DAPO 是由字节跳动和清华大学联合推出。在 AIME 2024 竞赛中取得了 50 分的成绩,超越了之前的先进模型,且仅用了 50% 的训练步骤。这充分展示了它在训练效率和效果上的显著优势。更值得一提的是,DAPO 完全开源。

大家好,我是肆〇柒。看到一款开源的强化学习算法,这是由字节跳动、清华大学 AIR 研究所等机构联合推出的开源强化学习算法 ——DAPO。目前在 AI 领域,大型语言模型(LLM)的推理能力正以前所未有的速度发展,而强化学习(RL)作为其核心优化技术,扮演着至关重要的角色。然而,现有顶级推理模型的技术细节往往难以获取,这使得广大研究人员和开发者在复现和进一步探索时面临重重困难。在这样的背景下,研究人员提出了 DAPO 并开源。下面一起了解下。
LLM 推理能力的演进
在早期,LLM 的推理能力主要集中在简单的逻辑推理和事实性问题的回答上。例如,对于一些基于常识的问题,如“太阳从哪个方向升起?”模型能够给出准确的答案。然而,随着技术的发展,LLM 开始能够处理更复杂的任务,如解决数学问题和编写代码。这一进步的关键在于测试时扩展(Test-time scaling)技术的引入,尤其是 Chain-of-Thought(思考链)方式的广泛应用。
思考链技术通过模拟人类的逐步思考过程,使 LLM 能够进行更复杂的推理。例如,在解决数学问题时,模型会逐步分解问题,逐步求解,最终得出答案。这种技术不仅提高了模型的准确性,还使其能够处理更复杂的任务。例如,在解决一个复杂的几何问题时,模型会先列出已知条件,然后逐步推导出未知条件,最终得出答案。
然而,在不同的推理场景下,LLM 的表现仍存在差异。例如,在处理长推理链条(Long CoT)任务时,模型往往面临更大的挑战。这是因为长CoT任务需要模型在生成过程中保持逻辑连贯性和准确性,同时避免因生成过长文本而引入噪声。例如,在解决一个复杂的数学竞赛题目时,模型可能需要生成长达数千个 token 的推理过程,这不仅对模型的生成能力提出了挑战,还对模型的逻辑连贯性提出了更高的要求。
强化学习在 LLM 中的应用挑战
