编辑 | 王凤枝
凡是体验过Claude Code、Codex或其他AI编程助手的开发者,大多会产生类似的感受:明明刚给过它一次提醒,但下一次面对类似的场景,它还是会犯相同的错误。
你对它说“代码写完记得运行测试”,它这次听话照做了;可换一个任务,它就把这句叮嘱忘得干干净净。你补充一句“不要直接修改配置文件”,它当场记住了;但几天后碰到类似情况,又得重新强调一遍。
面对这种困境,最直观的应对思路是换一个更强的模型。然而微软研究院等团队开源的SkillOpt给出了另一种解决方案:先别急着升级模型,说不定该优化的是AI助手每次执行任务前参考的那份工作手册。

编程助手只是最容易感知这一问题的主要场景。SkillOpt的实验范围远不止代码任务,还涵盖了问答、表格处理、文档分析、多模态理解、数学推理以及具身智能体。它真正探讨的核心命题是:模型每次执行任务前读取的操作流程说明,是否可以被系统化地测试、更新和回滚。
训练流程,而非模型权重
SkillOpt项目页将其核心理念概括得非常直白:训练流程,不训练权重。
这里所说的skill(技能/工作手册),本质上是一份写给AI助手的标准操作流程:当它遇到某类任务时,应该先看什么、如何查证、使用哪些工具、输出格式有何要求、哪些常见陷阱必须避开。
实际上,许多团队已经在采用类似做法。项目仓库中通常包含AGENTS.md、CLAUDE.md、SKILL.md这类文件,用来告知模型这个仓库的工作方式、哪些命令需要运行、哪些文件不能随意修改、以及何时必须停下来询问人类。
问题在于,这些说明文件通常依靠人工来维护:发生一次事故,就补上一条规则;复盘发现遗漏,再修改几句;等到下次类似任务出错时,才意识到那条说明可能已经过时了。它们虽然能被模型读取,却很少被认真优化过。
SkillOpt的创新之处在于,它将这份用自然语言编写的工作手册当作一个可以被训练的对象。
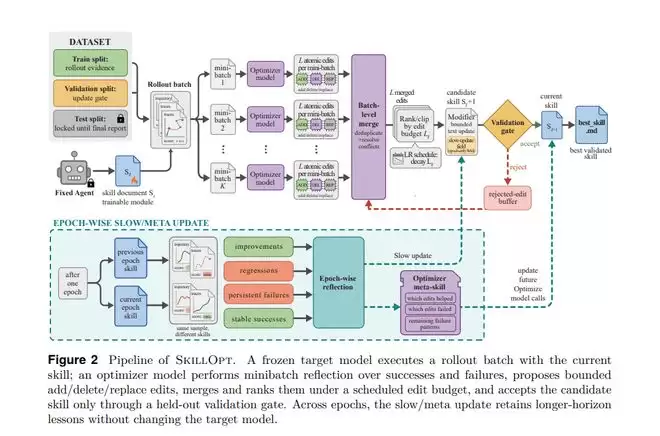
具体做法是:固定目标模型和执行环境,让系统带着当前的skill去执行一批任务,记录执行轨迹并计算得分;然后由另一个优化模型分析成功与失败的记录,提出对skill文件的增删改建议;最后把候选的skill放到保留验证集上测试,只有当分数确实提升时,才正式采纳这次修改。
这套流程听起来很像机器学习中的训练过程,但最终被修改的并非模型权重,而是一份Markdown格式的文档。
经验写下来,不等于真正学会
现有许多智能体系统已经能够从失败的执行轨迹中总结教训,并将经验存入记忆库、反思记录或新的提示词中。然而,经验被写进去,并不代表下次一定会被正确运用。
因此,SkillOpt为skill修改额外增加了几道严格约束。
第一,修改有预算限制。论文中把每轮允许修改的skill条数设为一个“文本学习率”,防止优化模型一开始就把整份文件重写。
第二,候选修改必须通过验证关卡。即使训练任务上的表现变好了,也不算数;只有保留验证集上的得分真正提升,这条修改才会被纳入当前版本。
第三,被拒绝的修改不会完全丢弃。它们会被存进“被拒编辑缓冲区”,作为后续优化时的反面教材:哪些改法看似合理,实际上却会损害性能。
第四,短期调整与长期模式分开处理。系统不会让每一步都被局部结果牵着走,而是允许它在一个更长的周期中吸收稳定的经验。
SkillOpt的反直觉之处就在这里:AI助手变强,不一定只依赖模型权重的更新,也可能通过一份更善于学习的工作手册来实现。
实验结果:小手册也能带来显著差距
论文中的实验结果需要放在原始评估框架中理解。
SkillOpt在6个基准测试、7个目标模型以及3种执行方式下,总共进行了52个评估组合。其中Codex和Claude Code这两类执行框架仅覆盖5个适配任务,ALFWorld并未纳入这两类框架。
