2025 年 2 月 25 日,deepseek 在开源周的第二天,正式发布了首个专为混合专家模型(moe)训练和推理设计的专家并行(ep)通信库 —— deepep。deepep 在 github 上开源仅 20 分钟,便获得了超过 1k 个 star。截止本文发布时间,deepep 的 github star 数已经达到 2.4k,并且还在持续飙升。

采用 MoE(Mixture-of-Experts,混合专家)架构的大语言模型,能够在显著提升模型容量的同时避免计算量的线性增长。然而,这种架构也引入了新的挑战 —— 尤其是在 GPU 之间的通信方面。在 MoE 模型中,每个 Token 仅会激活一部分专家,因此如何在设备之间高效交换数据变得至关重要。传统的 all-to-all 通信方法往往会导致瓶颈,增加延迟并降低 GPU 资源的利用率。在对延迟敏感的场景(如实时推理)中,即使是微小的延迟也可能影响整体性能。此外,尽管低精度运算(如 FP8)有助于减少内存占用,但其实现需要精细优化以维持模型质量。这些问题凸显了针对专家并行(Expert Parallelism, EP)需求定制通信库的必要性。
DeepEP 是一个专为 MoE 模型和专家并行设计的通信库。DeepEP 解决了 Token 在 GPU 之间分发和聚合过程中的效率问题。该库提供了高吞吐量、低延迟的all-to-all 的 GPU 内核(通常称为 MoE 分发与聚合内核),在训练和推理过程中优化了数据交换流程。特别值得一提的是,DeepEP 支持低精度运算(包括 FP8),这与 DeepSeek-V3 论文中详细描述的技术完全一致。DeepEP 有效解决了节点内和节点间环境中扩展 MoE 架构的挑战。
DeepEP 的核心功能DeepEP 的核心功能包括:
高效的 all-to-all 通信:通过软硬件协同优化,DeepEP 实现了专家之间的高速数据传递,显著提升了训练和推理效率。支持 NVLink 和 RDMA:无论是节点内还是节点间通信,DeepEP 都能充分利用 NVLink 和 RDMA 的高带宽和低延迟特性。高吞吐量与低延迟内核:在训练和推理预填充阶段,DeepEP 提供了高吞吐率计算核;而在推理解码阶段,则提供了低延迟计算核,满足不同场景的需求。原生 FP8 支持:DeepEP 支持包括 FP8 在内的低精度运算,进一步优化了计算资源的利用。灵活的 GPU 资源控制:通过计算与通信的重叠处理,DeepEP 实现了资源的高效调度,提升了整体性能。DeepEP 的常规内核和低延迟内核DeepEP 提供了两种主要类型的内核,以满足不同的操作需求:
