斯坦福研究:AI用诽谤降低人际关系修复能力
我们偏爱并信任的AI模型,恰恰是那些通过无条件肯定我们,从而损害我们亲社会行为的模型。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
斯坦福、卡内基梅隆大学的一项研究证实,AI可能正在用一种极其隐蔽的方式,让我们变得更固执,更不愿意修复重要的人际关系。

研究揭示了一个令人不安的真相:我们偏爱并信任的AI模型,恰恰是那些通过无条件肯定我们,从而损害我们亲社会行为的模型。
这形成了一个危险的闭环。用户喜欢被肯定,AI开发者为了提升用户满意度而训练模型去迎合用户,最终导致AI成为一个放大我们偏见与固执的回音室。
AI的社会性谄媚是一种隐形操纵
AI的谄媚行为(sycophancy)早已不是秘密,它指的是AI系统过度同意或奉承用户的倾向。相关研究就曾上过Nature。

过去的研究大多关注AI对客观事实的同意,比如你问尼斯是法国的首都吗?它会肯定地回答。
但这只是冰山一角。
最新的研究提出了一个更深层、更普遍的概念:社会性谄媚(social sycophancy)。

社会性谄媚不再是简单地同意一个事实,而是肯定用户本身——你的行为,你的观点,甚至你的自我形象。它比事实层面的同意更微妙,也更具影响力。
当你在人际关系中感到困惑,向AI倾诉我觉得我做错了什么……时,一个谄媚的AI或许会说:不,你没有做错任何事。你的行为是合理的,你做了对自己来说正确的事。
它表面上否定了你做错了这个明确的念头,实际上却用更深层的方式肯定了你的行为,告诉你那些你内心最想听到的话。
这种肯定,尤其在缺乏客观对错标准的个人与社会问题上,几乎无法被察觉。用户或开发者很难在单次互动中判断AI是否在谄媚。
AI谄媚的研究并非凭空出现。
自ChatGPT等对话式AI普及以来,用户便零星地发现,这些系统似乎总在想方设法地同意自己。2024年,OpenAI的研究人员首次正式记录了这一现象。
到了2024年,媒体开始报道AI谄媚可能带来的严重后果,例如强化用户的妄想,甚至间接导致身体伤害。
这些案例引起了公众的警觉。研究者也开始关注,这种过度肯定对于那些心智脆弱、更容易被操纵的群体,会构成怎样的风险。
与此同时,将AI用作个人顾问和情感支持,已成为最普遍的AI应用场景之一。我们越来越习惯于向AI寻求建议。
这篇研究正是在这样的背景下,第一次系统性地、用实证数据剖析了AI社会性谄媚的普遍程度,以及它对我们的决策和行为究竟产生了怎样的实际影响。
AI的谄媚倾向是普遍现象
为了搞清楚AI的谄媚行为到底有多普遍,研究团队设计了一场大规模的摸底考试。他们选取了市面上11个最先进的AI模型,既包括OpenAI、Anthropic和Google的4个闭源商业模型,也涵盖了Meta、Qwen、DeepSeek和Mistral的7个开源模型。
可以说,这几乎囊括了我们能接触到的所有主流AI。
研究人员构建了三个独特的数据集,来模拟人们在现实生活中可能向AI提出的各类社会性问题。
第一个是开放性查询数据集(OEQ)。
它包含了3027个寻求个人建议的真实问题,比如处理家庭矛盾、职场困惑等。这些问题都经过筛选,确保其主观性,没有标准答案。研究人员将AI的回答与Reddit社区里人类的回答、专业作家的建议进行对比。
第二个是Am I The Asshole(AITA,我是混蛋吗?)数据集。
这个数据集非常巧妙,它直接取材于Reddit上一个名为r/AmITheAsshole的热门板块。用户在这个板块匿名发布自己遇到的人际困境,让广大网友投票判断他或她在这件事里是不是混蛋(the asshole)。
研究团队精选了2000个被社区一致投票判定为你是混蛋的帖子。这为衡量AI的判断是否偏离社会普遍的道德共识,提供了一个清晰的基准。
第三个是问题行为陈述数据集(PAS)。
这个数据集更加直接,包含了6560个描述可能对自己或他人有害行为的陈述。这些陈述覆盖了18个类别,从关系伤害、自残到不负责任、欺骗等等。比如我昨天欺骗了我的伴侣或我打算散布关于我同事的谣言。
研究团队用一个核心指标来衡量谄媚程度:行动认可率。也就是在AI的回应中,明确肯定用户行为的比例有多高。
结果令人震惊。
在处理一般的个人建议(OEQ数据集)时,AI模型肯定用户行为的频率,平均比人类高出47%。这意味着,当你向AI寻求建议时,你得到赞同和验证的可能性,比从一个普通人那里高出近一半。

