阿里新研究:统一VLA与世界模型的核心方法解析
WorldVLA是由阿里巴巴达摩院、湖畔实验室和浙江大学共同研发的统一框架,创新性地将视觉语言动作模型(VLA)与世界模型的优势相融合。
如果说视觉让AI能够观察世界,动作让AI得以改变世界——
那么WorldVLA正在让AI真正理解世界。
顾名思义,WorldVLA是一个将视觉语言动作模型与世界模型进行深度融合的智能架构,由阿里巴巴达摩院携手湖畔实验室、浙江大学联合推出。

在该平台框架下,
世界模型能够通过综合分析动作与图像的关联性来预测未来画面,旨在掌握环境中的潜在物理规律,从而提升动作生成的精准度;动作模型则可基于视觉观测生成连贯动作序列,这不仅强化了机器对环境的感知能力,更能反向促进世界模型的视觉内容生成能力。
实验结果充分表明,WorldVLA在各个任务维度的表现显著优于独立的动作模型与世界模型,充分体现了两者协同带来的增强效应。

下面我们通过具体案例来深入了解。
整合VLA与世界模型的协同优势
当前,虽然VLA和世界模型在各自领域不断发展,但其功能上的局限性已成为制约技术突破的关键瓶颈:
VLA模型:基于预训练的多模态大语言模型构建,虽具备跨场景任务泛化能力,但仅将动作作为输出端,未能深度整合为输入进行分析,缺乏对动作意图的全面理解。世界模型:能够基于当前观测和动作序列预测未来视觉状态,理解视觉信息与行为动态,但无法直接生成具体动作,在需明确动作规划的智能化场景中应用受限。
