
编辑:lrs
【新智元导读】STP(自博弈定理证明器)让模型扮演「猜想者」和「证明者」,互相提供训练信号,在有限的数据下实现了无限自我改进,在Lean和Isabelle验证器上的表现显著优于现有方法,证明成功率翻倍,并在多个基准测试中达到最先进的性能。大型语言模型的「推理能力」现在成了NLP皇冠上的明珠,其核心难题在于「缺乏高质量训练数据」,标注数据需要领域专家,成本非常高昂且难以扩展;现有高等数学论文和定理的数量也非常有限,远少于其他任务的数据源。
DeepSeek-Prover和DeepSeek R1等模型的思路非常巧妙,在没有逐步解决方案的数据集(如定理命题)上进行强化学习,可以极大提升其推理能力;和专家迭代(expert iteration)类似,交替进行「LLMs生成证明」和「正确生成的证明上进行微调」,部分缓解了数据稀缺(data scarcity)的问题。
不过,强化学习和专家迭代都存在一个严重问题:通过率(pass rate)过低,对「未证明的定理」生成「正确证明」所需的样本量呈指数级增长,大量的计算资源被浪费在生成错误的证明上,无法为模型提供训练信号。
比如在LeanWorkbook上的通过率为13.2%,其中98.5%的计算资源都浪费在生成错误证明上了,也就是说,在经过几轮专家迭代后,由于缺乏新的成功证明,重新训练模型的效果会大大降低。
此外,强化学习从原理上就受到训练数据集中「定理难度水平」的限制,一个模型不可能从「解决高中水平的问题」中学习到「大学水平的证明技巧」,也无法解决「开放性」的数学问题,需要持续收集高水平的定理命题和数学问题。
斯坦福的研究人员提出了一个自博弈定理证明器(STP),模仿数学家学习和发展数学的方式,同时承担两个角色(猜想者和证明器),互相提供训练信号,可以在「有限数据」的情况下「无限运行并自我改进」。

论文链接:https://arxiv.org/pdf/2502.00212
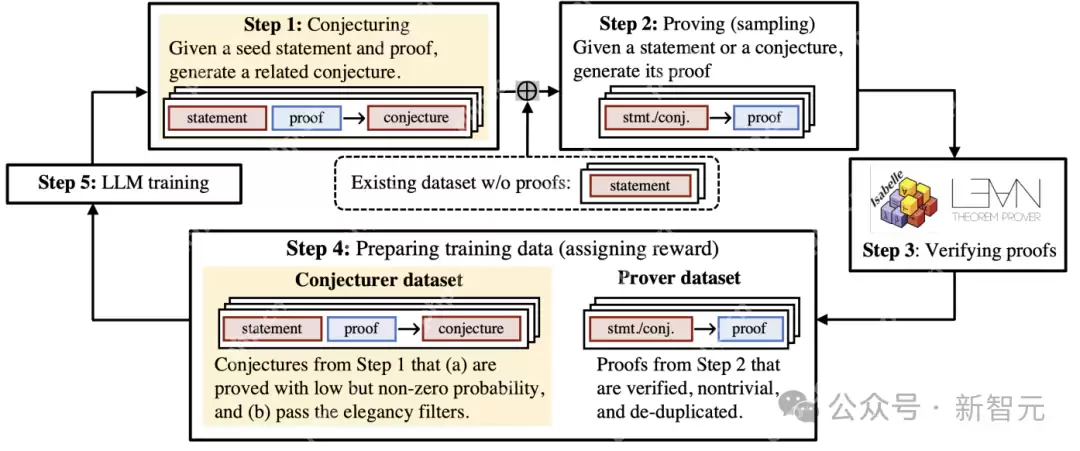