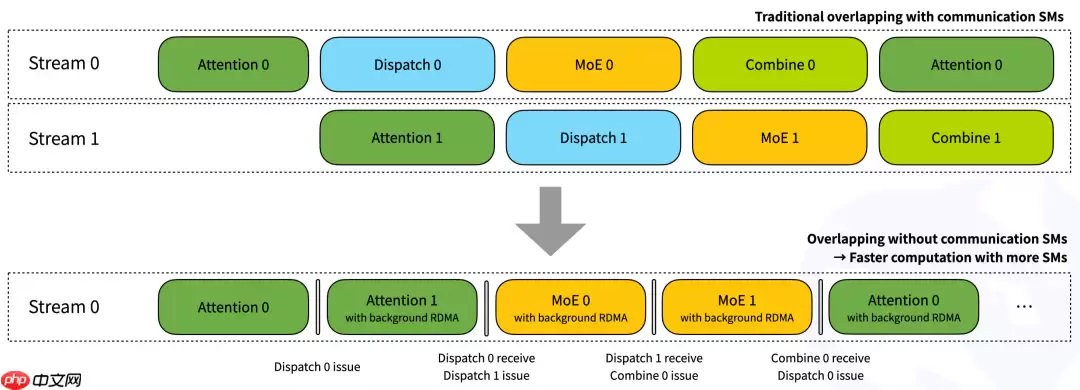
常规内核(Normal kernels):这些内核针对需要高吞吐量的场景进行了优化,例如在推理或训练的预填充阶段。它们利用 NVLink 和 RDMA 网络技术,在 GPU 之间高效地转发数据。测试显示,在 Hopper GPU 上,节点内通信的吞吐量约为 153 GB/s,而使用 CX7 InfiniBand(带宽约为 50 GB/s)的节点间通信性能稳定在 43–47 GB/s 之间。通过最大化可用带宽,这些内核减少了在 token 分发和结果合并过程中的通信开销。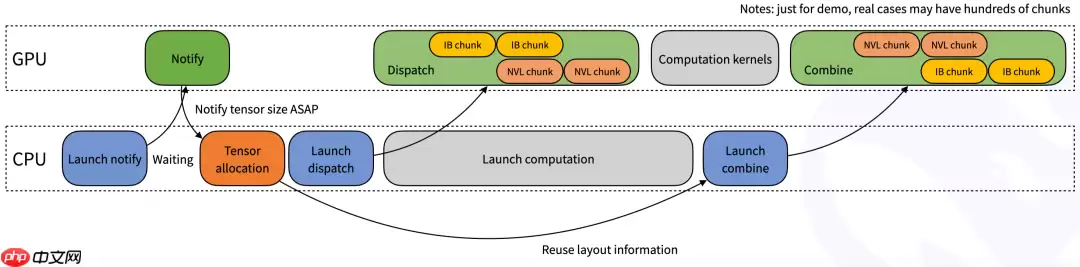
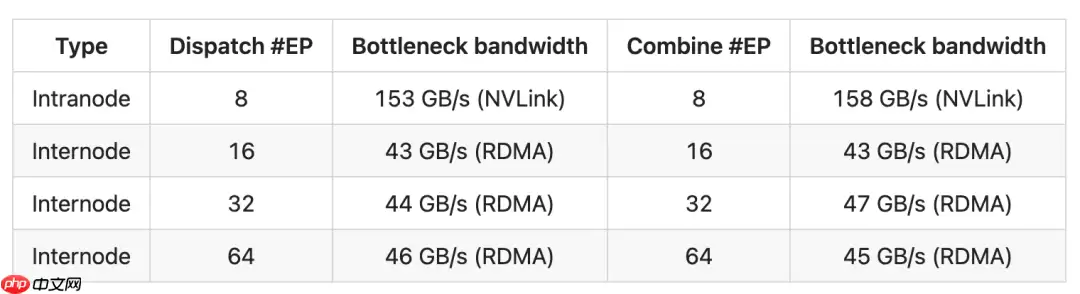
DeepSeek 在 H800 GPU 上测试了常规内核(NVLink 最大带宽约为 160 GB/s),每块 GPU 连接一张 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约为 50 GB/s)。此外,遵循 DeepSeek-V3/R1 的预训练设置,包括每批 4096 个 token、隐藏层维度 7168、Top-4 分组、Top-8 专家、FP8 分发以及 BF16 结果合并。性能测试的结果如下表所示:
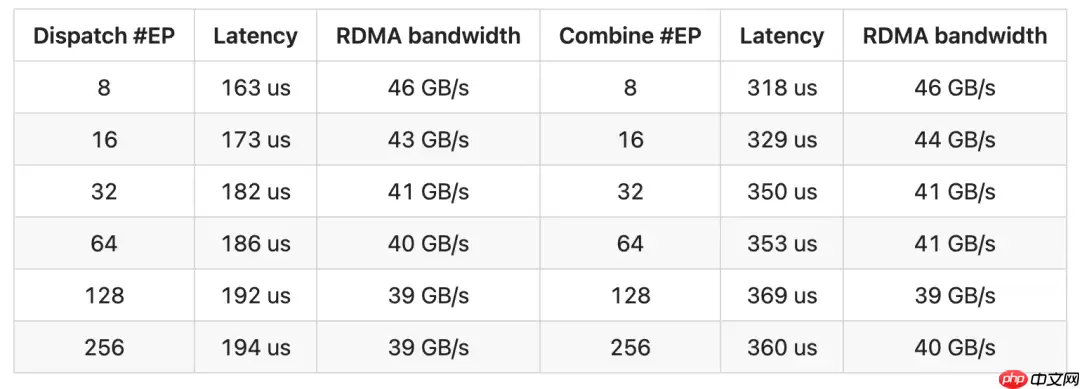
DeepSeek 在 H800 GPU 上测试了低延迟内核,每块 GPU 连接一张 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约为 50 GB/s)。此外,遵循典型的 DeepSeek-V3/R1 生产环境设置,包括每批 128 个 token、隐藏层维度 7168、Top-8 专家、FP8 分发以及 BF16 结果合并。性能测试的结果如下表所示:
DeepEP 的发布标志着 DeepSeek 在 MoE 训练和推理优化上的又一重要突破。该通信库针对专家并行设计,解决了 GPU 之间的数据交换瓶颈,极大地提高了通信效率。DeepSeek 下一个开源的项目会是什么呢?让我们拭目以待。
参考资料deepseek-ai/DeepEP:https://github.com/deepseek-ai/DeepEP