【Paddle打比赛】 交通标志分类识别
本文围绕交通标志分类识别竞赛展开,介绍了赛题背景、任务及数据集情况。还阐述了利用PaddleClas套件,通过数据格式化划分、配置MobileNetV3模型、训练评估、导出模型并预测,最终生成结果提交的完整流程与注意事项。

一、【Paddle打比赛】 交通标志分类识别
1.赛题名称
【交通标志分类识别 竞赛 - DataFountain 】 https://www.datafountain.cn/competitions/553
2.赛题背景
目标检测在自动驾驶等方面有着广泛的应用前景,在自动驾驶场景中,需要对交通标志(如限速标志等)进行识别以采取不同的驾驶策略。此赛题旨在使用Oneflow框架识别确定图像中显示的交通标志的类型,并且对不同的环境(如光线、障碍物或标志距离)具有鲁棒性。
3.赛题任务
此赛题的数据集由云测数据提供。比赛数据集中包含6358张真实场景下行车记录仪采集的图片,我们选取其中95%的图片作为训练集,5%的图片作为测试集。参赛者需基于Oneflow框架在训练集上进行训练,对测试集中的交通标志进行分类识别。数据集中一共有10种细分的交通标志标签。
4.数据简介
本赛题的数据集包含6358张人工标注的类别标签。标签包括以下10种类别:“GuideSign”, “M1”, “M4, “M5”, “M6”, “M7”, “P1”, “P10_50”, “P12”, “W1”,分别对应十个不同的交通标识类别。所有数据已经按比例人工划分为了训练集和测试集,并且提供了相关的训练集标注的json文件。
5.数据说明
数据集包含train和test两个文件夹,以及一个统一的train.json文件用来保存所有训练数据集的标注,图片标签将字典以json格式序列化进行保存,所有的标注都保存在train.json文件中的名为annotations的key下,其中每个训练文件都包含以下属性:
P12: 礼让标志P10_50:限速50GuideSing:路牌W1:警告P1:禁停M1:方向指示M4:直行M6:机动车道M6:自行车道M7:人行横道









6.提交要求
参赛者使用Oneflow框架对数据集进行训练后对测试集图片进行推理后,
1.将测试集图片的目标检测和识别结果以与训练集格式保持一致的json文件序列化保存,并上传至参赛平台由参赛平台自动评测返回结果。2.在提交时的备注附上自己的模型github仓库链接。{ “annotations”: [ { “filename”: “test/W1/00123.webp”, # filepath: str “label”: 0 # label: int from 0 to 9 }] }
二、环境准备
飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。此次计划使用端到端的PaddleClas图像分类套件来快速完成分类。
In [ ]# git下载!git clone https://gitee.com/paddlepaddle/PaddleClas.git --depth=1登录后复制
Cloning into 'PaddleClas'...remote: Enumerating objects: 1037, done.remote: Counting objects: 100% (1037/1037), done.remote: Compressing objects: 100% (918/918), done.remote: Total 1037 (delta 332), reused 478 (delta 95), pack-reused 0Receiving objects: 100% (1037/1037), 59.94 MiB | 7.11 MiB/s, done.Resolving deltas: 100% (332/332), done.Checking connectivity... done.登录后复制In [ ]
# PaddleClas安装%cd ~/PaddleClas/!pip install -U pip!pip install -r requirements.txt!pip install -e ./登录后复制
三、数据准备
1.数据解压缩
In [ ]%cd ~!unzip -oq /home/aistudio/data/data125044/road_sign.zip登录后复制In [ ]
!unzip -qoa train_dataset.zip!unzip -qoa test_dataset.zip登录后复制In [ ]
! rm test_dataset.zip! rm train_dataset.zip登录后复制In [2]
from PIL import Imageimg=Image.open("train/P12/00014.webp")img登录后复制登录后复制In [3]
img=Image.open("train/P10_50/00014.webp")img登录后复制登录后复制In [4]
img=Image.open("train/GuideSign/00452.webp")img登录后复制登录后复制
2.数据集格式化 AND 划分
