信我,有你想要的!最大化deepseek潜能 - 动态注意力机制(第5讲)
今天和大家聊聊deepseek的核心技术之一——动态注意力机制。
首先,我们需要了解什么是注意力机制?
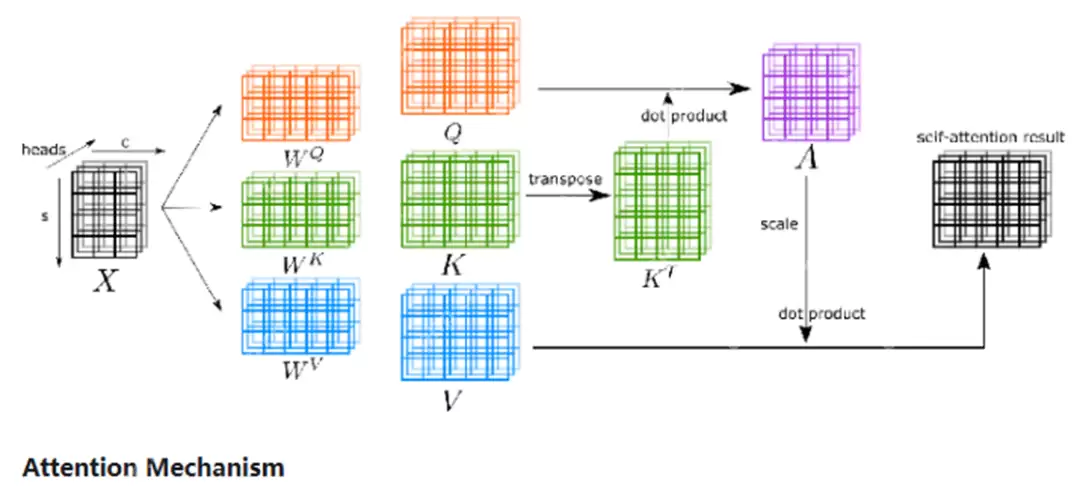
注意力机制(Attention Mechanism)是如今AI最核心的技术之一。它通过计算查询向量(Query)、键向量(Key)和值向量(Value),最终得到注意力分数,用以量化描述某一部分信息被关注的程度,从而让模型在处理信息时专注于最关键的部分,提高处理效率和回复质量。
举个例子,用户输入提示词:
哎哟妈呀,我跟你说,那啥,我今天早上出门,这天儿可够冷的,那风嗖嗖的,吹得我脸都僵了,我寻思着,咋这么冷呢,是不是把厚棉袄穿少了,你说这天儿咋就那么邪乎呢,反正我这心里寻思着,哪儿能去买个暖宝宝贴贴。
这个提示词中包含大量日常交流习惯中的铺垫与情感表达,属于无效信息。注意力机制会让模型将注意力专注在:今天早上很冷,我穿少了,哪儿能买暖宝宝?
注意力机制是什么来的?
注意力机制最符合人的真实思维。
再举个例子:

第一眼看到一张图片,你的注意力在哪儿,每个像素的权重是一样的吗?是不是一眼就会看到框中的耳环,根本不会注意到其他部位。
这!就是神奇的注意力机制。
那什么是动态注意力机制?
动态注意力机制(Dynamic Attention)要比注意力机制更进一步,它不仅能够学习到不同部分的相关性,还能在处理过程中自适应地调整注意力的分配,把资源聚焦于当下最重要的部分,使得模型更加智能(例如:文本、代码、图表在计算过程中权重会动态变化)。
技术人应该很容易理解这个所谓的“动态”:
负载均衡 -> 根据历史数据学习训练好参数,3台机器的流量分配权重配置好1:2:3。
动态负载均衡 -> 在系统运行过程中,根据3台机器处理能力,动态变化流量分配权重。
动态注意力机制对我们写提示词,获取更佳的回答质量有什么启示呢?
我们可以在提示词中:
显性地标注关键信息,例如:
角色技能限制步骤显性地设置约束条件,例如:
“优先考虑方案的分区容忍性与高可用”
“先不考虑内网延时对方案的影响”
采用分层分步描述,让deepseek清楚每一步的注意力重点,例如:
“第一步… 第二步… 第三步…”
“先设计框架,再填充细节”
“给出3组方案量化分析与优缺点后,经过我确认选择哪一组方案再继续”
优化了提示词,deepseek动态注意力机制能更有效发挥:
有限深度思考时间,专注主要矛盾,增加分析维度,回复质量极大提升;
相同质量的回复,动态分配权重,极大降低计算消耗。
总结:
动态注意力机制是deepseek的核心技术之一;
注意力机制最符合人的真实思维;
所谓“动态”,是指在运行过程中的注意力变化;
通过显性标注关键信息,显性设置约束条件,显性分层分步描述,能够最大化发挥deepseek动态注意力机制的潜力。
一切的一切,提示词只有适配了AI的认知模式,才能最高效地发挥最大的作用。
知其然,知其所以然。
思路比结论更重要。
补充阅读材料:
《Attention Is All You Need》
https://www.php.cn/link/75b8241ed29d71d3011ae167116e722c
PDF,可下载。
《动态注意力机制》
https://www.php.cn/link/31910e7811999746bcaec5c692b7f04d

含源码,Python。
相关攻略

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。

在企业级数据采集与自动化运维实践中,IT团队普遍面临一个核心挑战:Python爬虫为何频繁报错,修补维护何时才能终结?随着前端技术演进与动态反爬机制的日益复杂,依赖DOM解析的传统爬虫脚本往往陷入“部署即过时,运行即异常”的困境。本文将深入解析传统爬虫代码脆弱性的根本原因,并系统介绍一种能够重塑数据

很多刚接触Docker的开发者常有一个误解:制作镜像不就是把源代码打包进去就行了吗?实际上,在企业级的标准化开发流程中,直接将源码打包进Docker镜像是非常不专业的做法。这会导致镜像体积臃肿、引入潜在安全风险,并且模糊了“构建环境”与“运行环境”的边界。本文将深入解析Java、Vue、Go、Pyt
热门专题







热门推荐

洞察市场先机:SOL合约持仓量深度解析与实战应用 在瞬息万变的加密货币衍生品市场,SOL合约持仓量如同一张实时绘制的“资金热力图”。它不仅揭示了多空双方投入的真实资本规模,更映射出市场情绪的微妙变化与潜在的趋势转折点。对于精明的交易者而言,掌握解读这张“地图”的能力,意味着能在市场博弈中抢占信息高地

《像素秘境·唤灵师》可通过九游APP或官网下载。在九游APP搜索游戏名即可预约并获取最新版,官网专区也提供高速与普通下载选项。两种方式均能便捷安装,专区还附有游戏攻略供参考。

车市价格战正处微妙临界点。二季度起,一股与以往降价潮不同的涨价暗流开始酝酿。截至五月中旬,至少15家主流新能源品牌已释放调价信号,或直接涨价,或收紧优惠,涉及比亚迪、特斯拉、蔚来等传统及新势力车企。

说起《上古卷轴5:重制版》的主线旅程,奥杜因克星任务绝对是一座绕不开的高峰。它不仅是叙事的关键转折点,更是一场对玩家策略、操作与耐心的综合试炼。想要征服这条恶龙,光有勇气可不够,一份清晰的行动路线图至关重要。接下来,我们就一起梳理一下这场终极对决的核心脉络与实用技巧。 一、剑指目标:前往奥杜因克星的

SOL合约限价单的最小价格单位是0 001美元。该单位是交易时报价的最小变动值,直接影响订单的精确性与灵活性。了解此规则对合约交易者有效设置订单和管理策略至关重要。