中科院联合清华发布VLA-R1模型:机器视觉语言行动推理新突破
刚刚,中科院自动化所、清华和GigaAI联合发布视觉-语言-行动(Vision-Language-Action, VLA)模型的R1推理版本。让机器人实现了先思考再行动。
还记得 DeepSeek R1吗?它实现了大语言模型先思考再回答。
刚刚,中科院自动化所、清华和GigaAI联合发布视觉-语言-行动(Vision-Language-Action, VLA)模型的R1推理版本。让机器人实现了先思考再行动。

当前的机器人模型在执行任务时,像一个提线木偶,直接输出动作,而VLA-R1模型给机器人装上了一个会推理的大脑,让它在行动前先想清楚每一步。
视觉-语言-行动(Vision-Language-Action, VLA)模型是具身智能(embodied AI)领域的一项关键技术。它的目标是让一个智能体,比如机器人,能够像人一样,通过看(视觉)、听(语言)来理解指令,并作出相应的行动。
这就像你告诉一个朋友,请把桌上的红苹果递给我。他会先用眼睛扫描桌子,找到所有的苹果,分辨出红色的那个,然后规划手臂的运动路径,最后伸手拿起并递给你。这个过程融合了感知、理解、推理和行动。
早期的VLA模型已经能做到不错的程度。它们通过学习海量的图片与文字,建立了对世界的基本认知。比如,它知道什么是苹果,什么是桌子。接着,通过学习大量的操作数据,它将这种认知与具体的机器人动作联系起来。比如,它学会了如何控制机械臂去抓取一个物体。
这使得模型具备了宝贵的泛化能力。即使它没见过某个特定品牌的杯子,但因为它理解‘杯子’这个概念,它也能举一反三,去抓取那个新杯子。它还能理解组合性的新指令,比如‘把方块放到圆圈的左边’。
然而,这些模型有一个共同的短板,它们像一个做事不过脑子的行动派。
你给它一个指令,它几乎是凭直觉,直接给出一个最终动作。这个过程像个黑箱,中间没有清晰的思考步骤。它不会明确地去推理物体的用途(可供性),比如杯子是用来装水的,锤子是用来敲的。它也不会仔细分析物体之间的几何关系,比如哪个物体在前面,哪个在后面。
这种莽撞的模式,在简单的场景下或许还能应付。一旦环境变得复杂,问题就暴露无遗。
想象一下桌上有两个颜色非常接近的红色方块,指令是‘拿起那个深红色的方块’。模型很可能因为无法进行细致的推理而选错。
再比如,桌上有好几个碗,指令是‘把草莓放进碗里’。模型应该选择哪个碗?是离得最近的,还是最大的,还是空的那个?缺乏推理能力,模型的选择就带有很大的随机性,任务成功率自然大打折扣。
更关键的是,现有的模型训练方法也难以系统性地提升这种推理能力。主流的方法是监督微调(supervised fine-tuning, SFT)。就是给模型看大量的‘问题-标准答案’,让它去模仿。这种方式很少能优化思考过程的质量,也缺乏对最终执行效果的有效奖励。
即便引入了强化学习(Reinforcement Learning, RL),奖励设计也通常很单一,比如只奖励最终任务是否成功。这很难同时优化过程的合理性(比如视觉区域对齐是否准确)和动作的连贯性(比如轨迹是否平滑)。这导致模型在面对新环境或真实世界时,性能会大幅下降。