猜想者(conjecturer)在给定一个带有证明的种子定理后,提出一个新的相关猜想(步骤1),而证明器(prover)则尝试证明现有数据集中的猜想和命题(步骤2);然后,验证器(verifier)选择正确的证明(步骤3)来使用标准RL训练证明器,并识别出正确、可行、优雅但具有挑战性的猜想来指导猜想者的训练(步骤4)。
在每次迭代中,猜想者会在之前生成的猜想上进行训练,生成的猜想对于当前证明器来说只能「勉强证明」,即证明器相对于其随机种子的成功概率为一个较小的正值;迭代过程会逐渐增加猜想和证明的难度,而无需额外数据,可以看作是猜想者和证明器之间的自我博弈算法,或是自动化的课程学习。
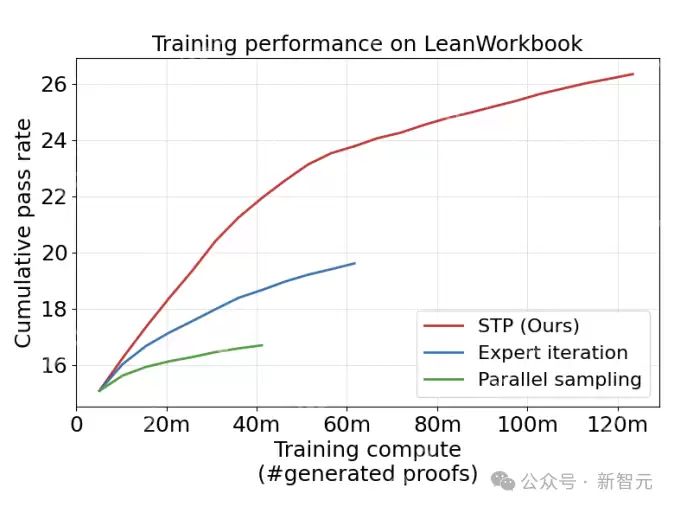
研究人员在Lean和Isabelle上对该方法进行了实证评估,使用DeepSeek-Prover-V1.5-SFT作为STP的基础模型,在大约1.2亿个生成的证明和200万个生成的猜想的自我博弈训练后,成功证明了训练数据集LeanWorkbook中26.3%的命题,是之前专家迭代性能(13.2%)的两倍!
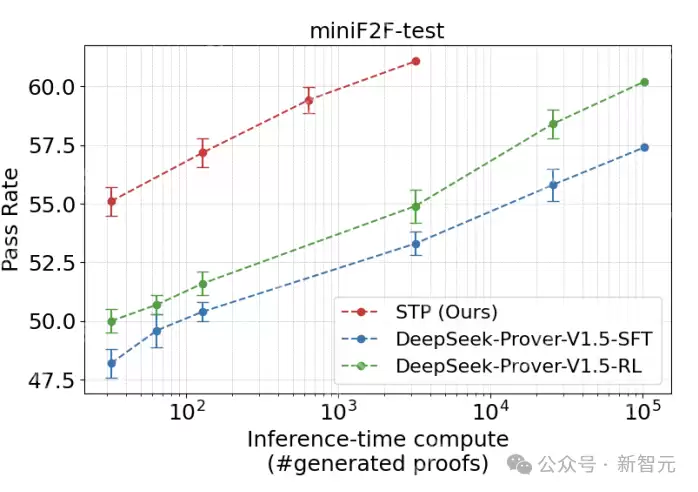
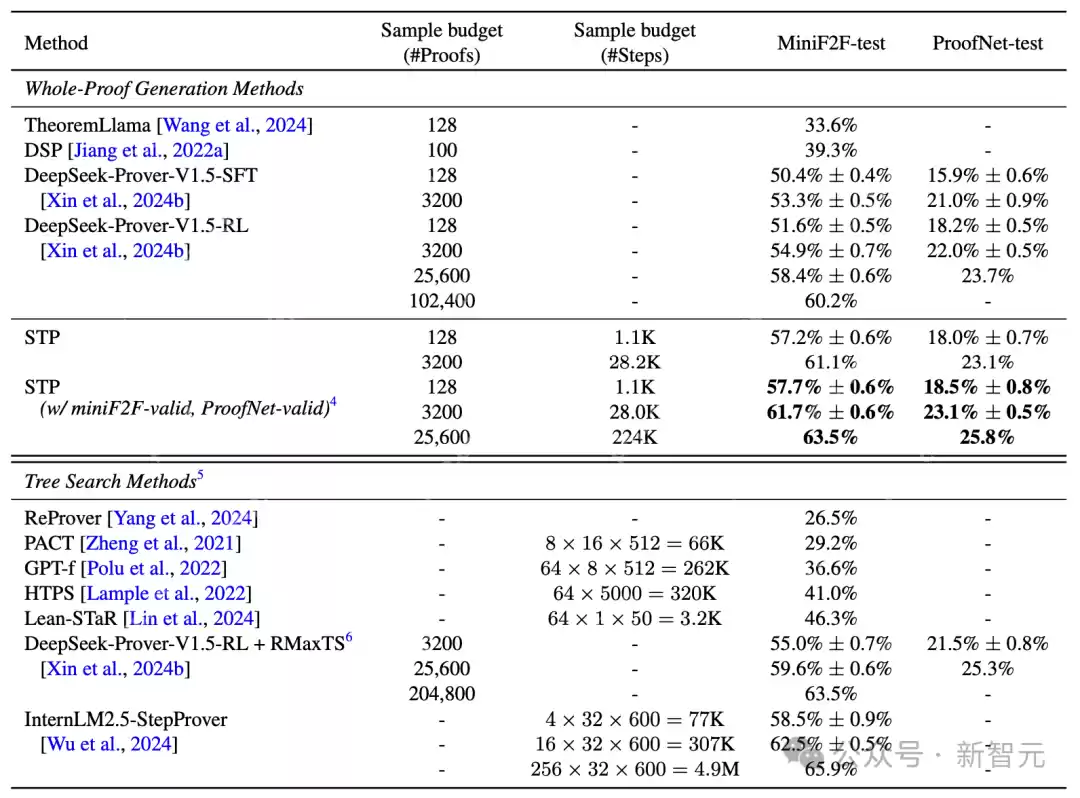
在推理速度上,研究人员在公共基准测试miniF2F-test上对现有模型和使用STP训练的最终模型进行多次独立采样,该模型在各种采样预算下均显著优于DeepSeek-Prover-V1.5模型,还在miniF2F-test(61.1%,pass@3200)、ProofNet-test(23.1%,pass@3200)和PutnamBench(8/644,pass@64)上实现了最先进的性能。
作者马腾宇是斯坦福大学的助理教授,本科毕业于清华姚班,于普林斯顿大学获得博士学位,研究兴趣包括机器学习和深度学习,深度强化学习和高维统计。曾获得NIPS'16最佳学生论文奖,COLT'18最佳论文奖、ACM博士论文奖荣誉奖和2021斯隆研究奖。

方法