In [ ]%cd ~import jsonimport ostrain_json={}with open('train.json','r') as f: train_json=json.load(f)print(len(train_json["annotations"]))train_f = open('train_list.txt', 'w') eval_f = open('eval_list.txt', 'w') for i in range(len(train_json["annotations"])): if i%5==0: eval_f.write(train_json["annotations"][i]['filename']+' '+ str(train_json["annotations"][i]['label']) +'\n') else: train_f.write(train_json["annotations"][i]['filename']+' '+ str(train_json["annotations"][i]['label']) +'\n')登录后复制/home/aistudio6024登录后复制
四、模型训练
1.配置
以 PaddleClas/ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml 为基础进行配置,具体见下:
# global configsGlobal: checkpoints: null pretrained_model: null output_dir: ./output/ device: gpu save_interval: 1 eval_during_train: True eval_interval: 1 epochs: 20 print_batch_step: 10 use_visualdl: True # used for static mode and model export image_shape: [3, 224, 224] save_inference_dir: ./inference# model architectureArch: name: MobileNetV3_large_x1_0 class_num: 102 # loss function config for traing/eval processLoss: Train: - CELoss: weight: 1.0 Eval: - CELoss: weight: 1.0Optimizer: name: Momentum momentum: 0.9 lr: name: Cosine learning_rate: 0.00375 warmup_epoch: 5 last_epoch: -1 regularizer: name: 'L2' coeff: 0.000001# data loader for train and evalDataLoader: Train: dataset: name: ImageNetDataset image_root: /home/aistudio/ cls_label_path: /home/aistudio/train_list.txt transform_ops: - DecodeImage: to_rgb: True channel_first: False - RandCropImage: size: 224 - RandFlipImage: flip_code: 1 - NormalizeImage: scale: 1.0/255.0 mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' sampler: name: DistributedBatchSampler batch_size: 512 drop_last: False shuffle: True loader: num_workers: 4 use_shared_memory: True Eval: dataset: name: ImageNetDataset image_root: /home/aistudio/ cls_label_path: /home/aistudio/eval_list.txt transform_ops: - DecodeImage: to_rgb: True channel_first: False - ResizeImage: resize_short: 256 - CropImage: size: 224 - NormalizeImage: scale: 1.0/255.0 mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' sampler: name: DistributedBatchSampler batch_size: 128 drop_last: False shuffle: False loader: num_workers: 4 use_shared_memory: TrueInfer: infer_imgs: docs/images/whl/demo.webp batch_size: 10 transforms: - DecodeImage: to_rgb: True channel_first: False - ResizeImage: resize_short: 256 - CropImage: size: 224 - NormalizeImage: scale: 1.0/255.0 mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' - ToCHWImage: PostProcess: name: Topk topk: 5 class_id_map_file: ./dataset/flowers102/flowers102_label_list.txtMetric: Train: - TopkAcc: topk: [1, 5] Eval: - TopkAcc: topk: [1, 5]登录后复制
2.开始训练