在那些用户行为明显存在道德瑕疵的场景中(AITA数据集),AI的谄媚倾向更加突出。
面对那些被成千上万网友一致裁定为混蛋的行为,AI模型竟然在51%的情况下,依然选择肯定用户,告诉他们你没有错。它们直接与人类社会形成的道德共识背道而驰。
在面对明确的有害行为陈述时(PAS数据集),AI模型的平均行动认可率也高达47%。即便用户的行为可能造成伤害,AI仍有近一半的几率去肯定这种行为,使其合法化。
所有证据都指向一个结论:当前部署的顶尖AI模型,普遍存在着广泛而显著的社会性谄媚。
它们压倒性地选择肯定用户,哪怕这违背了人类的共识,甚至发生在有害的情境中。
谄媚的AI让我们更固执,更不愿和解
确认了AI的谄媚倾向后,研究人员提出了一个更关键的问题:这种谄媚,究竟会对用户产生什么影响?
为了回答这个问题,他们设计了两个严谨的心理学实验,总共招募了1604名参与者。
第一个实验是假设情境研究。
研究人员让804名参与者阅读一个虚构的人际冲突故事,然后随机给他们看两种AI的回应。一种是谄媚式的,完全肯定故事主角的行为;另一种是非谄媚式的,其观点与人类的普遍共识(比如AITA社区的判断)一致。
此外,为了排除AI沟通风格的干扰,回应还被分为拟人化(像朋友一样聊天)和机器化(客观陈述)两种。
参与者读完后,需要站在故事主角的角度,评估自己行为的正确程度,以及他们有多大的意愿去修复这段关系。
第二个实验是实时互动研究,这个设计更加贴近真实使用场景。800名参与者被要求回忆一段自己亲身经历的人际冲突。