通过有监督微调进行模型初始化研究人员通过在现有的证明库(例如Mathlib)上构建的监督微调(SFT)数据集,对一个通用的大型语言模型(如Llama)进行微调,初始化「猜想者」和「证明器」模型,其中证明库包含人类编写的已知数学定理的正式证明,每个文件都形式化了一个相对独立的结果,比如教科书的一章。

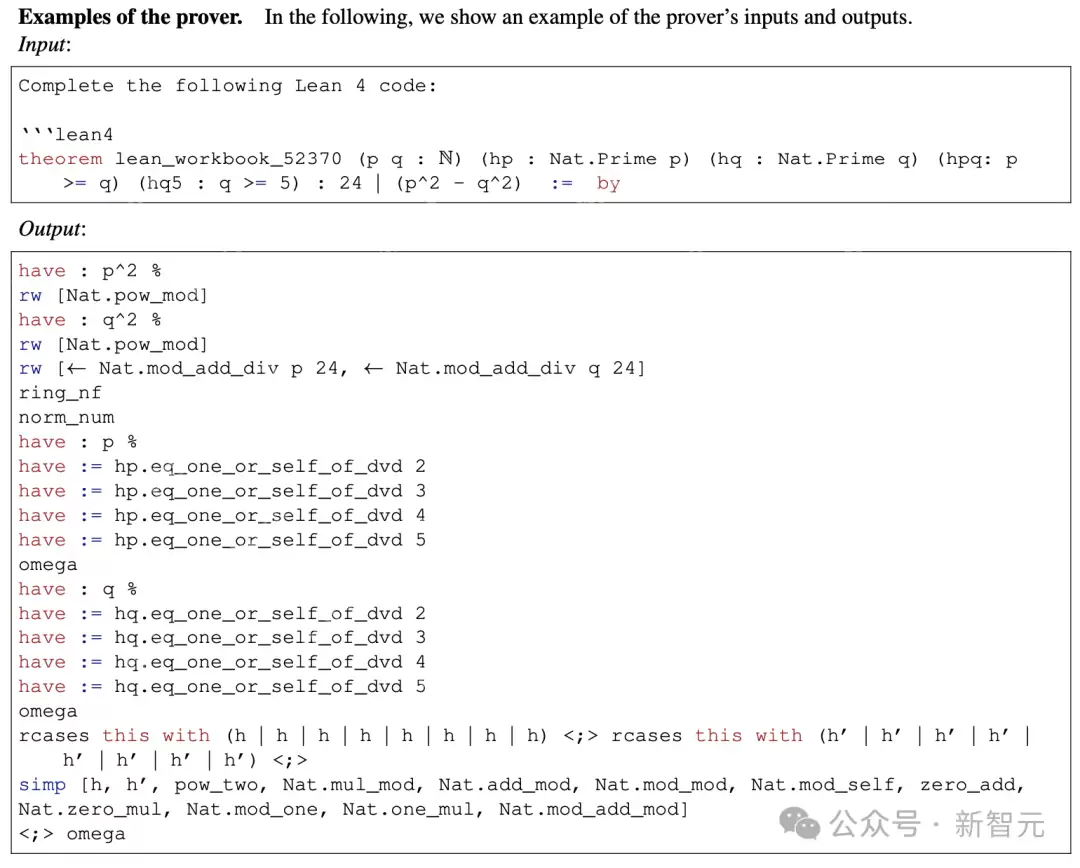
第1步和第2步:生成猜想和证明
研究人员使用验证器从证明中提取一个种子引理,去重后随机丢弃一些频繁出现的引理,输入到大模型中生成猜想;随机选择一组猜想,其数量不超过给定数据集中剩余未证明陈述的数量,以便证明器的计算资源在猜想和陈述之间平均分配;生成的猜想与现有数据集中未证明的陈述合并作为证明器的输入。
在第2步证明过程,为每个陈述/猜想独立采样K个证明。
第3步:用Lean等验证证明的正确性
第4步:奖励分配
STP的主要技术难点是为猜想者设计奖励函数,最终目标是激励猜想者生成多样化、相关、可行但又有一定挑战性的猜想,以便为证明器提供足够的训练信号。
研究人员首先将所有生成的猜想和证明整理成一个示例列表,使用证明器通过K个独立生成的证明估计的(经验)通过率来判断猜想的挑战性。
然后设计一个启发式的过滤器,防止模型生成具有复杂目标的、没有实际价值的难题,即移除最小证明长度除以猜想长度处于最低20%的猜想。
最后对选定的猜想进行重新加权,以保持猜想者的多样性,猜想者的奖励不能仅依赖于单独生成的猜想,否则猜想者的最优策略可能会退化为单一分布:将选定猜想的分布推向现有数据集中未证明的陈述,最小化与未证明定理的均匀分布的Wasserstein距离,以保持多个模式之间的平衡。
第5步:LLM训练
对于证明数据集,根据对应陈述/猜想的验证证明数量的倒数对样本进行加权,在猜想或证明上计算加权交叉熵损失,引入长度惩罚以鼓励生成更简单的证明。
最终再训练(re-training)为了避免自博弈过程中数据分布变化导致的训练不稳定,研究人员从基础模型(SFT阶段之前)开始,对最终模型进行再训练,再训练使用的数据集包括SFT数据集以及在自博弈训练过程中生成的所有正确证明。