强化学习(RL)在提升 LLM 推理能力方面具有重要作用,但同时也面临着诸多挑战。例如,熵崩溃(Entropy Collapse)是一个常见问题,即模型在训练过程中逐渐失去探索能力,生成的文本变得单一和确定性。这不仅限制了模型的探索能力,还可能导致模型在面对复杂任务时无法找到最优解。
以熵崩溃为例,当模型在训练过程中过于依赖某些高频词汇或模式时,会导致生成的文本缺乏多样性。例如,在解决一个复杂的数学问题时,模型可能会反复生成相同的解题步骤,而无法探索其他可能的解题路径。这不仅限制了模型的探索能力,还可能导致模型在面对复杂任务时无法找到最优解。
此外,奖励噪声(Reward Noise)和训练不稳定(Training Instability)等问题也严重影响了模型的训练效果。例如,在训练过程中,模型可能会因为奖励信号的不稳定性而出现训练不稳定的情况。这不仅影响了模型的训练效果,还可能导致模型在训练过程中出现性能波动。
现有的强化学习算法,如近端策略优化(PPO)和组相对策略优化(GRPO),在处理长 CoT 任务时也存在局限性。例如,PPO 在处理长文本生成时容易出现梯度消失问题,而 GRPO 则在奖励分配上存在不足。这不仅影响了模型的训练效果,还限制了模型在长 CoT 任务中的表现。
DAPO 算法简介
算法核心架构
DAPO 算法的核心框架在传统强化学习算法的基础上进行了多项改进。其基本输入是问题-答案对,输出是经过优化的策略模型。DAPO 的核心计算流程包括采样、奖励计算、优势函数估计和策略更新。
与 GRPO 相比,DAPO 在优势函数计算和策略更新方式上进行了关键改进。例如,DAPO 引入了解耦的裁剪策略(Clip-Higher),通过分别设置上下限裁剪范围(εlow 和 εhigh),有效提升了策略的多样性。此外,DAPO 还引入了动态采样机制,通过动态调整采样数量,确保每个样本都携带有效的梯度信息。
四大核心技术