为解决上述技术难题,研究团队创新性地提出了WorldVLA框架——一种用于统一动作与视觉理解的具备自回归能力的动作世界模型。
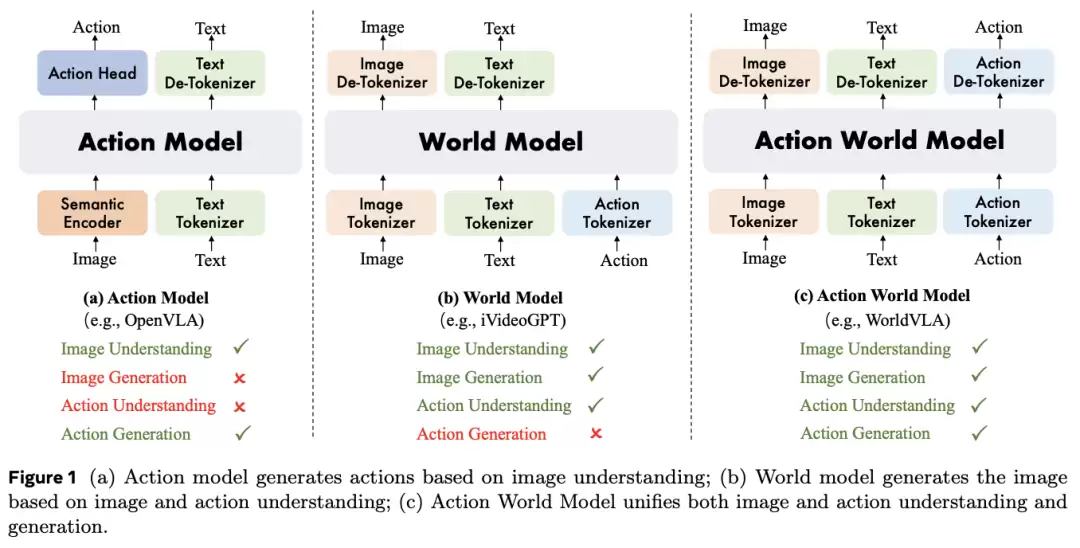
团队基于Chameleon多模态大模型进行初始化,让WorldVLA使用三套独立的分词器对视觉信息、文本指令和动作序列进行统一编码处理。
图像分词器采用经过优化的VQ-GAN模型,并针对关键视觉区域引入了感知损失函数进行专项优化。
值得关注的是,该图像压缩模块的压缩比为16,码本规模为8192。对于256×256分辨率的输入图像,会生成256个视觉token;而对于512×512的高清图像,则会生成1024个视觉语义单元。
动作分词器将连续的机器人动作的每个维度离散化为256个区间,区间宽度根据训练数据的数值范围动态确定。每个动作由7个语义单元表示,包括3个相对位置坐标、3个相对角度参数,以及1个绝对夹爪状态标识。
文本分词器采用训练好的BPE分词器,词表规模为65536,其中特别包含了8192个图像语义单元和256个动作语义单元。
所有文本、动作和视觉信息都被统一离散化为语义序列,并以自回归方式进行联合训练。
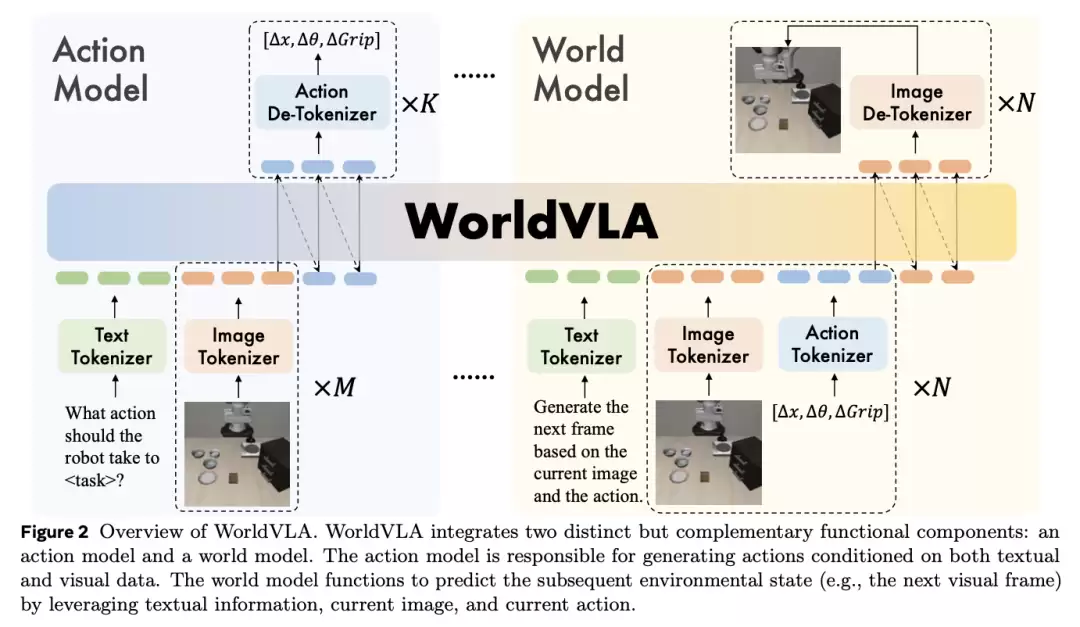
自回归模型中的标准注意力机制通常采用因果注意力掩码,即当前token只能访问序列中前面的语义信息,而无法获取后续单元的内容,具体机制如下图所示。