机器人需要学会思考。不是简单的反应,而是有条理、有逻辑的逐步推理。
VLA-R1学会了先思考再行动
针对这些挑战,研究人员提出了VLA-R1,一个会推理的VLA模型。它的核心思想很简单:把人的思考过程,也就是思维链(Chain-of-Thought, CoT),教给模型,并用一套可验证的奖励机制去强化这个思考过程和最终的行动。
这全面提升了机器人行动的准确性。
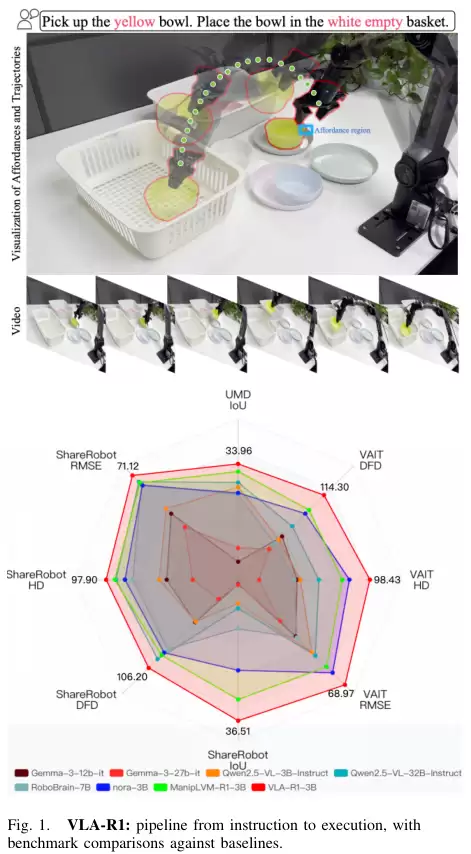
整个VLA-R1的训练和工作流程分为两个核心阶段。
第一阶段是学习如何思考。这个阶段采用的是监督微调。
研究团队首先需要高质量的教材,也就是带有清晰思考过程的训练数据。他们构建了一个名为VLA-CoT-13K的数据集。他们使用强大的Qwen2.5-VL-72B模型,为13000个任务场景自动生成了中间的推理步骤。
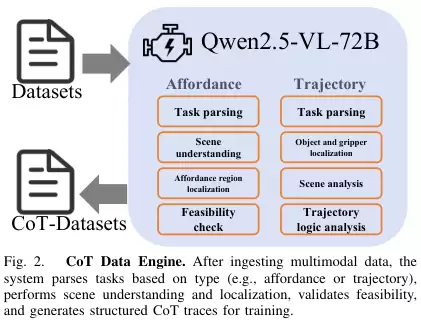
比如,对于‘把绿色的积木放到红色的碗里’这个任务,生成的思维链可能是这样的:
识别任务目标:移动绿色积木。定位绿色积木:在图像的左上角区域找到了一个绿色的方块。识别目的地:红色的碗。定位红色的碗:在图像的右侧中间位置找到了一个红色的碗。规划行动轨迹:从绿色积木的位置,规划一条避开障碍物的路径,移动到红色碗的上方,然后放下。这些带有思维链的数据,就像一本本详细的解题步骤分析。模型在学习时,不仅仅是看到最终答案(机器人动作),更重要的是学习了从问题到答案的整个逻辑推理过程。这种‘先推理,后行动’的策略,让模型学会了分解任务,将视觉感知和最终的动作目标更紧密地联系起来,也大大提高了学习效率。
在模型架构上,VLA-R1使用Qwen2.5-VL-3B作为基础。它的视觉部分是一个经过重新设计的视觉Transformer,可以高效处理高分辨率图像和视频。语言部分则使用了成熟的Qwen2.5解码器。图像和文字信息在这里融合,共同推理,最终生成包含推理过程和动作预测的结构化输出。这个输出随后被转换成机器人可以执行的连续7D动作指令(包括三维空间位移,三维旋转和夹爪的开合)。
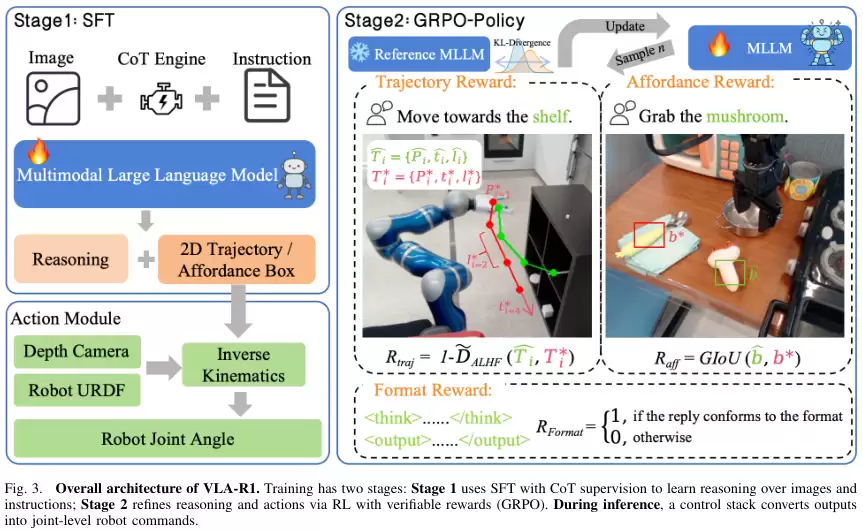
第二阶段是强化思考与行动的质量。这个阶段采用的是强化学习。
经过第一阶段的学习,模型已经初步具备了推理能力。但这种推理可能还不够精确,不够鲁棒。就像一个学生学会了解题步骤,但计算过程可能还会有小错误。
为了解决这个问题,研究团队引入了一套基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards, RLVR)策略。他们采用了一种名为群体相对策略优化(Group Relative Policy Optimization, GRPO)的算法。这个算法的好处是,可以让模型从结构化的、可验证的奖励中学习,同时保持训练过程的稳定。