Clip-Higher 策略是 DAPO 的一项重要创新。通过解耦上下限裁剪范围,该策略为低概率 token 的概率提升提供了更多空间。当 εlow 设置为 0.2,εhigh 设置为 0.28 时,模型在训练过程中能够更好地平衡探索和利用。
从数学公式来看,Clip-Higher 的策略更新公式如下:

通过实验数据可以看出,使用 Clip-Higher 策略后,模型的熵显著增加,生成的样本更加多样化。例如,在 AIME 2024 的测试中,使用 Clip-Higher 的模型在训练初期就能生成多种不同的解题路径。这不仅提高了模型的探索能力,还为模型在复杂任务中的表现提供了更多的可能性。
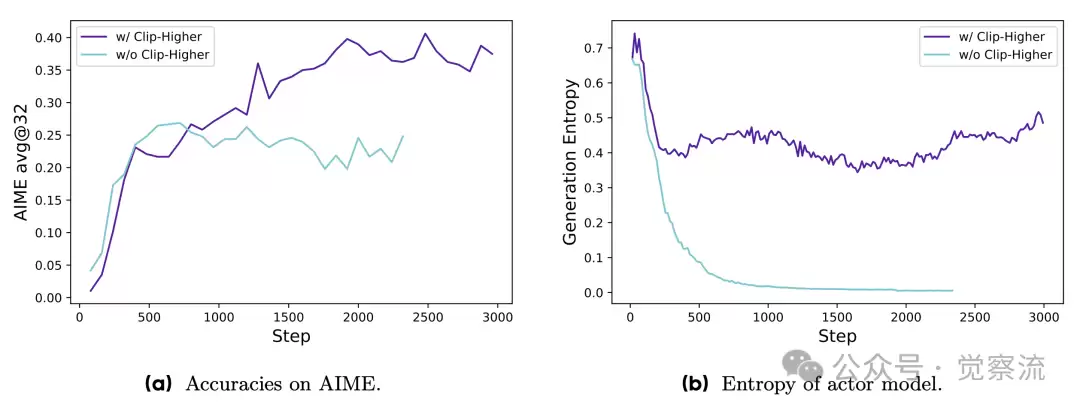
在应用Clip-Higher策略之前和之后,在AIME测试集上的准确率以及在强化学习训练过程中actor模型生成概率的熵
动态采样机制解决了现有 RL 算法中因部分样本奖励值固定导致梯度消失的问题。在训练过程中,DAPO 会动态调整采样数量,确保每个样本都携带有效的梯度信息。
DAPO 在采样时会先筛选出那些奖励值为 0 或 1 的样本,然后从剩余样本中进行采样。这种策略在提高样本效率的同时,还稳定了梯度更新。
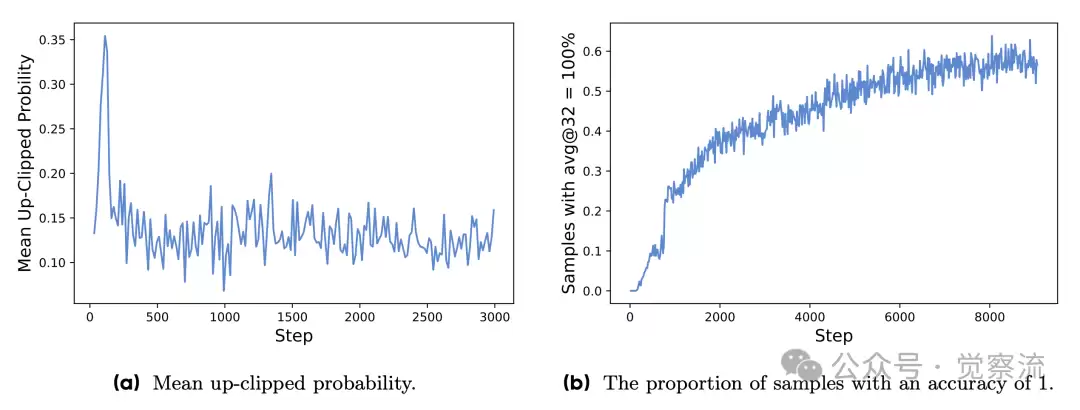
平均上裁剪概率以及准确度为1的提示的比率
筛选的具体算法步骤如下:
1. 对于每个批次的样本,计算每个样本的奖励值。
2. 筛选出奖励值为 0 或 1 的样本。
3. 从剩余样本中进行采样,直到采样数量达到预设的阈值。
4. 根据训练过程中的情况,动态调整采样数量和筛选条件。
实验数据显示,使用动态采样机制后,模型的训练收敛速度明显加快。例如,在 AIME 2024 的测试中,使用动态采样的模型在相同训练步骤下,性能比未使用该机制的模型高出 10%。
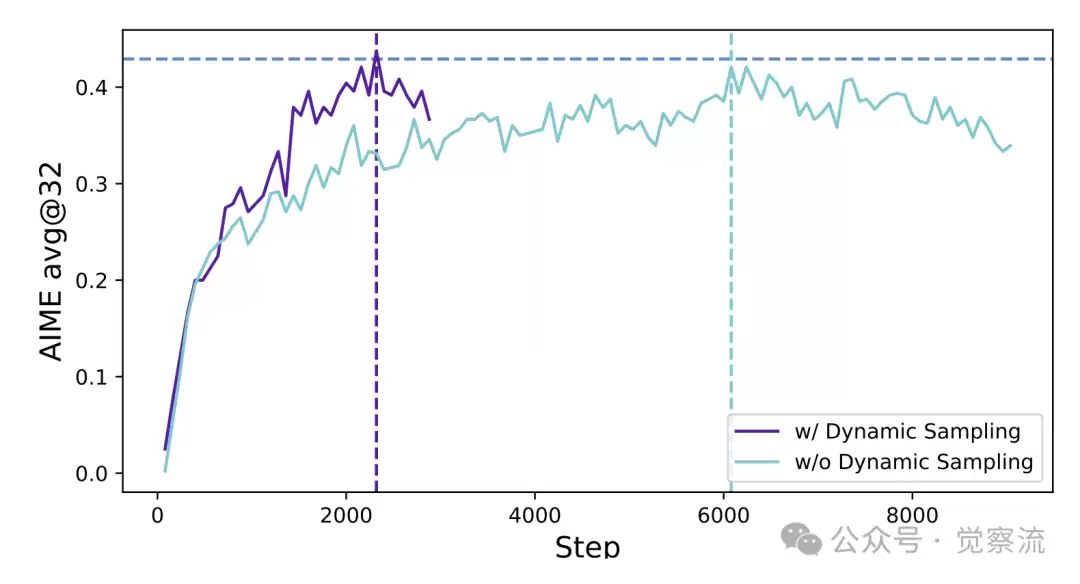
在基线设置中应用动态采样前后的训练进度
Token 级策略梯度损失(Token-level Policy Gradient Loss)