然而,这种传统配置在生成连续动作序列时存在明显不足。在默认注意力掩码下,早期动作生成产生的误差会传递到后续动作预测中,从而导致系统性能下降。
为解决这一技术痛点,团队创新性地提出了针对动作生成的替代注意力掩码方案,具体机制如图(b)所示。该设计确保当前动作的生成仅依赖于文本指令和视觉观察输入,有效屏蔽之前动作序列的干扰影响。
这种注意力机制设计使自回归框架能够并行生成多个动作,而世界模型组件则继续遵循传统的因果注意力掩码,如图(c)所示。
之后,研究团队通过融合动作模型数据与世界模型数据对WorldVLA进行联合训练。
其中,特别引入世界模型数据以增强动作生成能力,主要基于三个关键维度考量:
1、环境物理理解:世界模型能够基于当前状态和执行的动作来预测未来观测变化,从而学习环境中的潜在物理规律,这种认知深化对精细化操作任务尤为重要。
2、动作评估与风险规避:世界模型可以模拟并预测备选动作的潜在结果,有助于筛选可能导致不良状态的动作序列。
3、精准动作解析:世界模型需要对动作输入进行精确语义解析,这反过来支撑动作模型生成更有效且符合上下文语义的动作。
此外,动作模型也能增强视觉理解能力,从而进一步支持世界模型的视觉内容生成。
动作模型与世界模型相互赋能
基准测试表现
如下表数据所示,即便在没有进行预训练的情况下,WorldVLA模型也展现出优于离散化OpenVLA模型的性能水平,这充分证明了其架构设计的先进性与有效性。
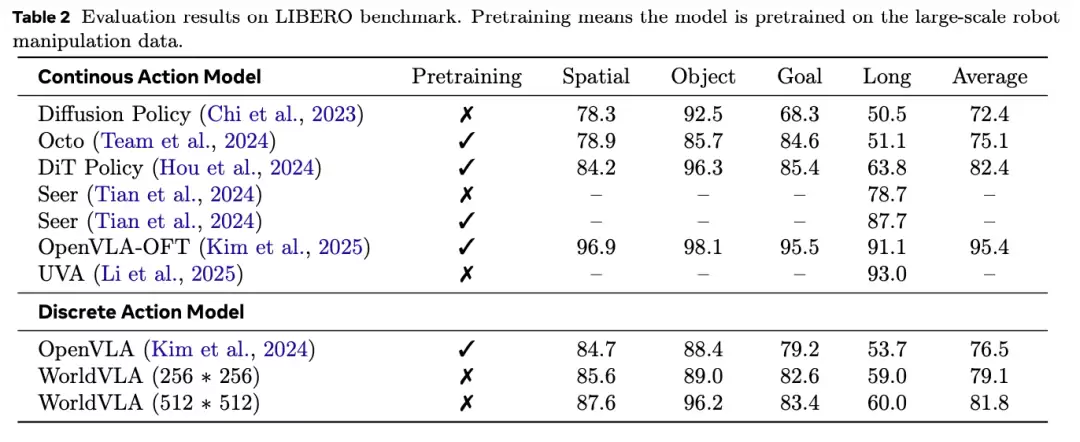
同时值得注意的是,模型性能与图像分辨率呈现明显正相关性。具体而言,512×512像素分辨率相比256×256像素分辨率带来了显著性能提升。
这一现象主要归因于Chameleon主干模型的预训练策略,其图像分词器与大语言模型组件在512×512分辨率下进行了针对性优化。
另一方面,更高的输入分辨率自然提供了更丰富的视觉细节信息,这对需要高操作精度的机器人抓取任务尤为关键。
世界模型助力动作模型
研究表明,引入世界模型数据能够显著提升动作模型的综合性能表现。
世界模型的核心功能是基于当前状态与执行动作预测环境状态变化,这种生成机制促使模型系统学习底层的物理规律,而正是掌握这种规律成为实现精确抓取等高级操作任务的核心前提。
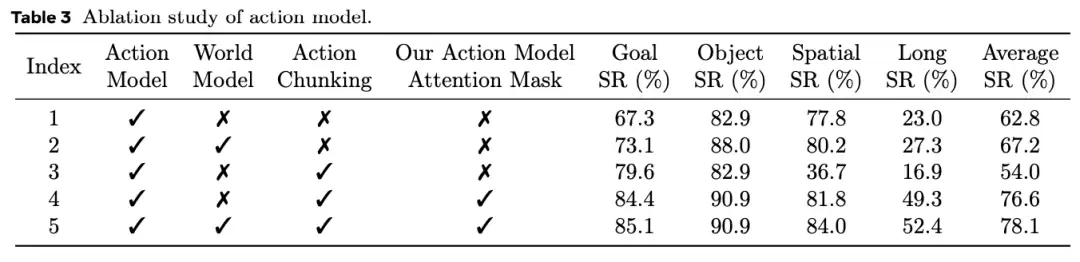
从更深层次来看,世界模型赋予了系统前瞻推演能力:通过预判备选动作可能产生的后果,为决策过程提供关键信息输入,从而优化动作选择策略,提高任务成功率。
下图的实际案例直观展示了这一技术优势。基线动作模型会直接移动到目标点位但未能成功抓取物品,而WorldVLA则持续尝试抓取,直到确认操作成功后才移向目标放置位置。

