牛剑港大联合发布ELIP:多模态检索超CLIP,视觉语言预训练新突破
来自牛津大学VGG实验室、香港大学和上海交通大学的联合研究团队在最新论文中提出了一种创新方法,能够利用学术界的有限计算资源来强化视觉语言大模型的预训练性能,从而在图文检索任务中获得更精准的匹配效果。
多模态图文检索作为计算机视觉与跨模态机器学习领域的重要任务,当前业内普遍采用CLIP/SigLIP等视觉语言大模型。这类模型经过海量数据预训练后,在零样本场景下展现出卓越的判别能力。
该论文已被IEEE国际多媒体内容索引大会接收,并荣获最佳论文提名。近期在爱尔兰都柏林举行的会议上,这项研究获得了学术界的广泛关注。

关键技术:大规模预训练模型;视觉语言模型;图像检索系统 项目主页:https://www.robots.ox.ac.uk/~vgg/research/elip/ 论文链接:https://www.robots.ox.ac.uk/~vgg/publications/2025/Zhan25a/zhan25a.pdf 代码仓库:https://github.com/ypliubit/ELIP
方法概述
下图直观展示了ELIP方法的架构设计。该方法的核心理念在于采用两阶段检索机制:首先通过传统的CLIP/SigLIP模型进行初步排序,随后对候选样本进行精细化重排。
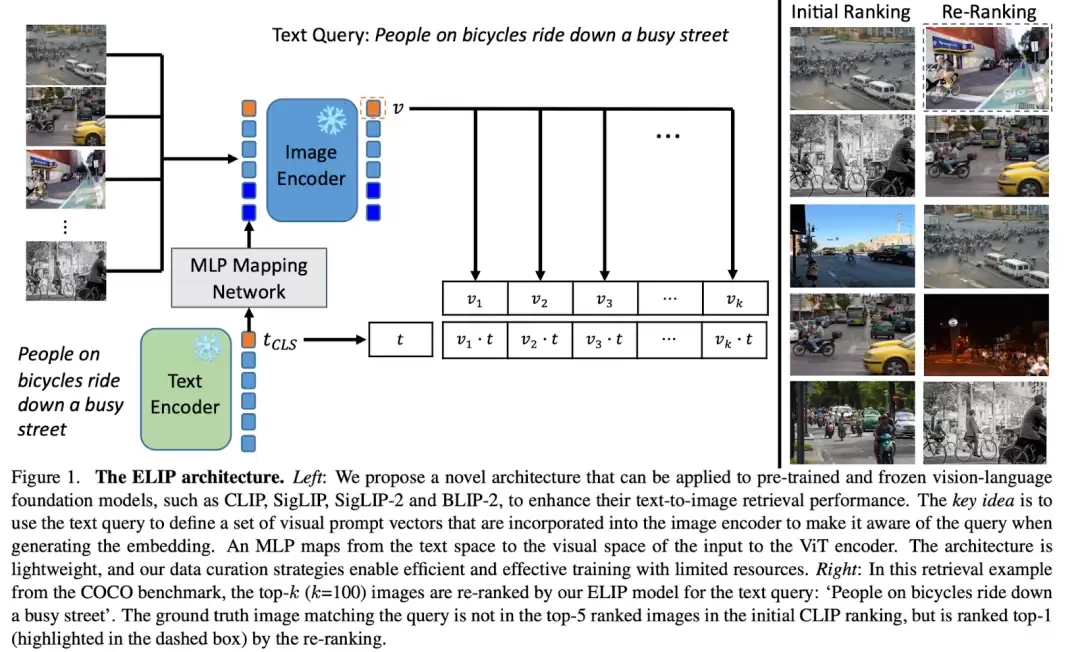
在重排阶段,研究团队设计了一个轻量级的MLP映射网络,将文本特征转化为视觉域的可感知标记。这些标记被注入图像编码器后,使得模型在编码视觉信息时能够同步感知语言语义。经过重新编码的图像特征与文本特征进行对比时,同一查询语句能获得更优化的排序结果。该方法可适配CLIP/SigLIP/SigLIP-2/BLIP-2等主流视觉语言模型,分别形成ELIP-C/ELIP-S/ELIP-S-2/ELIP-B等变体。
学术研究的资源挑战
视觉语言大模型的预训练通常需要工业级计算资源,但这项研究提出的方法使得仅用两张GPU进行训练成为可能。其创新性主要体现在模型架构设计与训练数据构建两个方面。
核心创新:模型架构设计
在模型架构方面,庞大的图像编码器与文本编码器权重保持冻结,仅需训练由三层线性层与GeLU激活函数构成的MLP映射网络。