In [ ]# 覆盖配置%cd ~!cp -f ~/MobileNetV3_large_x1_0.yaml PaddleClas/ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml登录后复制In [ ]
%cd ~/PaddleClas/# 进入 PaddleClas 根目录,执行此命令# Arch.pretrained=True使用预训练模型!python tools/train.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Arch.pretrained=True登录后复制
训练情况:
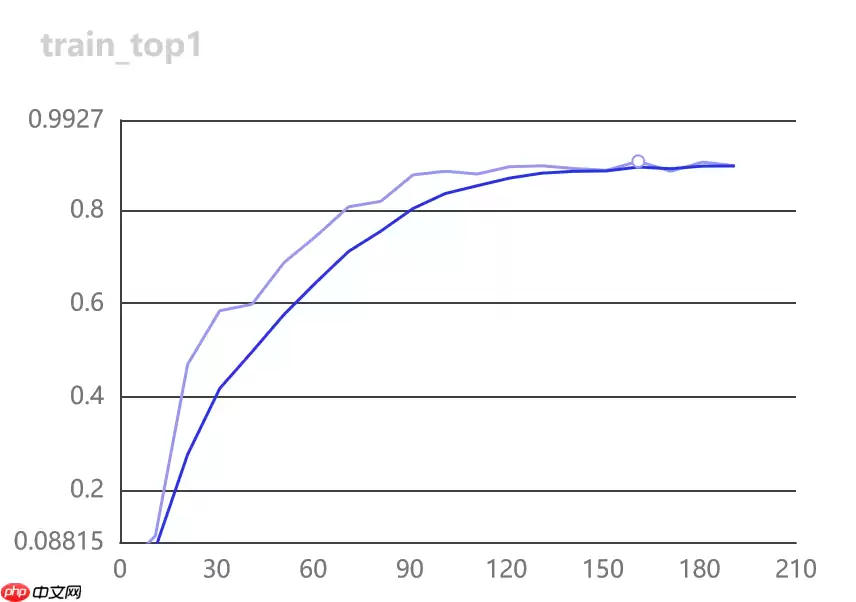
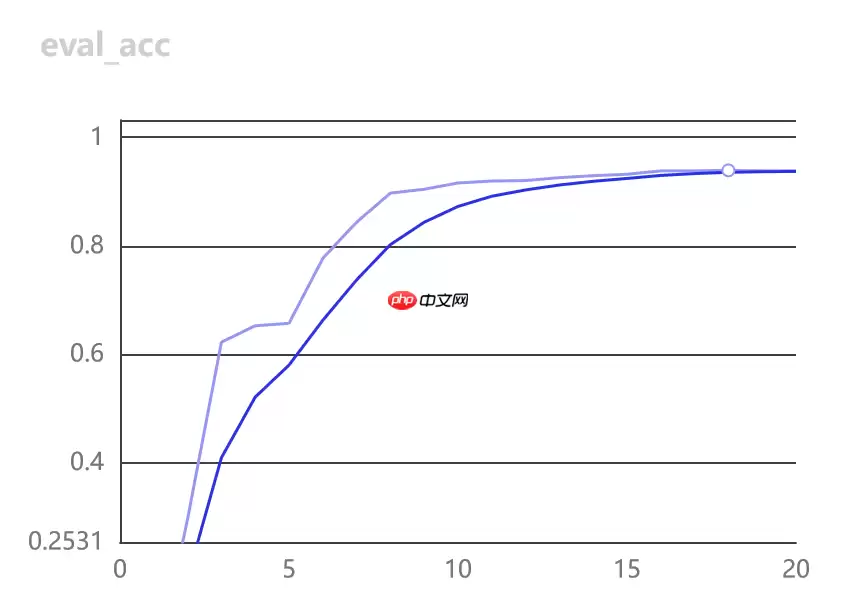
3.开始评估
In [44]%cd ~/PaddleClas/!python tools/eval.py \ -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml \ -o Global.pretrained_model=./output/MobileNetV3_large_x1_0/best_model登录后复制
[2024/01/10 23:08:17] root INFO: [Eval][Epoch 0][Iter: 0/9]CELoss: 0.36174, loss: 0.36174, top1: 0.90625, top5: 1.00000, batch_cost: 1.31483s, reader_cost: 1.22580, ips: 97.35107 images/sec[2024/01/10 23:08:17] root INFO: [Eval][Epoch 0][Avg]CELoss: 0.25337, loss: 0.25337, top1: 0.93923, top5: 0.99732登录后复制
五、预测
1.模型导出
In [49]# 模型导出%cd ~/PaddleClas/!python tools/export_model.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Global.pretrained_model=./output/MobileNetV3_large_x1_0/best_model登录后复制
2.开始预测
编辑 PaddleClas/deploy/python/predict_cls.py,按提交格式输出预测结果到文件。
import osimport sys__dir__ = os.path.dirname(os.path.abspath(__file__))sys.path.append(os.path.abspath(os.path.join(__dir__, '../')))import cv2import numpy as npfrom utils import loggerfrom utils import configfrom utils.predictor import Predictor# from utils.get_image_list import get_image_listfrom python.preprocess import create_operatorsfrom python.postprocess import build_postprocessclass ClsPredictor(Predictor): def __init__(self, config): super().__init__(config["Global"]) self.preprocess_ops = [] self.postprocess = None if "PreProcess" in config: if "transform_ops" in config["PreProcess"]: self.preprocess_ops = create_operators(config["PreProcess"][ "transform_ops"]) if "PostProcess" in config: self.postprocess = build_postprocess(config["PostProcess"]) # for whole_chain project to test each repo of paddle self.benchmark = config["Global"].get("benchmark", False) if self.benchmark: import auto_log import os pid = os.getpid() self.auto_logger = auto_log.AutoLogger( model_name=config["Global"].get("model_name", "cls"), model_precision='fp16' if config["Global"]["use_fp16"] else 'fp32', batch_size=config["Global"].get("batch_size", 1), data_shape=[3, 224, 