在长 CoT 推理场景下,传统的样本级损失计算方式存在弊端。例如,对于长序列样本,关键 token 的更新可能不足,导致模型生成低质量的长文本。
DAPO 引入了 Token 级策略梯度损失,使每个 token 的更新更精准地依赖其对奖励的贡献。具体公式如下:
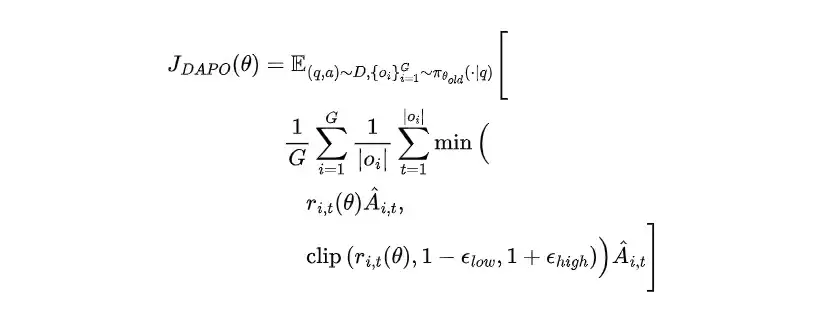
这种损失计算方式使长序列中的每个 token 都能得到有效的更新,从而提高了模型生成文本的质量。
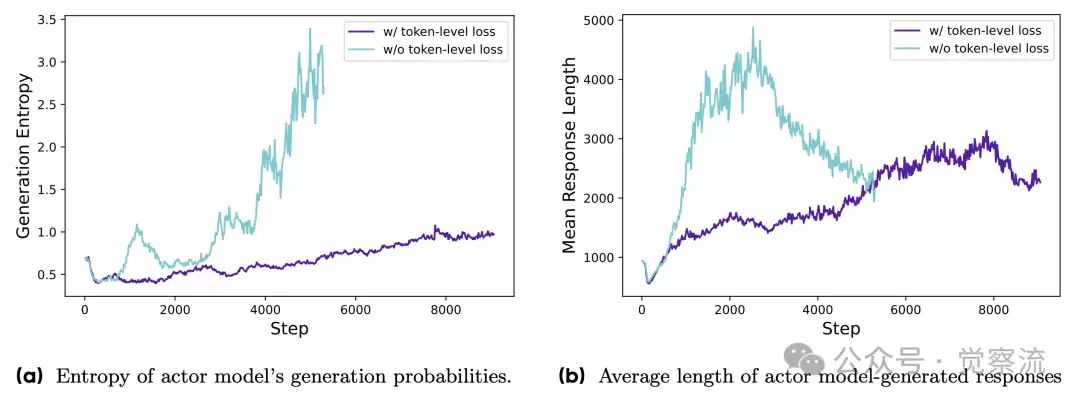
actor模型的概率分布的熵,以及响应长度的变化
过长奖励塑性(Overlong Reward Shaping)
在 RL 训练中,截断样本可能引入奖励噪声,误导模型。DAPO 引入了过长过滤(Overlong Filtering)和软过长惩罚(Soft Overlong Punishment)两种方法来解决这一问题。
过长过滤会忽略截断样本的损失,而软过长惩罚则会根据响应长度动态调整惩罚力度。例如,当响应长度超过预设的最大值时,模型会受到惩罚,从而引导模型生成长度适中的推理过程。软过长惩罚的具体公式如下:
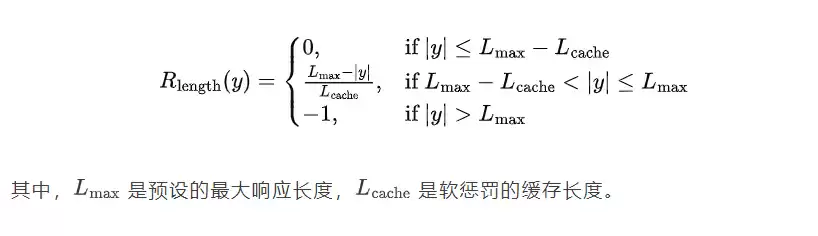
实验数据显示,使用过长奖励塑性后,模型在 AIME 2024 的测试中表现更加稳定,性能提升了 5%。
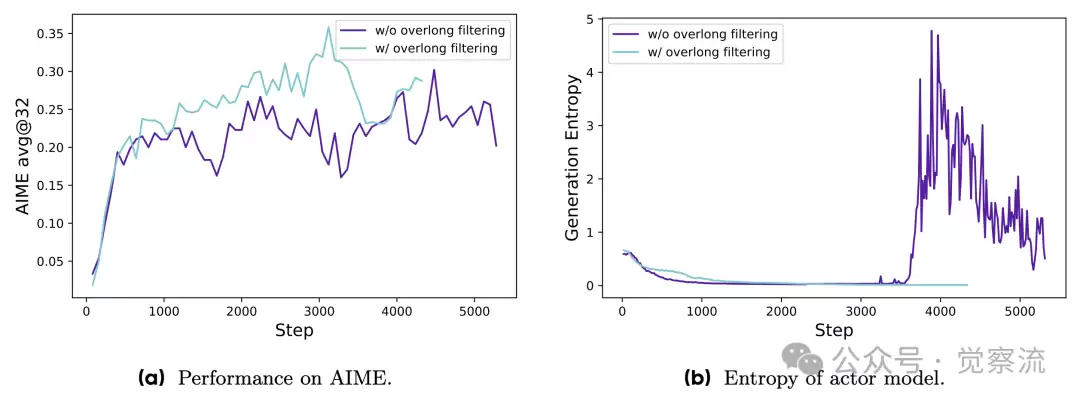
在应用“过长奖励塑形策略”之前和之后,actor模型在AIME上的准确率以及其生成概率的熵
实验验证与成果
实验设置
在 DAPO 的实验中,研究人员精心选择了预训练模型、训练框架、优化器以及超参数,以确保算法能够在复杂的推理任务中表现出色。实验采用的预训练模型是 Qwen2.5-32B,这是一个具有 320 亿参数的大型语言模型,以其强大的语言生成能力而闻名。训练框架基于 verl,一个高效且灵活的强化学习框架,能够支持大规模的训练任务。优化器选择了 AdamW,这是一种广泛使用的优化算法,以其良好的收敛性能和稳定性而受到青睐。学习率设置为 1×10^-6,并在前 20 个 rollout 步骤中进行线性 warm-up,以确保模型在训练初期能够平稳地更新参数。