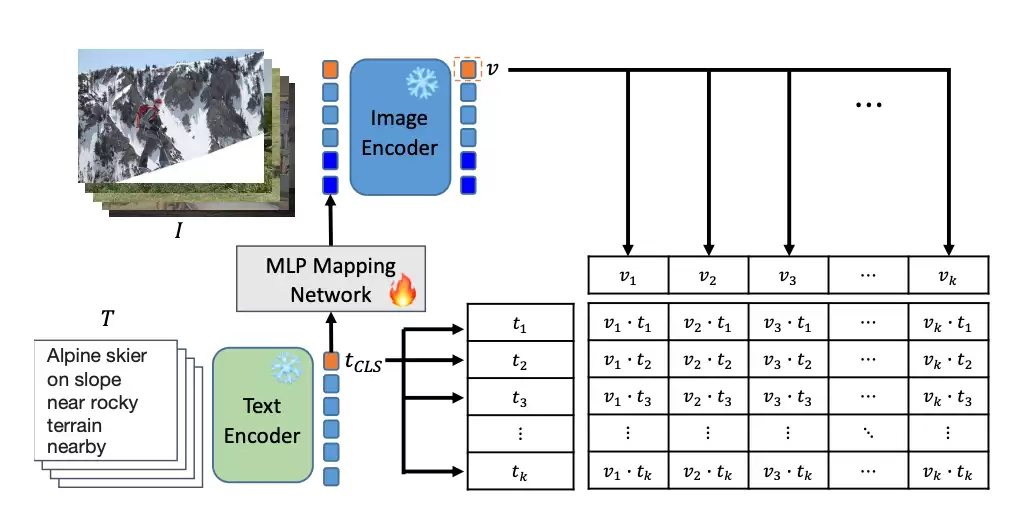
下图展示了ELIP-C与ELIP-S的训练流程。在训练过程中,每个批次的图文对输入模型后,文本特征会被映射到视觉特征空间,从而引导图像信息的编码过程。对于CLIP模型沿用InfoNCE损失函数,而SigLIP模型则采用Sigmoid损失函数,以此对齐文本特征与重新计算的图像特征。
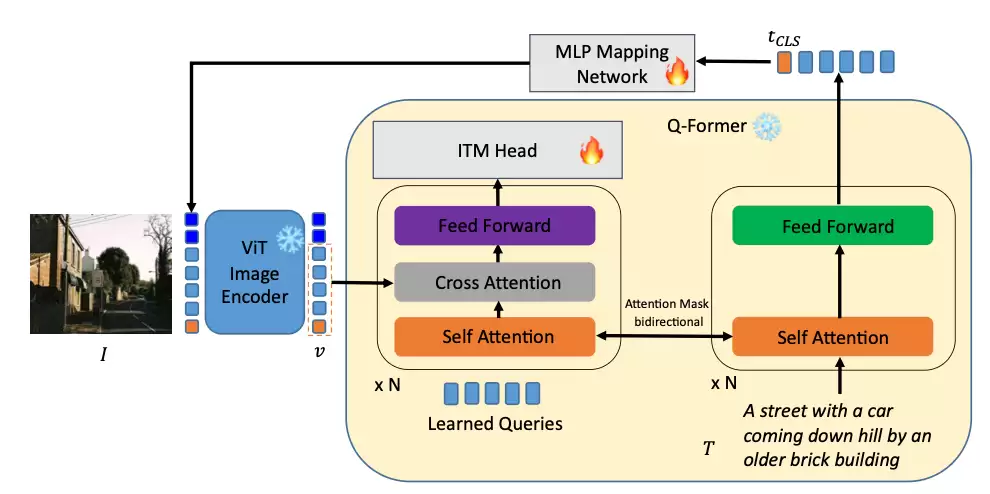
下图呈现了ELIP-B的训练示意图。与CLIP/SigLIP类似,MLP映射网络将文本特征投影到视觉特征空间。独特之处在于,由文本引导生成的图像特征会输入Q-Former模块与文本进行交叉注意力计算,最终通过ITM头部预测图文匹配程度。ELIP-B训练时采用BLIP-2的BCE损失函数。
核心创新:训练数据构建
在训练数据层面,学术界进行大模型训练面临的主要挑战在于GPU数量有限,无法采用大规模批次进行训练,这可能导致模型分辨能力下降。而ELIP方法需要区分CLIP/SigLIP排序生成的困难样本,对模型判别力提出了更高要求。为解决这一难题,研究团队在训练时预先计算每张训练图片及其对应文字标题的CLIP特征,然后将特征相似的图文对聚集在一起形成困难样本训练批次。下图展示了聚合后的训练批次示例:首行样本的描述文字分别为“无底座的木制餐桌”“带折叠桌腿的木质餐桌”“金属底座配橄榄木桌面的桌子”“放置于沥青路面上的户外小桌”;第二行样本描述包括“山涧中漂浮的巨大蓝色冰体”“从悬崖崩落的大块冰川”“地面上碎裂的玻璃残片”“群山环抱的森林水域”。
创新评估基准
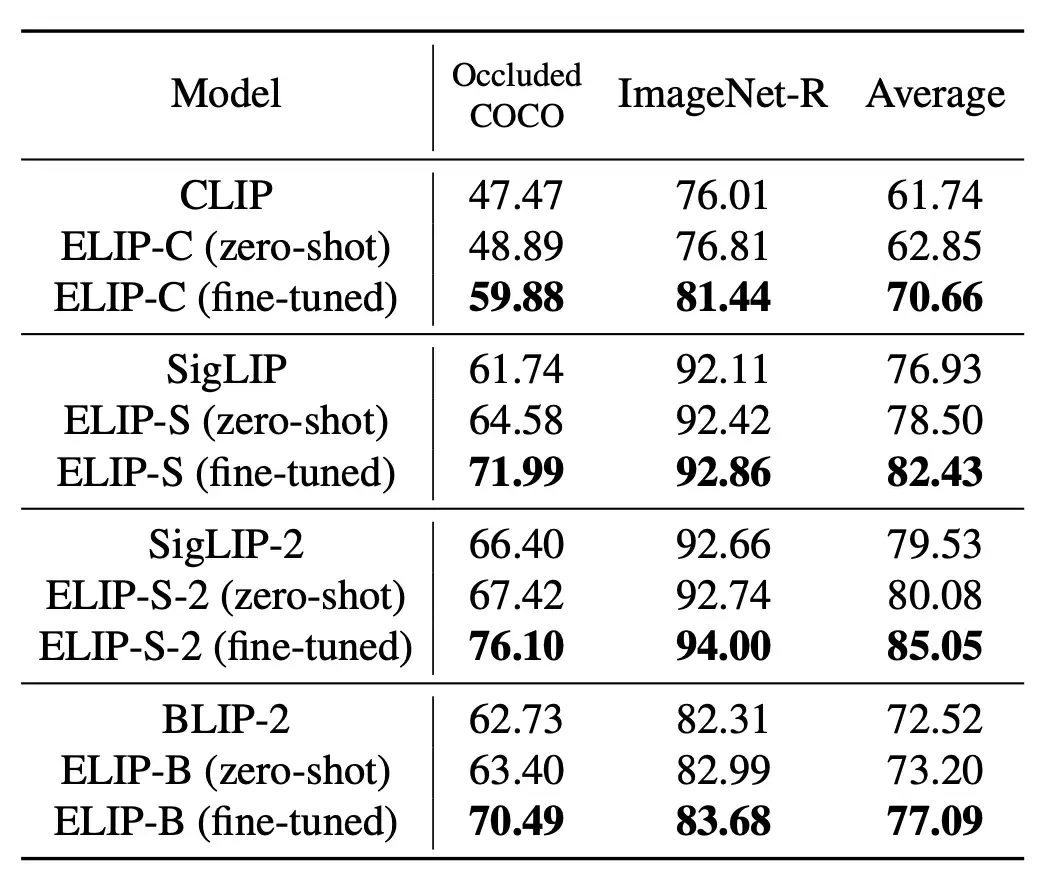
除在COCO、Flickr等标准测试集上进行评估外,研究团队还提出了两个新的分布外测试集:遮挡COCO和ImageNet-R。
在遮挡COCO数据集中,正样本包含文字描述的物体(通常被部分遮挡),负样本则不包含所述物体。对于ImageNet-R数据集,正样本包含文字描述的物体,但这些物体来自非常见领域,负样本则不含对应物体。下图展示了具体案例:首行为正样本,次行为负样本。在遮挡COCO中,正样本包含被遮挡的自行车,负样本不含自行车;在ImageNet-R中,正样本包含金鱼,负样本不含金鱼。