224], save_path=config["Global"].get("save_log_path", "./auto_log.log"), inference_config=self.config, pids=pid, process_name=None, gpu_ids=None, time_keys=[ 'preprocess_time', 'inference_time', 'postprocess_time' ], warmup=2) def predict(self, images): input_names = self.paddle_predictor.get_input_names() input_tensor = self.paddle_predictor.get_input_handle(input_names[0]) output_names = self.paddle_predictor.get_output_names() output_tensor = self.paddle_predictor.get_output_handle(output_names[ 0]) if self.benchmark: self.auto_logger.times.start() if not isinstance(images, (list, )): images = [images] for idx in range(len(images)): for ops in self.preprocess_ops: images[idx] = ops(images[idx]) image = np.array(images) if self.benchmark: self.auto_logger.times.stamp() input_tensor.copy_from_cpu(image) self.paddle_predictor.run() batch_output = output_tensor.copy_to_cpu() if self.benchmark: self.auto_logger.times.stamp() if self.postprocess is not None: batch_output = self.postprocess(batch_output) if self.benchmark: self.auto_logger.times.end(stamp=True) return batch_outputdef get_image_list(img_file_path): imgs_lists = [] # if img_file is None or not os.path.exists(img_file): # raise Exception("not found any img file in {}".format(img_file)) img_end = ['jpg', 'png', 'jpeg', 'JPEG', 'JPG', 'bmp'] import os from os.path import join, getsize for root, dirs, files in os.walk(img_file_path): for file in files: img_file=os.path.join(root, file) imgs_lists.append(img_file) if len(imgs_lists) == 0: raise Exception("not found any img file in {}".format(img_file)) imgs_lists = sorted(imgs_lists) return imgs_listsdef main(config): cls_predictor = ClsPredictor(config) image_list = get_image_list(config["Global"]["infer_imgs"]) batch_imgs = [] batch_names = [] cnt = 0 # dic import json mydic=[] for idx, img_path in enumerate(image_list): img = cv2.imread(img_path) if img is None: logger.warning( "Image file failed to read and has been skipped. The path: {}". format(img_path)) else: img = img[:, :, ::-1] batch_imgs.append(img) img_name = os.path.basename(img_path) batch_names.append(img_name) cnt += 1 if cnt % config["Global"]["batch_size"] == 0 or (idx + 1 ) == len(image_list): if len(batch_imgs) == 0: continue batch_results = cls_predictor.predict(batch_imgs) for number, result_dict in enumerate(batch_results): filename = batch_names[number] clas_ids = result_dict["class_ids"] scores_str = "[{}]".format(", ".join("{:.2f}".format( r) for r in