机器之心发布
机器之心编辑部
随着大模型推理与智能体(Agent)工具调用能力的飞速发展,其处理复杂信息需求与深度搜索任务的效能日益受到业界瞩目。近日,国内第三方评测机构 SuperCLUE 发布了十一月份的 DeepSearch(深度搜索)专项评估报告。国产大模型 openPangu-R-72B 凭借在长链推理与复杂信息检索领域的卓越表现,荣登该榜单首位,充分展现了基于国产昇腾算力平台的大模型研发实力。
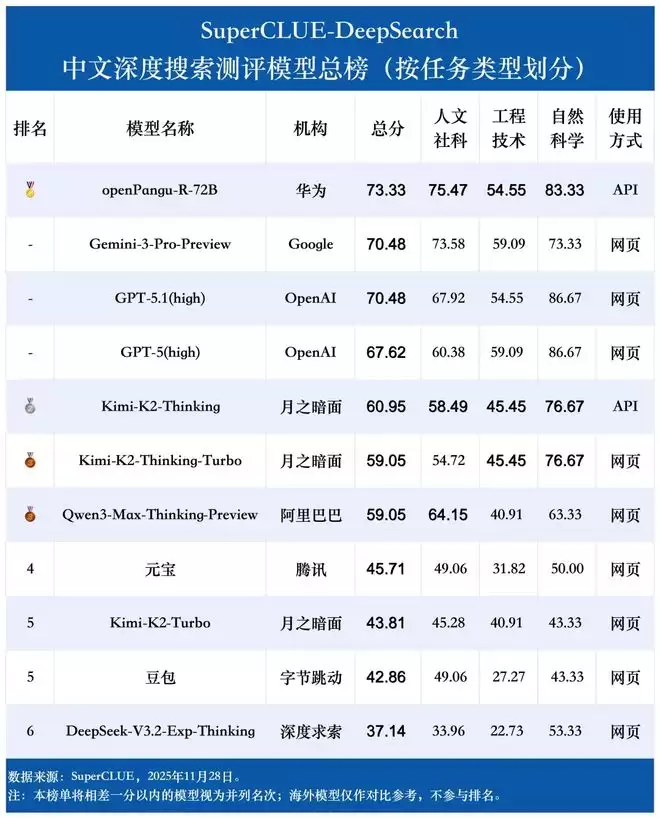
这款采用混合专家(MoE)架构的模型,究竟蕴藏着怎样的技术秘诀,使其能在激烈的竞争中脱颖而出?
硬核技术底座:
MoE 架构下的效率与性能平衡术
openPangu-R-72B 为兼顾效率与性能,创新性地重构了模型底层架构。作为基于昇腾集群训练的混合专家(MoE)模型,它采用“80选8”的专家选择机制,在高达740亿总参数量的基础上,将激活参数量控制在约150亿。此举既保留了大模型的复杂推理能力,又有效降低了计算开销。其使用了高达24万亿 tokens的训练数据,并具备128k的长序列处理能力,这为模型处理深度搜索任务中的长文本信息奠定了坚实基础。
为实现稳定收敛与效果提升,openPangu 团队在预训练技术上进行了深度优化:
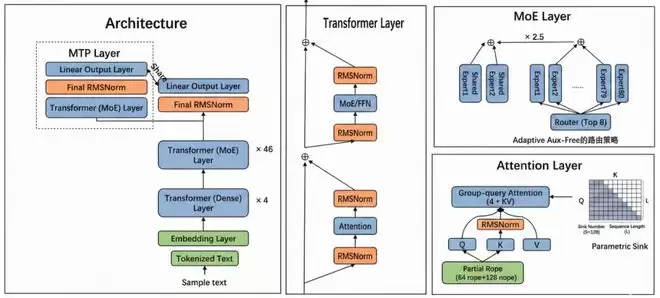
图: openPangu-R-72B 模型架构
1)注意力机制层面引入参数化 Sink Token 技术:有效缓解了训练过程中可能出现的极大激活值问题,不仅提升了训练稳定性,也使得模型后续的量化部署更加友好。
2)采用 K-Norm 与深度缩放的 Sandwich-Norm 组合架构:其中 K-Norm 仅对注意力机制中的 key 施加 RMS 归一化。此举在达到与 QK-Norm 相当稳定性的同时,降低了计算开销,还保留了 Query 向量更灵活的表达能力。
3)注意力架构的优化兼顾了精度与效率:通过增加注意力头数和头维度,让模型能从更多角度捕获细粒度语义关系;引入部分旋转位置编码(Partial RoPE)机制,仅对 Query 和 Key 中三分之一的维度应用位置编码。通过将 KV 分组数量减半,在 Key 头维度增加的情况下,依然实现了 37.5% 的 KV 缓存缩减,有效平衡了推理阶段的显存占用、速度与模型效果。
4)自适应负载均衡技术(Adaptive Aux Free):这是 Aux Free 技术的升级版本,通过自适应地调整各个专家负载偏置(bias)的更新幅度,有效减少了负载均衡震荡,使得专家负载分布更加均匀稳定。
DeepSearch 专项突破:
三大优化破解复杂搜索难题