实验结果
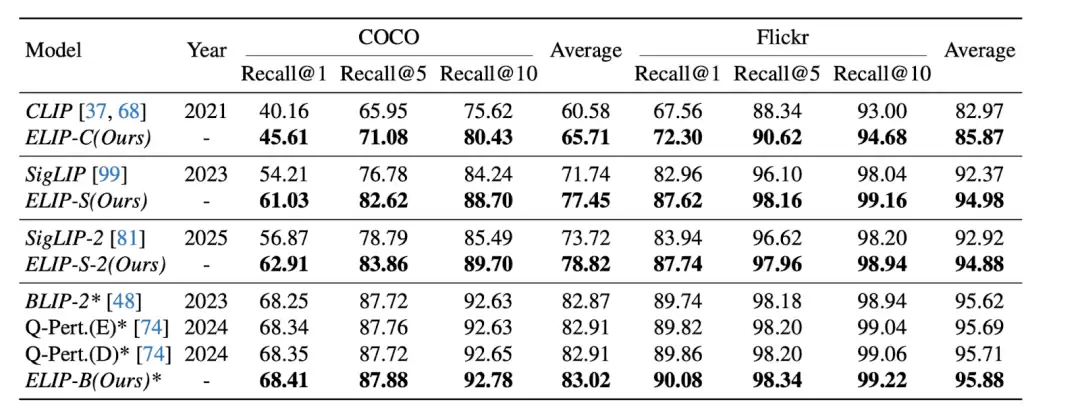
如下表所示,应用ELIP方法后,CLIP/SigLIP/SigLIP-2在图像检索任务上的表现均实现显著提升,其中SigLIP系列模型甚至达到了与BLIP-2相近的水平。ELIP-B在BLIP-2上的应用也显著提升了模型性能,超越了最新的Q-Pert方法。
在分布外测试集上,ELIP系列模型均实现了零样本泛化能力的提升。若在对应领域进行微调——例如在COCO数据集上对遮挡COCO任务微调,在ImageNet数据集上对ImageNet-R任务微调,还能获得更显著的性能提升。这进一步表明ELIP方法不仅能增强预训练效果,还提供了一种高效的自适应机制。
通过可视化注意力图可观察到,当文本查询与图像内容相关时,ELIP能提升图像编码器对文本描述相关区域的关注度。

