
新智元报道
编辑:元宇
【新智元导读】Prime Intellect发布的INTELLECT-3,在数学、代码等多项基准测试中取得同规模最强表现。该模型旨在将训练前沿模型的技术栈开放给社区,推动大规模RL研究的普及与发展。
最近,Prime Intellect正式发布了INTELLECT-3。
这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。
在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
Prime Intellect已经把完整的训练流程——包括模型权重、训练框架、数据集、RL环境和评测体系——全部开源,希望能推动更多关于大规模强化学习的开放研究。
INTELLECT-3使用的训练软件与基础设施,与即将在Prime Intellect平台向所有人开放的版本完全一致。
这意味着未来每个人、每家公司都能拥有对最先进模型进行后训练的能力。
多项基准,斩获SOTA
INTELLECT-3是一个106B参数的Mixture-of-Experts(MoE)模型,基于GLM 4.5 Air进行了监督微调(SFT)和强化学习训练。
它在数学、代码、科学和推理类Benchmark上均取得了同体量中的最强表现。

训练框架
训练中,Prime Intellect使用了以下核心组件:
PRIME-RL:自研的分布式RL框架,支持监督微调和大规模MoE模型的强化学习。
Verifiers 与 Environments Hub:统一的环境接口与生态,用于各类智能体式RL环境与评测。
Prime Sandboxes:高吞吐、安全的代码执行系统,用于智能体代码类环境。
算力编排:在64个互联节点上的512张NVIDIA H200 GPU完成调度与管理。
INTELLECT-3完整使用PRIME-RL进行端到端训练。
这套框架与Verifiers环境深度整合,支撑从合成数据生成、监督微调、强化学习到评估的整个后训练体系。
通过与Environments Hub的紧密连接,训练系统可以顺畅访问不断扩展的环境与评测任务集合。
PRIME-RL最显著的特点是全分布式(async-only)。
研究团队在上一代INTELLECT-2时就已经确认:
RL的未来一定是分布式的,也就是始终处于轻微off-policy的状态。
因为在长时序智能体rollout中,分布式是唯一能避免速度瓶颈、真正扩大训练规模的方式。
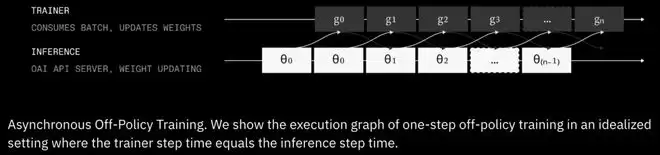
过去6个月,研究团队重点做了大量关于性能、稳定性和大规模效率的消融实验,INTELLECT-3正是这些研究的成果。
Prime Intellect也将在即将上线的Lab平台提供托管式PRIME-RL,访问者无需处理复杂基础设施就能进行大规模RL训练。
训练环境
INTELLECT-3的训练环境由Verifiers库构建,并托管于Environments Hub,这是Prime Intellect面向社区的RL环境与评测中心。
Verifiers是当前领先的开源工具,用来为模型构建RL环境与评测任务。
它提供模块化、可扩展的组件,让复杂环境逻辑也能以简洁方式描述,同时保持极高性能与吞吐。
传统的RL框架通常把环境强绑定在训练仓库里,使得版本管理、消融与外部贡献都不方便。