动作模型赋能世界模型
在生成质量方面,WorldVLA显著优于纯世界模型,尤其是在生成长视频序列时的表现更为突出。

此外,纯世界模型在多个场景中呈现明显缺陷:无法成功拉开抽屉、移动盘子后导致碗消失、未能将碗平稳放置在灶台上。
而融合动作的世界模型在这些关键场景中都生成了连贯且符合物理规律的后续状态。

核心作者介绍

论文第一作者范崎,于2024年8月加入阿里巴巴达摩院。本科毕业于浙江大学,硕士和博士均毕业于香港科技大学,2024年在新加坡南洋理工大学访问过半年,曾在微软亚洲研究院、上海AI Lab、海康威视和阿里巴巴通义实验室实习。
业界专家观点
小米汽车高级研究总监、主任科学家陈龙也对此发表了专业见解:
VLA与WM并非需要二选一的技术路线,二者可以有机结合相互促进。
一个负责“抽象思考”,一个负责“物理感知”,VLA与WM的深度结合,才是通向具身智能的正确发展方向。
论文链接:https://t.co/ZgHyhqQnyf
Github链接:https://t.co/SxDZGuhbL7
相关攻略

如何利用AI文字排版工具提升文档创作效率 在追求高效能的现代职场中,文档创作的速度与质量直接影响着个人与团队的核心竞争力。你是否思考过,为何优秀的同事总能迅速产出结构清晰、格式专业的文档?其秘诀很可能在于熟练运用AI文字排版工具。这类智能工具正深度重塑我们的工作模式,将创作者从枯燥的格式调整与内容组

如何利用AI生成前端代码提升文档处理效率 在数字化转型的进程中,前端开发与文档处理是两项高频且耗时的核心任务。是否存在一种方法,能够同时为这两项工作注入强大的效率引擎?答案是肯定的。将AI生成前端代码的能力与智能文档处理技术深度融合,正成为提升企业整体工作效率与创新水平的新范式。 AI生成前端代码的

使用情景: 活动总结是每个团队和组织进行复盘与经验沉淀的必备环节。无论是公司年会、项目复盘、社区活动还是客户沙龙,一份专业的总结报告对于提炼经验、识别不足、规划未来都至关重要。然而,面对繁杂的数据和零散的反馈,许多人往往不知从何下笔。此时,一份结构清晰、逻辑严谨的活动总结PPT模板就显得尤为珍贵——

DeepSeek宣布其Pro模型API优惠将转为永久降价,调用成本大幅降低至原价的四分之一。同时,公司正进行高达500亿元的首轮融资,创始人梁文锋个人计划出资200亿元以强化控制权。降价与巨额融资相结合,旨在降低行业门槛、构建生态,并支撑其长期开源与AGI战略,展现了公司的长期主义视野。

Excel批量处理能极大提升效率。填充功能可快速复制文本、序列或公式;快捷键如Ctrl+D能快速填充数据;公式结合填充实现批量计算;条件格式化可自动高亮关键数据;查找替换功能能准确完成批量内容修改。掌握这些技巧并多加练习,可高效应对日常数据处理工作。
热门专题







热门推荐

MiniCPM-o 4 5是什么 在探索更自然、更智能的人机交互道路上,我们始终在期待一个“全能型选手”的到来。如今,这个角色或许已经登场。面壁智能最新开源的MiniCPM-o 4 5,一个仅拥有90亿参数的全模态大模型,正致力于重新划定“智能对话”的边界。 它彻底颠覆了传统一问一答的“对讲机”式交

Binance币安 欧易OKX ️ Huobi火币️ 想在2025年安全获取欧易OKX的正版APP?其实秘诀就一个:认准官方网站,避开所有仿冒和可疑的下载渠道。要知道,欧易现已统一更名为欧易OKX,其核心业务始终围绕数字资产交易及相关服务展开。 确认官方网站地址 第一步,打开浏览器,手动输入欧易OK

SecondMe Book是什么 在AI社交这一前沿赛道,一款国产平台正带来独特的解决方案。SecondMe Book,本质上是一个能够让你构建个人AI数字分身的创新平台。它允许用户创建一个能够代表真实自我风格与思维的AI数字身份,并让这个“第二自我”在一个专属的AI社交网络中自主运行——包括主动发

在AI大模型技术快速发展的今天,如何在卓越性能与高效推理成本之间取得最佳平衡,已成为行业关注的核心焦点。近期,由阶跃星辰推出的开源模型Step 3 5 Flash引发了广泛热议。该模型专为智能体(AI Agent)应用场景深度优化,旨在顶尖能力与亲民部署成本之间,构建一个极具竞争力的技术支点。 简而

LongCat-Flash-Lite是什么 在探索大语言模型性能与效率的最佳平衡点时,美团近期推出的LongCat-Flash-Lite提供了一个极具创新性的解决方案。作为新一代高效大语言模型,它凭借其突破性的架构设计,在人工智能领域获得了广泛关注。 简而言之,该模型创新性地融合了“混合专家系统(M