为了评估模型的推理能力,研究人员构建了 DAPO-Math-17K 数据集,这是一个包含 17,000 个数学问题的数据集,每个问题都配有整数形式的答案。这个数据集的构建过程非常严谨,数据来源包括 AoPS 和最新竞赛主页。通过对原始问题答案的转换,研究人员确保了数据集能够适配规则奖励模型,从而为模型提供了准确的奖励信号。
关键实验结果
DAPO 在 AIME 2024 竞赛中的表现尤为引人注目。它在该竞赛中取得了 50 分的成绩,这一成绩不仅超越了先前的顶级模型 DeepSeek-R1-Zero-Qwen-32B(47 分),而且仅用了 50% 的训练步骤就达到了这一成绩。这一结果充分展示了 DAPO 在训练效率和效果上的显著优势。

应用于DAPO的渐进技术的主要成果
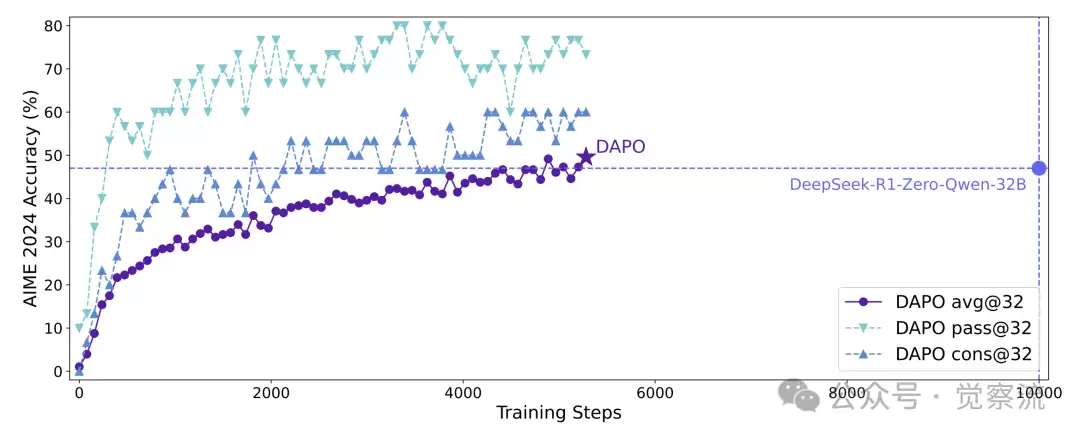
在Qwen2.5-32B基础模型上,DAPO的2024年AIME分数超过了之前使用50%训练步数的最先进水平DeepSeekR1-Zero-Qwen-32B。X轴表示梯度更新步数
从学习曲线来看,DAPO 在训练过程中展现出了快速的性能提升。在训练初期,模型的准确率迅速上升,这得益于 DAPO 算法在策略更新和奖励分配上的创新设计。随着训练的进行,模型的准确率逐渐趋于稳定,但始终保持着较高的水平。
通过表格形式的分析,我们可以看到 DAPO 的每个技术组件都对模型性能的提升做出了显著贡献。例如,Clip-Higher 策略为模型带来了 8 分的性能提升,动态采样机制带来了 6 分的提升,Token 级策略梯度损失带来了 4 分的提升,而过长奖励塑性则带来了 2 分的提升。这些技术组件的协同作用,使得 DAPO 在复杂的推理任务中表现出色。