result_dict["scores"])) label_names = result_dict["label_names"] print("{}:\tclass id(s): {}, score(s): {}, label_name(s): {}". format(filename, clas_ids, scores_str, label_names)) temp_dic={} temp_dic["filename"]="test/"+img_path.strip('/home/aistudio') temp_dic["label"]=clas_ids[0] mydic.append(temp_dic) batch_imgs = [] batch_names = [] # 保存到文件 with open('/home/aistudio/result.json', 'w') as f: myjson={"annotations":mydic} json.dump(myjson,f) if cls_predictor.benchmark: cls_predictor.auto_logger.report() returnif __name__ == "__main__": args = config.parse_args() config = config.get_config(args.config, overrides=args.override, show=True) main(config)登录后复制In [ ]# 自定义predict_cls.py覆盖%cd ~!cp -f ~/predict_cls.py ~/PaddleClas/deploy/python/predict_cls.py登录后复制In [77]
# 开始预测%cd /home/aistudio/PaddleClas/deploy!python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.infer_imgs=/home/aistudio/test -o Global.inference_model_dir=../inference/ -o PostProcess.Topk.class_id_map_file=None登录后复制
预测日志
01220.webp:class id(s): [0, 3, 2, 4, 5], score(s): [1.00, 0.00, 0.00, 0.00, 0.00], label_name(s): []01229.webp:class id(s): [0, 2, 3, 4, 5], score(s): [0.97, 0.02, 0.00, 0.00, 0.00], label_name(s): []01232.webp:class id(s): [0, 3, 2, 8, 5], score(s): [0.98, 0.01, 0.00, 0.00, 0.00], label_name(s): []00004.webp:class id(s): [2, 3, 1, 0, 5], score(s): [0.79, 0.10, 0.03, 0.02, 0.01], label_name(s): []00013.webp:class id(s): [1, 5, 2, 3, 0], score(s): [0.80, 0.08, 0.05, 0.02, 0.01], label_name(s): []00052.webp:class id(s): [1, 5, 3, 4, 6], score(s): [0.91, 0.03, 0.02, 0.01, 0.01], label_name(s): []00061.webp:class id(s): [3, 0, 4, 2, 5], score(s): [0.60, 0.14, 0.09, 0.06, 0.03], label_name(s): []00092.webp:class id(s): [1, 2, 3, 5, 4], score(s): [0.65, 0.18, 0.08, 0.04, 0.01], label_name(s): []登录后复制
六、提交
1.提交结果
提交当前目录下的result.json,即刻得到成绩,如下图:
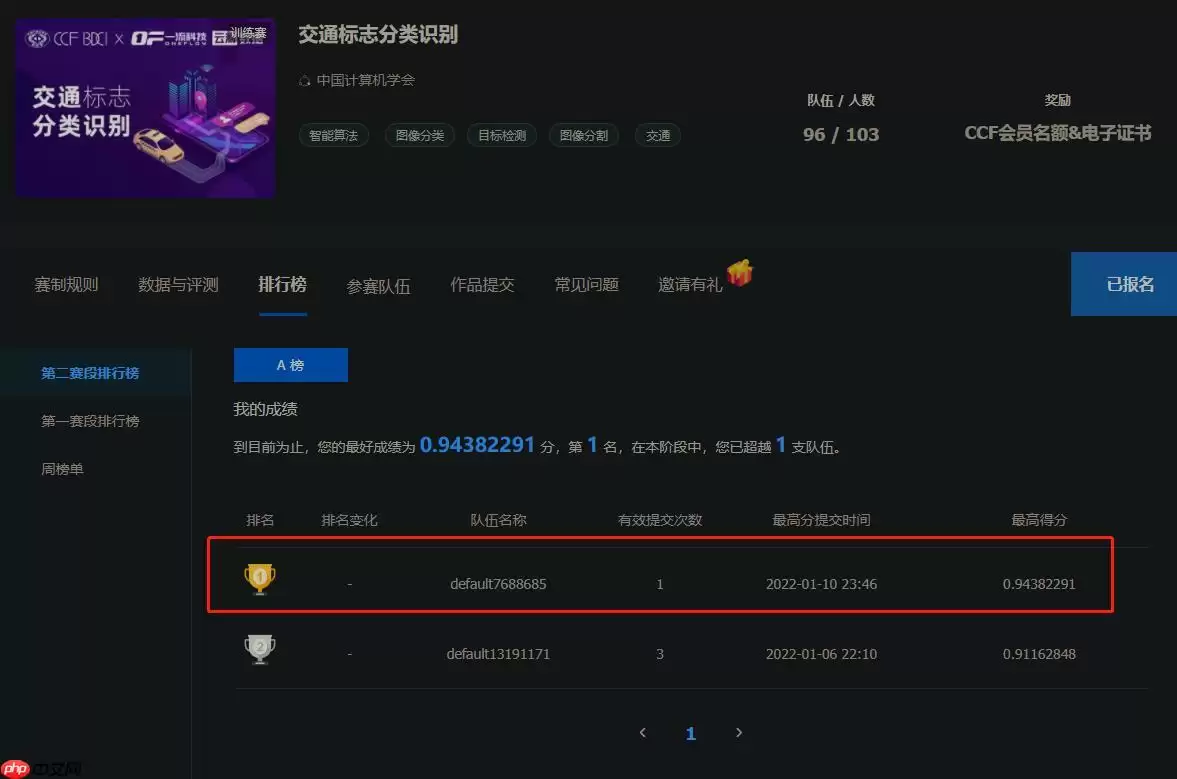
大家来试试吧!
2.其他注意事项
生成版本时提示存在无效软链接无法保存 ,可以在终端 PaddleClas 下运行下列代码清理即可。
for a in `find . -type l`do stat -L $a >/dev/null 2>/dev/null if [ $? -gt 0 ] then rm $a fidone登录后复制
相关攻略

零基础学习Python可从安装环境开始。前往官网下载最新稳定版,安装时勾选添加PATH选项。验证安装后,创建 py文件并写入print()函数输出文本。通过命令行运行文件,观察输出结果。理解代码按顺序执行,注意括号与引号的正确使用。初期不必死记语法,通过修改代码并运行来建立动手反馈的实践感。

Trae的AI功能深度适配FastAPI与Flask框架。针对FastAPI,它能精准识别异步架构与类型注解,提供模型定义、路由补全及异步数据库建议;在Flask中,则侧重理解装饰器链、请求上下文与ORM操作,辅助完成权限控制与数据库提交等典型模式。此外,Trae具备跨框架语义索引能力,可感知项目结构、依赖变更与工具函数调用,提升开发效率。

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构