疫情微博情绪识别挑战赛Baseline(PaddlePaddle)-0.9735
本文围绕疫情微博情绪识别挑战赛展开,介绍赛事背景、任务、评审规则等。采用预训练模型+微调方式,通过Multi-dropout和不同特征池化方案优化,从小模型到参数大的模型实验,结合模型融合策略,最终ernie-3.0-base-zh单模线上成绩达0.9735,为情绪识别提供有效方案。

疫情微博情绪识别挑战赛
疫情微博情绪识别挑战赛
举办方:科大讯飞xDatawhale
赛事地址:疫情微博情绪识别挑战赛-点击直达
赛事背景
疫情发生对人们生活生产的方方面面产生了重要影响,并引发了国内舆论的广泛关注,众多网民也参与到了疫情相关话题的讨论中。大众日常的情绪波动在疫情期间会放大,并寻求在自媒体和社交媒体上发布和评论。
为了掌握真实社会舆论情况,科学高效地做好防控宣传和舆情引导工作,针对疫情相关话题开展网民情绪识别是重要任务。本次我们重点关注微博平台上的用户情绪,希望各位选手能搭建自然语言处理模型,对疫情下微博文本的情绪进行识别。
赛事任务
本次赛题需要选手对微博文本进行情绪分类,分为正向情绪和负面情绪。数据样例如下:
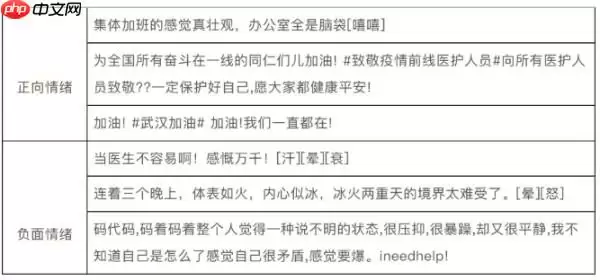
评审规则
数据说明赛题数据由训练集和测试集组成,训练集数据集读取代码:
import pandas as pd pd.read_csv('train.csv',sep='\t')登录后复制评估指标本次竞赛的评价标准采用准确率指标,最高分为1。 计算方法参考地址:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html
评估代码参考:
import sklearn.metrics import accuracy_score y_pred = [0,2,1,3] y_true = [0,1,2,3] accuracy_score(y_pred,y_true)登录后复制评测及排行
1、赛事提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
2、每支团队每天最多提交3次。
3、排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
作品提交要求
文件格式:预测结果文件按照csv格式提交
文件大小:无要求
提交次数限制:每支队伍每天最多3次
预测结果文件详细说明:
以csv格式提交,编码为UTF-8,第一行为表头;
标签顺序需要与测试集文本保持一致;
提交前请确保预测结果的格式与sample_submit.csv中的格式一致。具体格式如:
label 1 1 1 1登录后复制
赛程安排
正式赛:6月24日——7月23日
初赛截止成绩以团队在初赛时间段内最优成绩为准,具体排名可见初赛榜单。
初赛作品提交截止日期为7月23日17:00;正式赛名次将于结束后15天内公布。
长期赛:7月24日——10月24日
正式赛结束后,将转变为长期赛,供开发者学习实践。本阶段提交后,系统会根据成绩持续更新长期赛榜单,但该阶段榜单不再进行奖励。
Baseline思路
情感分析是一个经典的文本分类任务,初始Baseline采用预训练模型+微调下游任务的方式搭建
通过两种策略优化Baseline方法得到一个强基线的Baseline方案
策略一:Mutli-dropout
策略二:比较不同的特征池化方案,选取更合适的特征池化方法
先使用参数少的小模型(erbie-3.0-nano)得到初步的最优组合方案,再更换参数大的(erbie-3.0-base)模型结合最优策略得到较强的单模结果。
Baseline 效果
由于提交次数宝贵,因此仅提交了其中三份结果进行验证
一是小模型上验证效果最好(0.963)的单模结果
二是小模型上多模型融合的结果
三是切换为大模型(ernie-3.0-base-zh)的单模效果
从结果上看:
Mutlidropout策略十分有效,在不同池化策略的基础上添加Mutlidropout验证效果均有明显涨分嵌入策略上动态加权池化方法效果最优,其次是平均池化策略基于Voting的模型融合策略也可以提升模型的性能更换base版本的大模型后,通过两个策略的加持,线上成绩到达0.9735,靠单模成绩上排行第三,总结:
使用了两种有效的策略(Mutlidropout和动态池化策略)获得一个强基线的baseline,希望对还未提升到0.972分数以上的小伙伴一些启发,基于这个强基线的baseline是可以冲击到0.973等更高的分数。
Baseline项目使用ernie-3.0的nano模型仅72MB,micro和nano版本不超过100MB,对资源要求友好,在当前超参数配置下(最大截断长度200,训练批次大小64)显存占用不到5GB,训练3轮5.4万条样本仅需11分钟左右,取得线上0.9655(Rank35 时间:2024-07-09)
当更换参数量更大的Base模型后,相同配置下显存占用19GB左右,训练时间提升到30分钟。更换Base后的强基线单模线下得到0.9735,进入前五梯队(Rank3 时间:2024-07-09)

后续优化推荐
使用FGM等对抗训练提升模型的鲁棒性使用EMA增加模型在测试集上的健壮性融合不同模型,采用不同的模型融合策略In [ ]
# 将paddlenlp更新至最新版本 !pip install -U paddlenlp # emoji转换成文字 !pip install emojiswitch登录后复制
In [6]
# 测试 emojiswitch 效果 import emojiswitch emojiswitch.demojize('心中千万只登录后复制 相关攻略

直接说结论:使用 post-receive 钩子配合 GIT_WORK_TREE 环境变量,是实现 Git 自动部署最稳定可靠的方案。至于 post-update 钩子或在裸仓库中直接执行 checkout 的方法,强烈建议避免使用——它们不仅容易失败,而且错误信息往往不明确,排查过程极其耗时。 为

柴犬币(SHIB)两年内有望达到0 0001美元?深度解析其路径与挑战 柴犬币(SHIB)两年内有望达到0 0001美元,多家机构预测其2026至2028年可能实现破零,核心动力来自通缩销毁机制、Shibarium网络推动及生态扩展,但面临高流通量、市场竞争和实用性验证等挑战,需结合市场环境与长期发

如果你曾尝试使用Perplexity这类AI工具来学习Git分支管理,但总觉得得到的回答过于笼统、缺乏可操作的细节——例如,它可能只告诉你“使用merge合并分支”,但具体的操作步骤、遇到冲突时的处理方法却语焉不详——那么问题很可能出在你的提问方式上。AI并非真人导师,它需要更精确的指令才能输出有价

配置Git提交模板,本意是让每次提交信息都清晰、规范,但实际操作中,几个隐蔽的“坑”常常让这个功能形同虚设。今天,我们就来把这些坑一个个填平。 路径写错就静默失效,这是第一个大坑 配置项 commit template 对路径的敏感度超乎想象。写错一点,它不会报错,只会默默地“罢工”。结果就是你兴冲

配置 git commit template 来统一团队提交信息的格式,是建立 Git 工作流规范的第一步。然而,如果你认为仅靠一个模板文件就能一劳永逸,那可能陷入了一个常见的误区。实际上,这个配置的作用非常基础:它仅在你不使用 -m 参数、通过编辑器进行交互式提交时,将模板内容预填到提交信息编辑器
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构