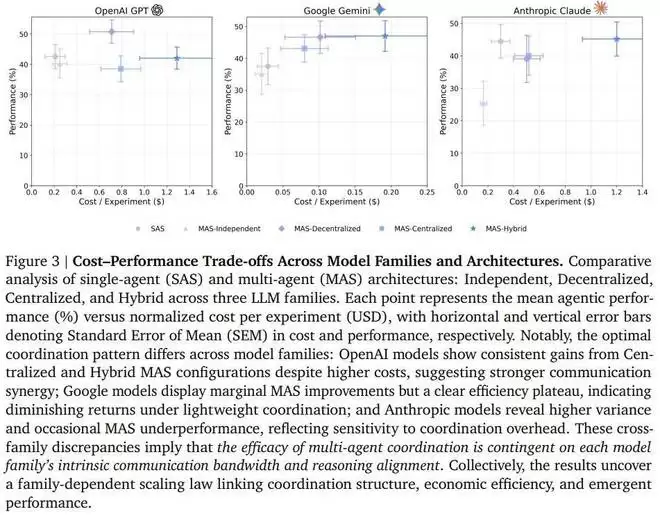
Google Gemini:擅长「层级管理」的执行官。Gemini 模型在中心化架构下表现出了惊人的适应性。在金融任务中,Gemini 的中心化协作带来了 +164.3% 的恐怖提升。数据表明,它最听指挥,执行力最强,且在不同架构下的性价比最为平衡。
OpenAI GPT:擅长「复杂沟通」的交际花。GPT 系列在混合型架构(Hybrid)中表现最佳 。虽然混合架构的沟通成本很高,但 GPT 似乎拥有独特的「通信协同效应」(Communication Synergy),能驾驭复杂的交互网络,不仅能听指挥,还能搞定同级之间的横向沟通 。
Anthropic Claude:稳健但敏感的保守派。Claude 对协作开销非常敏感,一旦沟通太复杂,成本就会飙升(每提升 1% 性能的成本是 Google 的 2 倍)。因此,它最适合简单直接的中心化架构,表现最稳(方差最小)。更有趣的是,它是唯一一个在「弱指挥官带强兵」(异构混合)模式下还能提升性能的模型,展现出了独特的容错性
结果:这就是我们要找的「预测公式」
最终,基于上述发现,谷歌推导出了一个预测模型。这个模型不依赖玄学,而是基于效率、开销、错误放大率等硬指标。
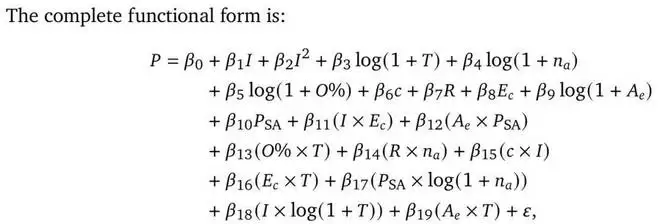
它的威力如何?在预测完全没见过的任务配置时,这套理论能以 87% 的准确率告诉你:对于当前的任务和模型,到底该用单打独斗,还是团队协作,亦或是某种特定的组队方式。
这标志着智能体系统设计正式告别了「炼金术」时代,进入了可计算、可预测的「化学」时代。
更多详情请访问原论文。
相关攻略

近日,Anthropic发布了一项关于Claude模型内部“情绪机制”的新研究,却因未引用关键的前期工作而引发学术争议。原作者直接指出这一疏漏,促使Anthropic迅速回应并更新了论文引用。 发现这一问题的研究者是来自MBZUAI的研究生Chenxi Wang。她在阅读论文后敏锐地察觉到,这项研究

中国航天员科研训练中心招募卧床实验志愿者,需卧床最长60天以模拟失重环境,研究生理变化。参与者需符合健康及心理标准,实验过程伴随不适但受严密监控。数据对航天医学与老年病学有重要价值,志愿者可获得补助及交通报销。

“我能再说几句吗?” 在复旦大学相辉堂举行的“浦江科学大师讲坛”互动环节结束后,2024年诺贝尔物理学奖得主安妮·吕利耶教授主动提出了这个请求。她分享了一个温暖的观察:“我曾受邀在各种场合做过演讲,很多时候提问的都是男性,但这次几乎都是女性在提问题,请大家坚持下去。”作为第五位获得诺贝尔物理学奖的女

你还在一个人做科研吗? 科研路上最磨人的,往往不是问题本身,而是那种彻头彻尾的“孤军奋战”感。一个想法,从文献调研到实验设计,再到落笔成文,每一步都只能靠自己摸索着前行。 方向偏了,没人及时提醒;遇到歧义,找不到人讨论;结果不对,就只能陷入反复试错的循环。市面上不少所谓的“自动化科研”工具,其实只是

Claw AI Lab团队量子位 | 公众号 QbitAI你还在一个人做科研吗?科研最难的,从来不是问题本身,而是一个想法从文献到实验再到写作,只能靠自己一点点往前推。一个人方向偏了没人提醒,遇到歧
热门专题







热门推荐

美股指数期货短线拉升,标普500指数期货上涨0 4%,道指期货与纳指期货亦同步上扬。市场情绪受积极经济数据及企业财报提振,投资者关注后续政策动向与经济走势。


5月22日,贝莱德向Coinbase转移了1587枚比特币和17815枚以太坊,总价值约1 6亿美元。市场推测此举可能与其现货比特币ETF的流动性准备有关,或是机构资产配置的常规操作。大额链上转移反映了传统金融机构正深度参与加密市场,其动向持续影响市场观察与定价逻辑。

加密货币市场反弹:是牛市的序曲,还是又一次技术性修复? 在经历了一轮剧烈的震荡与回调之后,加密货币市场近期迎来了久违的普涨。比特币、以太坊和瑞波币领跑反弹,其亮眼表现不禁让市场参与者们再次发问:这究竟是新一轮牛市的起点,还是仅仅是一次技术性的超跌反弹? 一、市场反弹的核心驱动力 那么,推动这轮反弹行

《一梦江湖》新头挂“应缨鹦”造型灵动可爱。小鹦鹉大眼睛、精巧小嘴,扑扇翅膀,姿态欢快。它时而好奇张望,时而对镜摆姿,活灵活现,为佩戴者增添生动俏皮的趣味。