按照论文正文的总体汇总口径,在GPT-5.5上,与不使用skill的基线相比,SkillOpt在直接对话模式下平均准确率提升了23.5个百分点;在Codex agentic loop中提升了24.8个百分点;在Claude Code中提升了19.1个百分点。
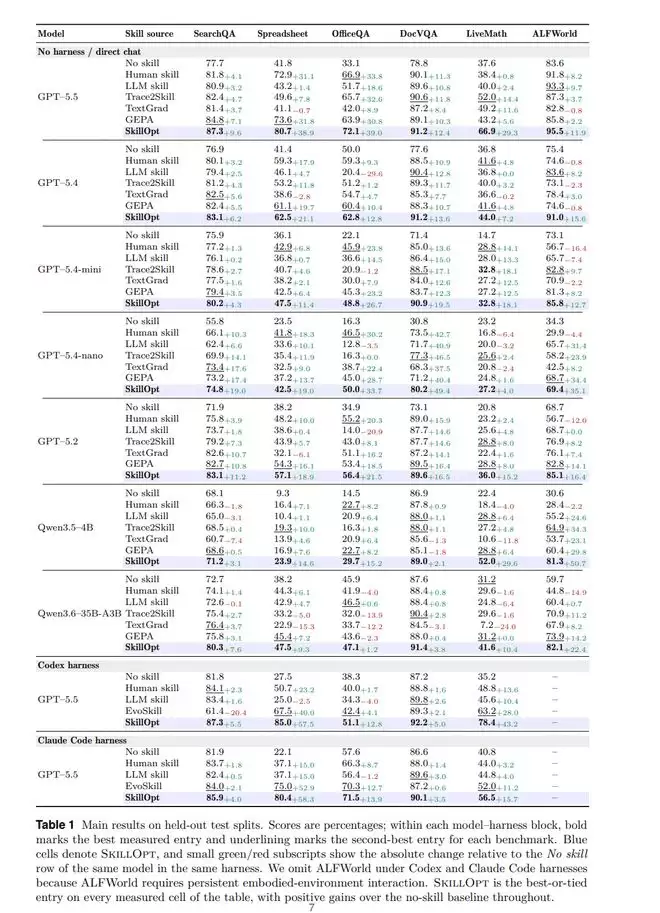
这些提升来源于论文设定下的特定任务、模型和执行环境,不能直接断言“所有AI助手都能提升二十多个百分点”。更严谨的说法是:在这套测试体系下,一份经过验证的工作手册已经能够显著影响智能体的表现。
最终保留的技能文件体积并不大。论文显示,6个基准测试中的best_skill.md长度在379到1995个token之间,中位数约为920个token。实际被接受的修改也很少,每个基准只有1到4次提交最终进入了skill文件,中位数是2.5次。
这与许多人想象中的“自进化agent”截然不同。它没有不断堆积大量的记忆,也没有把所有复盘内容都塞进提示词。大多数候选修改被挡在了验证门外,最后留下的只有少量、可读、可审计的流程规则。
它学到的是工作纪律
论文展示了一些学出来的规则。这些规则并非针对某道具体题目的答案,而是程序化的工作纪律。
换句话说,它学到的是“下次遇到类似问题时,应该先这样做”,而不是“这道题的答案是C”。
论文中给出了更具体的实例。在SpreadsheetBench任务中,优化后的skill会要求模型先检查工作簿的结构和公式,然后将计算后的静态值写入完整的目标区域,而不是单纯依赖Excel重新计算。在DocVQA任务中,它要求回答必须绑定到具体的视觉区域。在ALFWorld任务中,它会记录已经搜索过的位置,优先检查尚未访问的容器和表面,避免在同一批地点反复打转。

这些规则的语气非常接近人类写给同事的操作说明:直接、具体、带有条件约束。它们不会空喊“提高准确率”,而是直接告诉模型“先检查结构”“不要只看预览”“不要重复搜索已耗尽的位置”。SkillOpt与普通长提示词的本质区别也在这里:候选规则必须经过任务轨迹和验证门的筛选,最后留下的是少量能够稳定改善结果的动作规则。
论文还展示了两次运行细节。在ALFWorld中,初始skill只是一个通用的“搜索目标、拿起、转换、放到目的地”策略;优化后增加了对象名称匹配、已访问位置记忆、进度锁以及避免重复验证的规则,测试表现从49.3提升到了74.6。在SpreadsheetBench中,初始skill已经能够用Python处理表格,优化后进一步学会了检查真实的workbook、定位多sheet的表头和目标区域、规范化key与单元格类型,并在保存后重新打开workbook检查边界行和空白结果,测试表现从40.4提升到了78.9。
Prasenjit Sarkar在X上评论SkillOpt时写过一句话:模型没问题,有问题的是指令。

这句话解释了SkillOpt为何能引起AI编程工具用户的共鸣。当一个agent反复失败时,团队很容易认为模型不够强。但在许多工程场景中,失败可能源于流程没有写清楚、工具使用顺序不稳定、验证步骤未被强制执行、输出格式缺乏约束。
换一个更大的模型当然可能有效,但如果流程文件本身无法被训练、验证和回滚,同样的问题还会反复出现。
它和手写规则文件的区别在哪
SkillOpt很容易让人联想到当今各种AI编程工具中的规则文件。Cursor有rules,Claude Code会读取CLAUDE.md,Codex和许多agent harness也会读取项目说明。它们解决的是同一个问题:在模型进入一个项目之前,需要先了解这里的工作方式。
手写规则文件的典型问题是越写越长、规则之间相互矛盾、没人清楚哪条规则真正有效。一条规则可能是一次事故后的临时补丁,也可能只是某个人的偏好。它被写进文件后,不一定有人定期验证;失效了也不一定会被删除。
