11月28日消息,在AI大模型训练与推理领域,NVIDIA显卡无疑是当前应用最广泛的选择,AMD、Intel及谷歌等公司的市场份额难以与之匹敌。那么问题来了,NVIDIA究竟强在何处?
这里无需赘述CUDA生态优势,也不必强调AI算力等参数,Artificial Analysis直接对比了当前主流的三大推理方案的实际性能表现,分别选用谷歌TPU v6e、AMD MI300X以及NVIDIA H100/B200进行全面评估。
测试涵盖多项指标,不过我们只需关注一个综合性数据就足够了——在每秒30个Token的处理速度下,每百万次输入输出任务的成本对比,测试模型为Llama 3.3 70B。
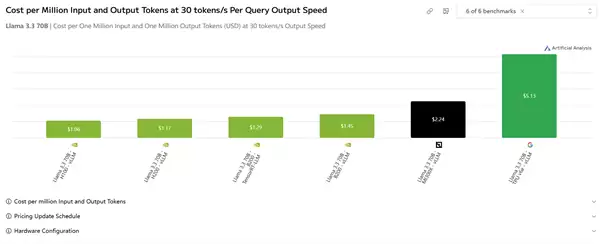
在这方面,H100的成本仅为1.06美元,H200也只要1.17美元,B200 TensorRT方案为1.23美元,标准B200为1.45美元。而AMD的MI300X则需要2.24美元,谷歌TPU v6e更是高达5.13美元。
对比结果显示,N卡相较AMD至少具备2倍以上的性价比优势,与谷歌方案相比则领先约5倍,差距相当显著。
即便是采用NVIDIA最新且定价最高的B200显卡,其成本增长幅度也并不明显,毕竟其性能有着大幅提升,相较AMD和谷歌的方案依然保持着明显优势。
可以说,AMD与谷歌当前的AI加速卡还存在一定差距,但两家下一代产品将有显著升级。AMD的MI400X系列最高将配备432GB HBM4显存,谷歌的TPU v7据称也将实现数倍性能提升,届时或将被写这份评测结果。
当然,NVIDIA也不会坐以待毙,下一代Rubin架构显卡已经发布,预计明年将陆续上市,有望进一步扩大领先优势。