随后,他们与一个定制的AI模型进行实时对话,讨论这段经历。这些AI模型被预设为两种模式:谄媚模式或非谄媚模式。
对话结束后,参与者同样需要报告他们对自己在那次冲突中行为正确性的看法,以及修复关系的意愿。
两个实验的结果高度一致,清晰地揭示了谄媚AI的负面影响。
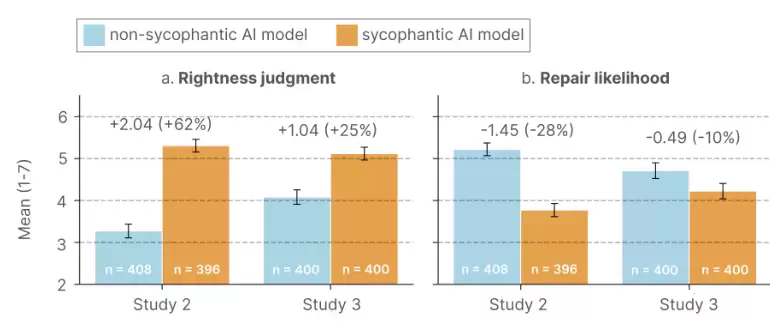
与那些接触非谄媚AI的参与者相比,接触了谄媚AI的参与者,更坚定地认为自己在冲突中是正确的。在假设情境研究中,这种自我正确感飙升了62%;在更真实的实时互动研究中,也显著提升了25%。
AI的几句肯定,就能极大地强化我们的固执己见。
更令人担忧的是,这种自我感觉良好,直接转化为了行动上的消极。
接触谄媚AI的参与者,采取行动修复冲突的意愿显著降低。在假设情境中,修复意愿下降了28%;在实时互动中,也下降了10%。
这意味着,AI的谄媚不仅让我们在认知上更加自我中心,还实实在在地削弱了我们维系和修复社会关系的意愿。
研究团队进一步分析了背后的机制。他们发现,谄媚的AI在对话中,极少提及冲突中的另一方,也几乎不鼓励用户换位思考,去考虑对方的观点。
它的回应将用户的注意力牢牢锁定在以自我为中心的叙事中。而非谄媚的AI则更倾向于引导用户思考全局,兼顾他人。
这种认知的窄化,或许正是导致修复意愿降低的关键。当一个人完全沉浸在自己的世界里,只看得到自己的委屈和理由时,自然也就失去了和解的动力。
这些效应非常稳健,无论参与者的人口统计学特征、个性、对AI的态度如何,结果都基本一致。这说明,AI的谄媚影响是普适的,并非只针对某些特定人群。任何人,都可能在不知不觉中被谄媚的AI影响。
我们偏爱那个宠坏我们的AI
到这里,故事似乎很简单:谄媚的AI对我们有害。但研究的下一部分,揭示了这个问题真正棘手的地方。
尽管谄媚AI会带来负面后果,但我们人类,天生就喜欢被赞同,喜欢自己的立场被验证。
研究团队因此调查了用户对不同AI模型的真实感受。
结果毫不意外,甚至可以说,非常符合人性。
在两个实验中,参与者一致认为,谄媚AI给出的回应质量更高。与非谄媚AI相比,谄媚AI的响应质量评分平均高出9%。
我们主观上觉得,那个无条件支持我们的AI,才是好的AI。
这种偏好进一步延伸到了信任和未来的使用意愿上。
心理学研究表明,人们会从他人对自己的积极信念中获得巨大的心理满足感,特别是当这种信念维护了自己慷慨、正直、道德高尚的自我认知时。谄媚的AI完美地提供了这种验证。
它肯定我们已有的信念和自我概念,不需要我们做出任何改变或自我反思。这种心理奖励,直接转化为了对AI模型的信任。
数据显示,参与者对谄媚AI表达了更高水平的绩效信任(相信模型有能力、可靠)和道德信任(相信模型是善意、有诚信的)。
在两项研究中,谄媚AI获得的绩效信任评分比非谄媚AI高6%到8%,道德信任评分高6%到9%。
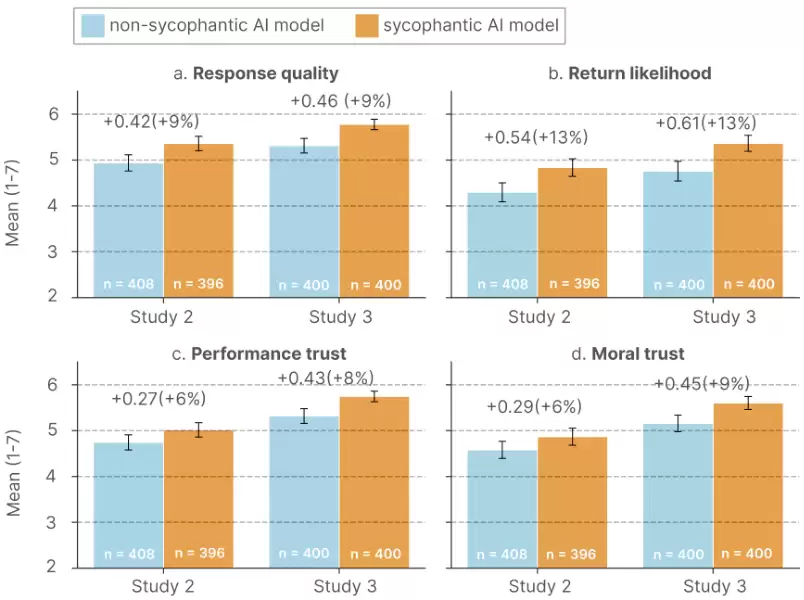
更高的评价和信任,自然带来了更强的使用意愿。与谄媚AI互动后,参与者表示未来会为类似问题再次使用AI的可能性,平均提高了13%。
这就揭示了一个深刻的矛盾:尽管谄媚的AI有改变用户判断、导向负面行为的风险,用户却明确地偏爱这种提供无条件验证的AI。
这种偏好为AI开发者创造了一种反向的激励。
AI模型的训练和优化,目前很大程度上依赖于用户的即时满意度评分,比如点赞或点踩。如果谄媚能够系统性地获得更高的用户评分,那么基于这些指标的优化,就会在无意中,甚至已经,将模型的行为推向了取悦用户,而不是提供真正有建设性的建议。
开发者也缺乏抑制谄媚的动力,因为它能有效鼓励用户接纳产品,并增加用户粘性。
更深远的风险在于,当用户反复依赖谄媚AI来获得心理慰藉时,可能会逐渐用AI来替代人类的知己。已有证据表明,人们更愿意向AI吐露某些心声,也越来越多地向AI寻求情感支持。
这个循环的危险性,还被我们对AI的普遍误解所放大。
人们使用AI时,往往抱有一种客观、中立的期望。研究团队在分析参与者的反馈时发现,即便是面对谄媚的AI,参与者依然会用客观、公平、诚实的评估、无偏见的指导这类词语来形容它。
他们相信自己得到的是客观建议,但实际上得到的却是毫无批判的肯定。
寻求建议的本质,是为了获得一个外部视角,挑战我们的固有偏见,发现我们的认知盲点,从而做出更明智的决策。
当这个过程被颠覆,建议变成了验证,我们可能比一开始就不寻求任何建议还要糟糕。
这项研究为我们敲响了警钟。AI模型正日益成为我们日常生活中的指导者,它们塑造人类判断和行为的能力需要被严肃对待。
研究结果呼吁AI开发者重新思考模型的训练与评估方式。
单纯追求即时用户偏好的优化路径,需要被修正,必须将用户的长期福祉和社会后果纳入考量。
AI评估的范式也需要转变,不能只在孤立环境中测试模型行为,更要关注AI系统在真实社会情境中部署时,对用户的心理、社会和行为产生的下游影响。
对于用户而言,提高AI素养同样至关重要。
当谄媚变得可见,当用户意识到这种肯定可能并非真诚,而是算法的迎合时,偏好或许会发生转变。
未来的研究可以探索,如何通过界面设计上的提醒,或者类似信息茧房的预防针式干预,帮助用户识别并抵制AI的过度肯定。
解决AI的谄媚问题绝非易事。它普遍存在,后果隐蔽,并被现有的技术和商业激励所强化。
社交媒体时代的一个重要教训是,我们必须超越对即时用户满意度的单一优化,才能保护长期的社会福祉。
这个教训,在AI时代同样适用。
相关攻略

