先说几个核心判断吧。2024年底,OWASP放出了2025版Top 10 LLM安全风险清单。这件事的意义,不只是更新了一张风险清单那么简单——它标志着AI安全的底层逻辑,正在从“防漏洞”转向“管生命周期”,是一次真正的质变。
所谓LLM安全风险,其实是在说大语言模型在设计、训练、部署和交互这几大环节里,可能被攻击者盯上,或者因为系统设计本身有缺陷而引发的威胁。
OWASP,全称是Open Web Application Security Project,一个由社区驱动的非营利性基金会,专门琢磨怎么让软件和应用程序更安全。
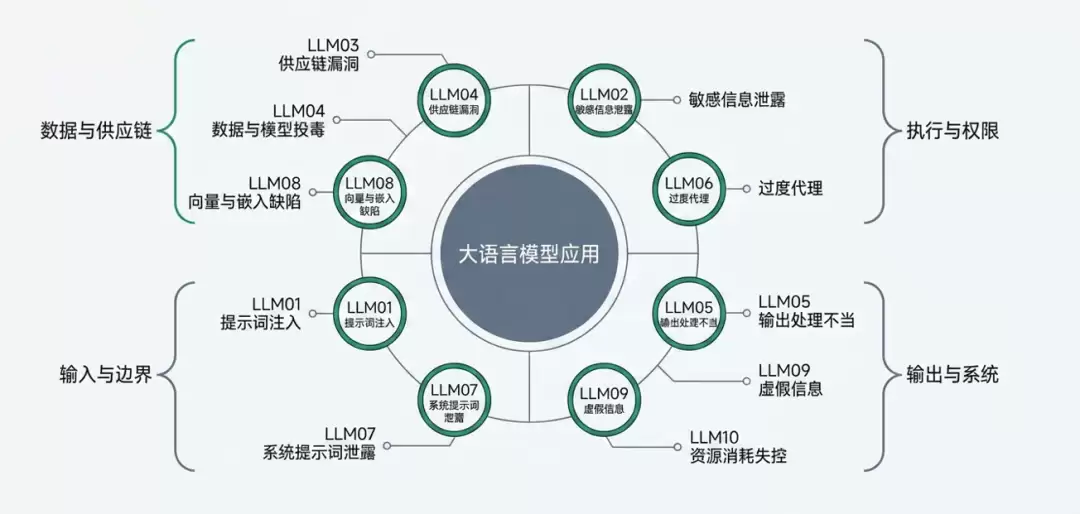
为什么会出现提示词注入和系统提示词泄露?根源在于LLM解析输入的方式——它没法干净地把控制指令和数据分离开来。模型把所有的输入都当成平等的文本流,自然就埋下了隐患。这是2025版清单里LLM01和LLM07对应的问题。
再看看供应链这一块。预训练模型、数据集、LoRA适配器、RAG知识库……这些东西全都依赖外部供应。你没法保证链条上的每个环节都绝对可信。于是,供应链漏洞、数据与模型投毒、向量与嵌入缺陷接踵而来,分别对应LLM03、LLM04和LLM08。
另外,LLM本质上不是程序,它是个概率模型,容易受环境影响,输出结果天然带着不确定性。如果物理逻辑校验不到位,敏感信息泄露、虚假信息泛滥、资源消耗失控这些问题,几乎是必然的。这就是LLM02、LLM09、LLM10(注:原文LLM09和LLM10似有重叠,此处按新版本理解)背后的逻辑。