研究团队设计了三种具体的、可量化的奖励,像三位严格的考官,从不同维度评判模型的输出。
第一位考官负责评判轨迹。它使用的评分标准叫作角度长度增强Fréchet距离(Angle-Length Augmented Fréchet distance,ALAF)。传统的评价方式可能是比较两个轨迹对应点之间的距离,但ALAF更聪明。它不仅考虑位置,还考虑了轨迹的顺序、方向和局部长度。
第二位考官负责评判空间定位的准确性。比如指令是‘拿起那个苹果’,模型需要先在图像中框出苹果的位置。这位考官使用的评分标准是广义交并比(Generalized Intersection over Union,GIoU)。交并比(IoU)是衡量两个边界框重合度的常用指标。但当两个框完全不重合时,IoU为0,无法反映它们之间的距离。GIoU则改进了这一点,即使两个框不重合,它也能通过计算包裹它们的最小外接矩形来给出一个惩罚,从而衡量它们的距离。
第三位考官负责评判输出格式。它要求模型的输出必须严格遵守‘先推理,后动作’的结构。输出必须先包含一段推理文字,然后是一个被特定标签(...)包裹的动作指令。
通过这三位考官的联合评分,模型不断调整自己的策略,力求在轨迹对齐、空间定位和格式规范性上都做到最好。这个过程系统性地优化了模型的推理鲁棒性和执行准确性。
严苛的考验证明了它的强大
为了验证VLA-R1的真实水平,研究团队设计了一系列严格的实验,涵盖了从标准数据集到模拟环境,再到真实世界的全方位考验。
首先是在熟悉的领域内数据集(ShareRobot)上进行测试。这个数据集是专门为可供性感知和轨迹预测任务构建的,规模庞大,场景丰富。
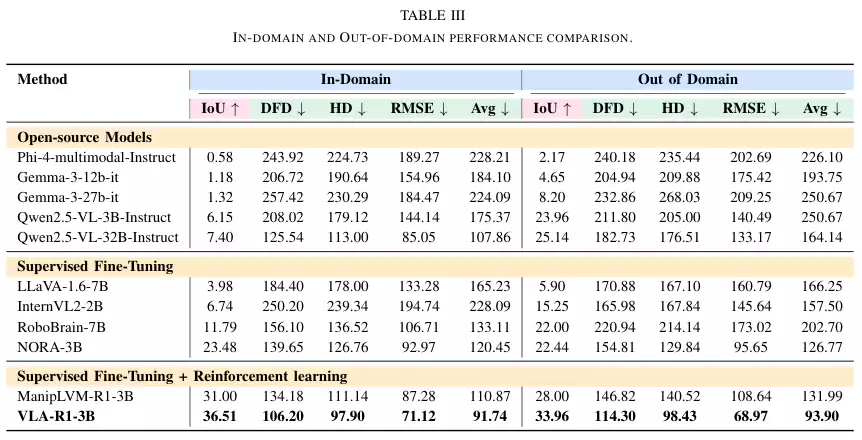
实验结果非常清晰。那些通用的、强大的开源多模态模型,比如Gemma和Phi系列,在这些具身任务上表现不佳。尽管它们参数量巨大,但在定位精度(IoU)上得分低于10,轨迹预测的各项误差(DFD, HD, RMSE)也居高不下。这说明,通用的视觉语言能力并不能直接转化为精确的机器人操作能力。
经过监督微调(SFT)的基线模型,如RoboBrain和NORA,表现有所提升,IoU通常在5到25之间。这证明了针对性训练的有效性。
而VLA-R1-3B的表现则全面领先。它的IoU达到了36.51,轨迹误差的三项指标(DFD, HD, RMSE)分别为106.2, 97.9, 71.12。与同样经过强化学习训练的强基线ManipLVM-R1相比,VLA-R1的IoU提升了17.78%,轨迹误差整体降低了17.25%。
接着是更具挑战性的领域外(Out-of-Distribution, OOD)泛化能力测试。模型需要处理它在训练中从未见过的数据。结果显示,VLA-R1的优势更加明显。在可供性任务上,它的IoU达到了33.96。在轨迹预测任务上,三项误差指标甚至比领域内测试时还要低。这证明VLA-R1学到的不仅仅是死记硬背训练数据,而是真正掌握了可泛化的推理能力。