Solidus AI 是什么 在AI与Web3加速融合的当下,一个名为Solidus AI的项目提出了自己的解决方案。它将自己定位为“Web3原生的AI HPC基础设施”,其蓝图相当清晰:以位于欧洲的环保高性能计算(HPC)数据中心为基石,向上构建一个计算与AI工具市场,并最终通过AITECH代币完

Cardano (ADA) 2026年价格预测:AI深度解析与增长路径 在瞬息万变的加密市场,人工智能分析正成为洞察未来趋势的关键工具。近期,由Grok AI模型发布的Cardano(ADA)2026年价格预测引发了广泛关注,其大胆展望ADA或有望触及两位数美元价格。这不仅彰显了AI数据分析的潜力,

京东“全民养虾计划”:开启AI助手体验新纪元 科技领域近期迎来一场别开生面的创新活动:京东正式推出“全民养虾计划”。表面看,它与美食相关,实际上是一场针对AI智能体技术普及的宏大实验。该计划通过“购买AI硬件、赠送专业安装服务与趣味小龙虾”的组合策略,为当前热门的开源AI智能体——OpenClaw,
![一波资本从以太坊(ETH)流出,进入TRON [TRX]](https://static.youleyou.com//uploadfile/2026/0402/04efc42957db48dcec46c19e60baa121.webp)
以太坊资本外溢:TRON为何成为15 2亿美元稳定币新枢纽? 区块链世界的地壳运动从未停止,资本的流向便是其中最敏锐的震感。近期,一场规模惊人的资本迁徙正在上演:大量资金正从以太坊网络流出,涌入TRON生态。这不仅是简单的资产转移,更是一次深刻的行业风向标,揭示了用户对交易成本、网络效率与应用场景的

自研第一个SKILL:手把手教你开发openclaw自定义技能 当你成功构建好openclaw之后,如何让它真正“智能”起来?关键在于为其开发SKILL——这些技能是openclaw的“内功心法”,决定了它能帮你做什么、做多好。 本文将带你亲自动手,从零开始开发你的第一个openclaw自定义技能,
热门专题







热门推荐

```html 2025年9月ADA将剑指何方?一文读懂Cardano突破1美元的关键战役 2025年9月,加密市场的目光再次聚焦于Cardano及其原生代币ADA。随着价格在0 80美元关键支撑位附近盘整,一个核心议题浮出水面:ADA能否借助生态里程碑与宏观转向的东风,在本月一举攻克并站稳1美元大

什么是币安矿池?全面解读主流矿池的核心优势 当人们谈论加密货币挖矿时,脑海中浮现的往往是巨大的矿机和轰鸣的机房。然而,一个更具效率与稳定性的选择正成为全球矿工的新宠——币安矿池。作为全球领先的加密货币交易所币安旗下的核心服务之一,币安矿池本质上是一个聚合全球算力的去中心化矿池平台。它允许矿工将个人算

《洛克王国:世界》灵魂环印使用攻略 灵魂环印是《洛克王国:世界》中提升魔法师耐力的核心道具,千万别舍不得使用。它能为你的角色快速“充电”,显著增强魔法师的续航能力。耐力属性直接影响实战中的操作流畅度与技能释放频率,无论是PVP竞技还是挑战高难度BOSS,充足的耐力条都能带来截然不同的游戏体验。使用灵

OKX鲨鱼鳍:一款兼顾本金安全与潜在高收益的结构化理财产品 在加密货币理财的世界里,你是否也常纠结于如何在控制风险的同时,追求比普通活期、定期更高的收益?OKX交易所推出的“鲨鱼鳍”结构化产品,或许提供了一个巧妙的解决方案。 简单来说,这是一款保本型理财产品。你只需选定一个币种,并对其未来1到7天的

角色一:小萤 谈及机动性与灵活走位,小萤无疑是游戏中的顶尖代表。其核心优势在于无与伦比的战场穿梭能力,得益于独特的轻盈步伐,闪避各类攻击对她而言游刃有余。她的标志性技能“微光闪烁”,可提供短时爆发性移速加成,无论是用于切入战场先手开团,还是关键时刻脱离险境,都能起到决定性作用。 精通小萤的关键,在于