如果说技术底座是基础,那么针对深度搜索任务的后训练优化,则是 openPangu-R-72B 此次登顶的关键。深度搜索作为大模型访问互联网获取深度信息的核心能力,其长链推理与工具调用水平直接决定了模型的实用价值。openPangu-R-72B 通过后训练阶段进行长链难题合成、非索引信息处理和快慢思考融合三大策略,显著提升了模型的深度搜索(DeepSearch)能力。
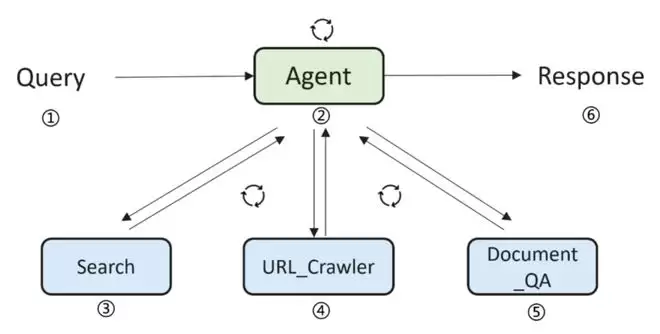
图:openPangu-R-72B 模型深度搜索任务执行流程,该流程同时用于模型训练和评测
1)在长链问答难题合成方面,openPangu 团队在 DeepDiver-V2 和 WebExplorer 技术基础上,通过问题条件模糊化将问题平均难度提升10%。同时,借鉴了《Pushing Test-Time Scaling Limits of Deep Search with Asymmetric Verification》工作的思想,引入验证智能体(verification agent),大幅提升用于训练问答数据的准确性,让模型在复杂推理场景中能够“见多识广”。
2)针对传统搜索引擎难以覆盖的非索引知识问答场景——如正式附件中的财务数据、学术论文的引文信息提取等,模型训练过程中注入了“规划器聚焦关键URL + URL爬虫抓取网页 + 文档问答识别下一步浏览链接”的循环工作流。通过同一站点内的多跳浏览实现了深度信息搜集,突破了传统搜索引擎的信息边界。
3)步骤级快慢融合策略则让模型的“思考”更具效率。深度搜索的执行过程中,不同步骤的思考强度需求差异显著——文档问答需要分析海量网页数据与表格,对推理精度要求更高;而普通工具调用步骤更侧重效率。为此,模型为不同步骤匹配不同思考模式:文档问答启用慢思考模式以保障精度,其他步骤则采用快思考模式提升速度,实现了精度与效率的平衡。
国产算力赋能:
openPangu 系列模型彰显集群优势
此次在 SuperCLUE DeepSearch 评测中登顶,不仅是 openPangu-R-72B 模型能力的体现,也彰显了国产算力与大模型研发深度融合的成效。作为基于昇腾集群训练的代表性模型,openPangu-R-72B 证明了国产算力平台在支撑大参数量、高复杂度模型研发方面的坚实能力。
值得关注的是,openPangu-R-72B 的兄弟模型 openPangu-718B 在同期的 SuperCLUE 通用能力榜单中斩获了第二名,展现了该系列在不同任务场景下的全面实力。从深度搜索的“单点突破”到通用能力的“全面开花”,openPangu 系列正以昇腾算力为基础,为我国大模型生态注入更多活力。
随着大模型在企业服务、学术研究、政务处理等领域的深度落地,深度搜索能力将成为模型实用化的核心竞争力。未来,随着 openPangu 系列模型的持续迭代,我们期待国产大模型在更多全球顶级评测中绽放光彩。