SkillOpt的不同之处在于,它将“规则是否有效”的判断权交还给任务表现。优化模型可以提议新增、删除或替换规则,但候选skill必须在保留验证集上表现更好才能被保留。被拒绝的编辑还会进入“被拒编辑缓冲区”,提醒后续优化不要再走同样的坏路。
这相当于给AGENTS.md、CLAUDE.md、SKILL.md这类文件增加了一层训练和验收机制:规则写进去之后,还需要被任务证明其价值;在规则文件越积越厚之前,也应当能够删除、回滚,并解释为什么保留。
“人工采纳”为何是必要的门槛
SkillOpt的论文发布于5月22日。GitHub README显示,项目在6月2日开放了PyPI v0.1.0,6月15日预览了SkillOpt-Sleep。Trendshift页面显示,截至6月30日,microsoft/SkillOpt已经收获了约1万个星标。
SkillOpt-Sleep面向ClaudeCode、Codex、Copilot这类本地编码智能体,其目标是在夜间复盘历史会话、离线重放高频任务,将那些通过验证门的经验整理成候选技能,并暂存供用户审阅和采纳。
这让SkillOpt从论文中的基准测试,逐步贴近普通AI编程工具用户的日常:白天让agent修改代码、运行测试、处理重复任务;晚上系统将这一天的会话拿去离线复盘,找出反复出现的失败模式;第二天再给出一组可以审阅、接受或拒绝的候选skill,而不是直接将新规则自动写入项目。
如果这条路线成立,AI编程助手的“学习”就不会仅限于下一代模型发布时。它也可能发生在团队自己的项目里:哪些命令总是需要运行,哪些目录不能触碰,哪些检查经常遗漏,哪些输出格式频繁出错——这些都可以从真实任务中转化为可验证的工作规则。
它仍需要能够打分的任务
SkillOpt还不是一个万能的“学习机”。
论文本身也列出了限制条件。它依赖于可评分的执行轨迹和保留验证集,因此最适合那些拥有自动评测、精确匹配、可执行检查或可靠反馈信号的任务。
如果任务是开放式写作、复杂判断、审美偏好或多目标编辑,那么验证门就没那么简单了。你很难仅仅通过一个分数来判断“当前的skill是否真的更好”。这时可能还需要人工评估,或更强的模型评审。
还有一个现实成本:训练这份skill本身需要运行额外的执行轨迹,同时也要调用优化模型。它的部署成本很低,但训练成本并非为零。只有当同一类任务会被反复执行时,这笔前期优化成本才更容易被摊薄。

此外,SkillOpt优化的是单一可移植的skill,而非庞大的技能库。对于高度异质的工作流而言,一份通用的技能可能不够用;不同的任务需要不同的skill,而这些skill之间还需要版本管理、归属、回滚和审计。
团队协作会让这个问题变得更加复杂。每个工程师都训练出自己的skill之后,项目需要区分哪些规则可以合并到团队文件,哪些只能留在个人偏好中;当规则相互冲突时,还需要有人决定优先级;当某条新规则提高了表格任务的表现,却损害了代码重构任务时,也需要重新划分它的归属。SkillOpt的论文尚未解决这些团队治理问题,但这类系统一旦进入真实项目,就绕不开它们。
因此,SkillOpt更像一个提醒:AI的经验要稳定上线,不能只靠“记住了”,还需要有触发、执行、验证和回滚机制。
AI的记忆,不能只靠写下来
Codex、Claude Code这类工具已经能够根据说明来调整行为。下一步要追问的,不只是“再给它多写几条规则”,而是这些规则能否被测试、被复用、被淘汰。
微软这篇论文没有修改模型权重,也没有承诺让agent在所有任务中自动变强。但它提醒了一件非常重要的事:AI助手的能力,不仅藏在模型里,也藏在那份看似普通的工作手册中。
如果这份手册能够被训练,那么AI agent的进步就不只依靠下一代大模型的发布,也可以来源于每一次任务之后的可验证复盘。