Environments Hub则把基于Verifiers的环境作为独立、可锁定版本的Python模块发布,并统一入口点,让任务可以独立版本化、共享与持续迭代。
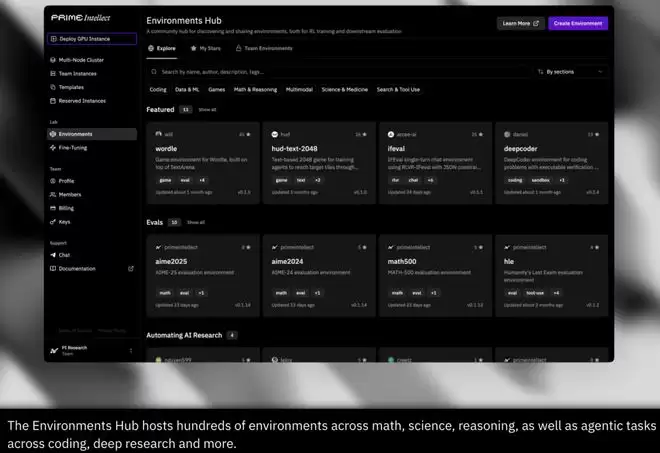
INTELLECT-3使用的所有环境和评测,均已公开在Environments Hub。
为了支持强化学习,Prime Intellect大幅扩展并升级了自研的Sandboxes基础设施。
在几千条并发rollout中安全执行外部代码,需要一个具备亚秒级启动、毫秒级执行延迟的容器编排层。
虽然Kubernetes提供了底层能力,但常规架构并无法满足这种高速度的训练需求。
Prime Sandboxes可以绕过Kubernetes控制面板,通过Rust直接与pod通信,做到接近本地进程的延迟;即使在大规模并发下也能在10秒内启动,且每个节点可稳定运行数百个隔离沙箱。
在Verifiers中,研究人员将沙箱启动与模型首轮推理并行,从而完全消除代码执行前的可感知等待时间。
算力调度
研究人员在64个互联节点上部署了512张NVIDIA H200 GPU。
最大工程挑战是如何在可能出现硬件故障的分布式系统里保持确定性与同步。
资源准备:使用Ansible做基础设施即代码、自动发现硬件,并进行InfiniBand预检以隔离慢节点或故障节点。
调度:通过Slurm + cgroup v2确保任务可以干净退出,不会留下占用GPU显存的残留进程。
存储:用Lustre提供高吞吐训练I/O,用NVMe NFS作为快速元数据与便捷SSH存储。
可观测性:通过DCGM + Prometheus监控,能在问题扩大前快速发现并下线不稳定节点。
训练方案
INTELLECT-3主要分两阶段:
基于GLM-4.5-Air的监督微调,以及大规模RL训练。
两个阶段以及多轮消融实验都在512张H200 GPU上运行,总共持续两个月。
研究人员训练了覆盖数学、代码、科学、逻辑、深度研究、软件工程等类别的多样化RL环境,用来提升模型的推理与智能体能力。
所有环境均已在Environments Hub上公开。
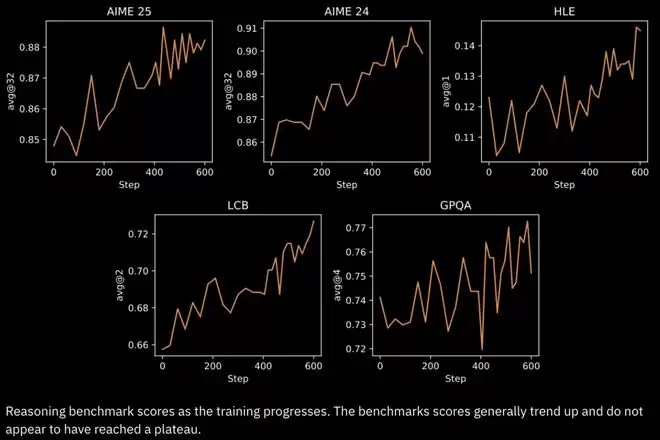
所有基准测试也都提供了标准化且验证过的实现。
未来,Prime Intellect的工作重点包括:
扩展智能体式RL:研究人员将继续训练,并更强调智能体环境,预计能在更多任务上获得进一步提升。
更丰富的RL环境:Environments Hub已拥有 500+ 任务,涵盖研究、电脑使用、定理证明、自动化和专业领域。INTELLECT-3 只用到了其中一小部分,下一步是让RL覆盖更多、更高质量的社区任务。
长时序智能体:研究人员正在让模型能够自我管理上下文(如裁剪上下文、分支推理、维护轻量外部记忆),从而让长时序行为真正可通过RL训练。未来也会探索专门奖励长时序推理的环境。
Prime Intellect正在构建开放的超级智能技术栈,把训练前沿模型的能力交到每个人手里。
INTELLECT-3 也证明:即使不是大实验室,也可以训练出与顶尖团队同台竞技的模型。
参考资料:
https://www.primeintellect.ai/blog/intellect-3
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!