在训练过程中,DAPO 的各项指标也展现出了良好的趋势。生成文本的长度随着训练的进行而稳步增加,这表明模型在不断探索更复杂的推理路径。奖励分数的稳定提升则表明模型在逐渐适应训练分布,能够生成更符合要求的推理过程。生成概率均值和熵的变化趋势也反映了模型在训练过程中的稳定性和多样性。
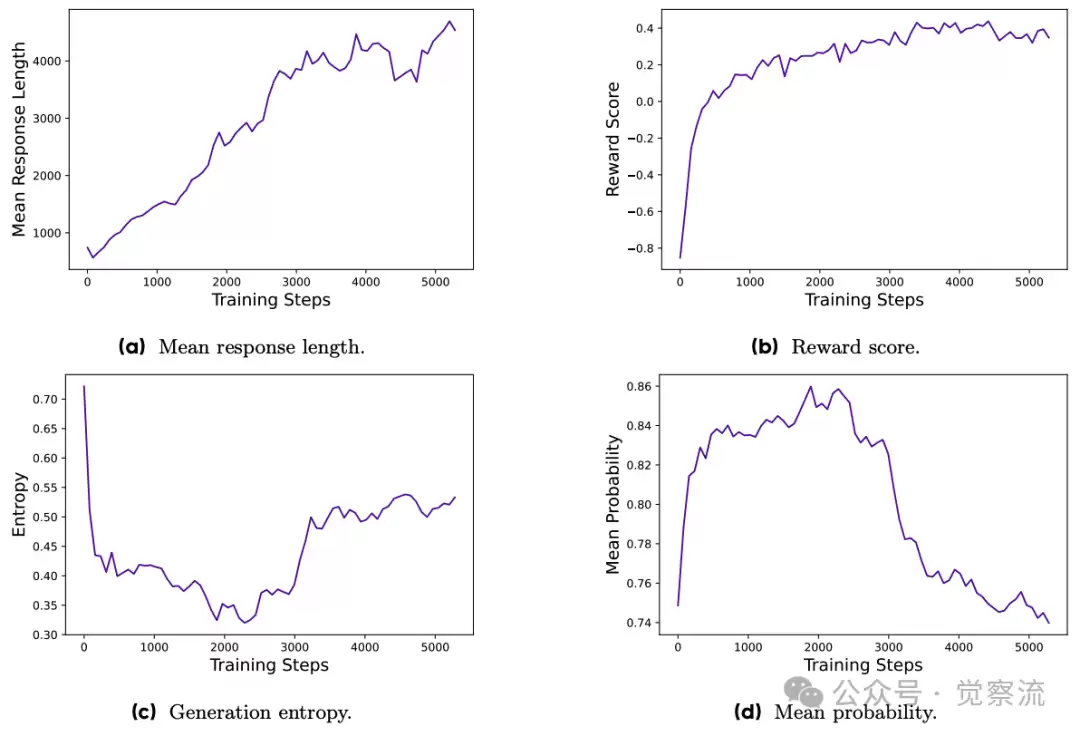
响应长度、奖励分数、生成熵以及DAPO平均概率的度量曲线,展示了强化学习训练的动态过程,并作为关键的监控指标来识别潜在问题
模型推理动态演变
在强化学习训练过程中,DAPO 模型的推理模式发生了显著的动态变化。以具体的数学问题求解为例,模型从初期缺乏反思行为,逐渐发展到后期能够主动进行步骤验证与回溯。这种转变不仅提升了模型的推理准确性,还展示了 DAPO 算法在激发和塑造模型推理能力方面的强大作用。

强化学习中反思行为的出现
例如,在解决一个复杂的几何问题时,模型在训练初期可能只是简单地列出已知条件和目标,而没有进行深入的分析和验证。然而,随着训练的进行,模型开始在推理过程中加入更多的验证步骤,如检查中间结果的合理性、回溯错误的推理路径等。这种动态演变不仅提高了模型的推理能力,还为研究人员提供了深入理解模型学习过程的窗口。
从生成文本长度、奖励分数、生成概率均值与熵等指标的变化趋势来看,这些动态变化反映了模型学习状态与性能提升的轨迹。生成文本长度的增加表明模型能够生成更复杂的推理过程,奖励分数的提升则表明模型的推理结果更加符合要求。生成概率均值和熵的变化则反映了模型在训练过程中的稳定性和多样性,这些指标的健康变化为模型的性能提升提供了有力支持。

一种反思性行为出现的例子
开源生态构建与实践
开源内容全景概览
DAPO 开源项目为研究人员和开发者提供了丰富的资源,包括算法代码、训练基础设施以及数据集。这些资源的开源,不仅降低了参与 LLM 强化学习研究的门槛,还为社区的协作和创新提供了坚实的基础。
开源项目基于 verl 框架实现,具有高效、灵活的特点。项目结构清晰,关键模块如算法实现、数据处理脚本等都易于定位和使用。这使得研究人员可以快速上手,进行算法的修改和扩展。
环境搭建与模型推理示例