更多技术细节详见论文原文。
相关攻略

Excel筛选功能能高效处理海量数据。基础筛选通过列标题下拉菜单勾选或搜索快速定位数据。高级筛选需设置条件区域,可满足多条件复杂查询。FILTER函数能实现动态自动化筛选,结果随数据源同步更新。掌握这些方法可显著提升数据处理效率。

Excel表格可通过多种方法美化以提升可读性。使用内置表格样式可一键快速套用格式;通过设置单元格格式能自定义边框与填充颜色;利用条件格式可根据数据规则自动突出显示特定内容。这些技巧能有效增强数据呈现的清晰度与专业性。

Excel提供了多种批量删除数据的方法。使用Ctrl键配合鼠标可选择不连续区域并右键删除;选中连续区域后按Delete键可快速清空内容。通过“开始”选项卡中的“清除”功能,可同时移除格式与内容。对于复杂任务,可利用VBA宏编写脚本,一键清空所有工作表数据。根据需求选择合适方法能提升效率。

面对表格数据,手动计算易错低效。掌握自动汇总技巧能显著提升效率。常用方法包括:利用筛选功能快速提取和查看特定数据;使用基础的SUM函数进行灵活求和;创建数据透视表进行多维度交互式分析;运用COUNTIF、SUMIF等条件统计函数实现智能计算。根据场景选用合适工具,可使数据处理变得轻松高效。

Excel表格合并有多种方法。复制粘贴适合简单任务;合并计算可汇总多区域数据;PowerQuery能处理复杂合并与数据清洗;CONCATENATE和TEXTJOIN函数专用于合并单元格文本;VBA宏可实现重复任务的自动化。根据数据规模、频率和复杂度选择合适工具,能显著提升数据整理的效率与准确性。
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构