证明对应命题或猜想的经验通过率不超过1/4;对于每一个陈述或猜想,随机保留最多16个不同的证明,以加快训练速度。
实验结果
研究人员使用专家迭代后的DeepSeek-Prover-V1.5-SFT作为基础模型,训练数据包括公共数据集(例如LeanWorkbook、miniF2F-valid、ProofNet-valid)以及其他专有数据集中的证明。运行了24次STP迭代后,总共生成了200万条猜想、1.2亿个证明和198亿个token,用累积通过率(即在整个训练过程中证明的陈述的比例)作为衡量训练进展的主要指标。
STP、专家迭代和平行采样方法在LeanWorkbook训练数据集上的累积通过率实验可以看到,STP的扩展性能明显优于专家迭代。
为了在常见基准测试中取得最佳性能,研究人员还使用LeanWorkbook、miniF2F-valid和ProofNet-valid中的陈述对模型进行了额外8次迭代的训练,与以往工作在miniF2F-test和ProofNet-test测试集相比,STP显著优于DeepSeek-Prover-V1.5-RL,在各种推理时间样本预算下均实现了最先进的性能。
消融实验
生成的猜想提供了更多训练信号
在Isabelle实验中,研究人员使用中间模型对LeanWorkbook中的未证明命题和生成猜想的经验通过率进行了直方图分析。在为79000条未证明陈述生成的250万条证明中,只有131条是正确的,所以仅在正确证明上对模型进行微调几乎没有任何效果,专家迭代的效果停滞。
相比之下,STP生成的猜想具有更高的通过率,提供了更多的训练信号,进而实现了更好的扩展性能。
使用生成的猜想再训练仍然有助于下游性能
在最终的再训练阶段,除了LeanWorkbook中成功证明的陈述之外,使用生成的猜想进行重新训练仍然有益,即使对于在miniF2F-test和ProofNet-test上的性能也是如此,pass@128指标上大约提高了1%的性能。
参考资料:
https://arxiv.org/pdf/2502.00212