为了帮助研究人员和开发者快速搭建实验环境,DAPO 提供了详细的环境配置指南。推荐使用 conda 创建独立的 Python 环境,并安装所需的依赖包。在安装过程中,需要注意一些常见的问题,如依赖包版本不匹配等,并根据实际情况进行调整。
模型推理代码示例也提供了详细的说明,关键参数如温度值、top_p 等的作用和设置建议都得到了清晰的解释。通过这些示例,研究人员可以在本地顺利运行模型,并对模型的推理过程和结果进行直观的感受。
以具体的数学问题求解为例,模型的输入输出示例展示了模型生成推理过程的特点和优势。例如,在解决一个复杂的代数问题时,模型不仅能够生成正确的答案,还能详细地列出解题步骤,展示其推理过程的逻辑性和连贯性。
AIME 2024 评估部署
为了评估 DAPO 模型在 AIME 2024 上的表现,研究人员提供了详细的部署指南。利用Ray Serve和 vLLM,研究人员可以方便地部署模型,并进行高效的评估。
从Hugging Face加载模型和从本地加载模型的方法都有详细的说明,评估脚本的参数说明和运行示例也提供了清晰的指导。通过这些指南,研究人员可以准确地复现评估过程,并根据评估结果分析模型的优势和改进空间。
评估指标的计算方式和结果解读方法也得到了详细的介绍。例如,准确率的计算不仅考虑了最终答案的正确性,还考虑了解题步骤的合理性。通过这些详细的评估指标,研究人员可以全面地了解模型的性能。
训练复现路径指引
DAPO 提供了完整的训练复现脚本,包括简化版和完整版。这些脚本的功能、适用场景和运行前提条件都得到了详细的说明。在不同版本的 verl 下,训练过程的验证情况也得到了清晰的阐述,为研究人员顺利复现训练过程提供了可靠的保障。
研究人员还可以利用开源的数据集和训练代码,开展定制化的训练实验。例如,通过加载和预处理 DAPO-Math-17k 数据集,研究人员可以根据自己的需求配置训练参数,探索个性化的 LLM 强化学习解决方案。
代码示例展示了如何加载和预处理数据集,以及如何配置训练参数以适应不同的实验需求。通过这些示例,研究人员可以更好地理解训练过程,并进行有效的实验设计。