随后,实验进入了模拟环境。研究团队使用RoboTwin模拟器,在一个每次都会随机变化的桌面环境中测试模型的性能。他们测试了两种不同的机器人(Piper和UR5),以检验模型的跨平台通用性。

尽管模拟环境的变化比训练数据更大,VLA-R1依然表现出色。在可供性感知任务上,它的平均成功率(Success Rate, SR)为55%。在轨迹执行任务上,平均成功率更是达到了70%。相比之下,基线模型NORA的表现则差很多,尤其是在轨迹任务上,几乎完全失败。这证实了VLA-R1在动态变化的环境中,依然能保持强大的稳定性和泛化能力。
最后,也是最关键的,是真实世界实验。研究团队在真实的桌面上设置了四个典型场景,包括拾取特定颜色的碗、从多个相同水果中挑选一个、在有遮挡的厨房场景中操作,以及包含多种干扰物的混合场景。

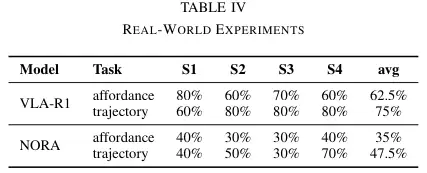
在这些充满不确定性的真实环境中,VLA-R1再次证明了自己。在可供性感知任务上,它的平均成功率约为62.5%,在轨迹预测任务上,平均成功率高达75%。而基线模型NORA-3B在这两项任务上的成功率分别只有35%和47.5%。研究团队发现,颜色相近、位置变化等因素是导致错误的主要原因。即便如此,VLA-R1在失败的情况下,其预测也通常集中在目标物体附近,而不是完全离谱,显示出了一定的容错和自我纠正能力。
为了彻底搞清楚思维链(CoT)和强化学习(RL)各自的贡献,研究团队还进行了一项消融研究。他们测试了三种配置:没有CoT和RL的模型,只有CoT的模型,以及同时使用CoT和RL的完整版VLA-R1。
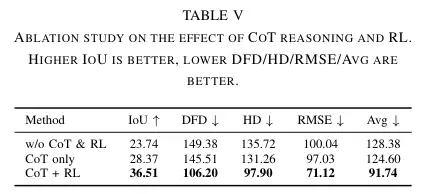
结果如表所示,每一步的改进都清晰可见。单独加入CoT,就能让模型的定位精度(IoU)从23.74提升到28.37,这说明思维链对于帮助模型理解属性、消除歧义至关重要。而当CoT和RL结合后,所有指标都获得了巨大提升。这完美地证明了两者是互补的:思维链提供了结构化的任务分解和推理框架,而强化学习则利用精细的奖励信号来打磨和完善具体的执行策略,最终实现了1+1>2的效果。
目前,所有的开发和验证工作都集中在单臂机器人上。未来,将这套方法扩展到更复杂的机器人平台,比如双臂协作机器人,或者能行走的四足机器狗,将是一个重要的研究方向。
这项研究清晰地表明,让机器人学会像人一样先思考再行动,是通往通用物理世界AI的必由之路。
相关攻略

Excel筛选功能能高效处理海量数据。基础筛选通过列标题下拉菜单勾选或搜索快速定位数据。高级筛选需设置条件区域,可满足多条件复杂查询。FILTER函数能实现动态自动化筛选,结果随数据源同步更新。掌握这些方法可显著提升数据处理效率。

Excel表格可通过多种方法美化以提升可读性。使用内置表格样式可一键快速套用格式;通过设置单元格格式能自定义边框与填充颜色;利用条件格式可根据数据规则自动突出显示特定内容。这些技巧能有效增强数据呈现的清晰度与专业性。

Excel提供了多种批量删除数据的方法。使用Ctrl键配合鼠标可选择不连续区域并右键删除;选中连续区域后按Delete键可快速清空内容。通过“开始”选项卡中的“清除”功能,可同时移除格式与内容。对于复杂任务,可利用VBA宏编写脚本,一键清空所有工作表数据。根据需求选择合适方法能提升效率。

面对表格数据,手动计算易错低效。掌握自动汇总技巧能显著提升效率。常用方法包括:利用筛选功能快速提取和查看特定数据;使用基础的SUM函数进行灵活求和;创建数据透视表进行多维度交互式分析;运用COUNTIF、SUMIF等条件统计函数实现智能计算。根据场景选用合适工具,可使数据处理变得轻松高效。

Excel表格合并有多种方法。复制粘贴适合简单任务;合并计算可汇总多区域数据;PowerQuery能处理复杂合并与数据清洗;CONCATENATE和TEXTJOIN函数专用于合并单元格文本;VBA宏可实现重复任务的自动化。根据数据规模、频率和复杂度选择合适工具,能显著提升数据整理的效率与准确性。
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构