还有一点,当开发者给了LLM过高的权限,比如能直接调系统函数或外部API,而且生成的输出不经校验就往下游系统跑——结果可想而知。输出处理不当和过度袋里,就这么来了。LLM05和LLM06,讲的正是这个。
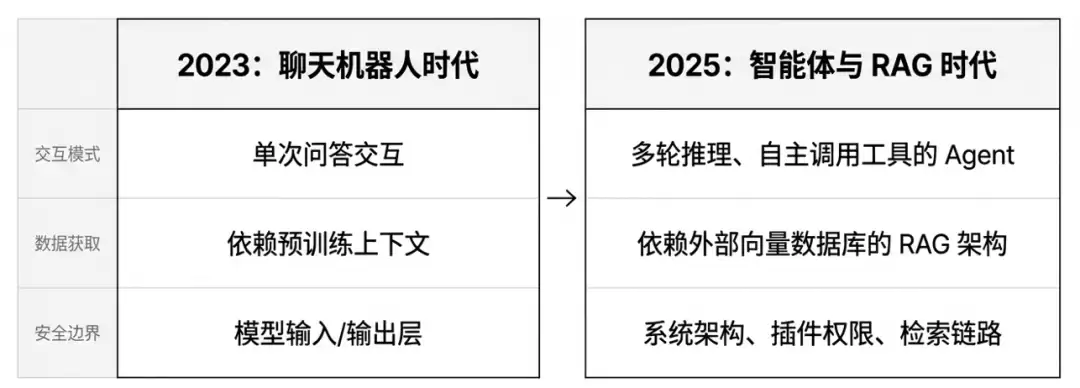
2023 vs 2025:安全重点的迁移
拿着2023和2025两份清单一对比,差别非常明显。安全的重心,已经从单纯的内容过滤,转向了对权限、资源、知识检索和动作执行的严苛约束。这个变化,很能说明行业认知的进化。
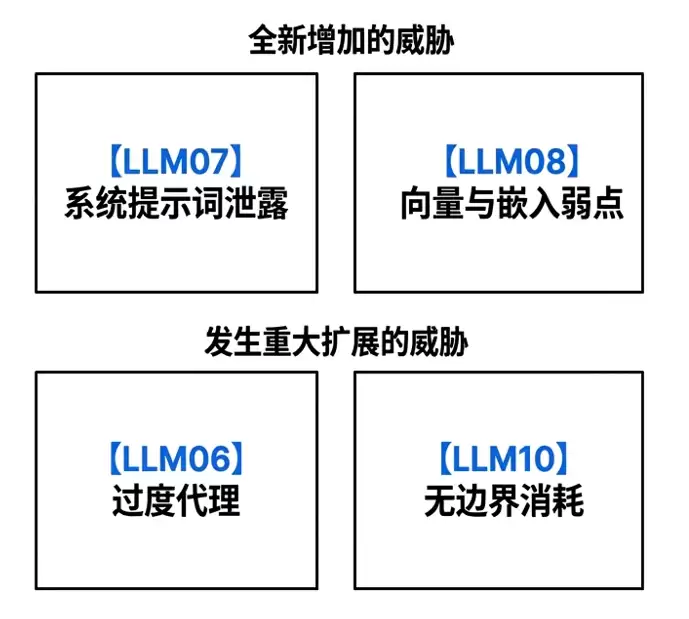
具体来看几个典型的趋势。
提示词的黑盒神话被打破
过去,开发者们普遍觉得系统提示词是放在黑盒里的,绝对安全。但现实的越狱攻击反复证明了一个道理:只要由LLM来处理的系统提示词,就有被逆向工程的可能,甚至通过一场精心设计的对话,就能把内容完整套出来。原以为的堡垒,其实一捅就破。
RAG的普及,让污染风险翻倍
现在RAG已经成了企业AI应用的标准配置。好处是能结合私有知识库回答问题,坏处是——向量数据库一旦被污染,模型输出的错误内容就会堂而皇之地传播出去。数据源的安全,成了新的命门。
Agentic架构,权限失控的放大器
随着Agentic架构越来越普及,LLM不再只是“聊天”,它开始“干活”了。能干活的AI,权限自然要大。但如果没有严格的约束,那些未受控的插件权限,就成了最致命的越权载体。能力越大,风险越大,这句话放到AI身上一点不假。
资源消耗,一个容易被忽略的攻击面
企业级LLM部署通常是按量计费的。攻击者完全可以通过少量、高复杂度的请求,就能轻易耗尽目标企业的资金池或者GPU配额。这已经不是技术攻击,而是经济攻击了。
核心防御理念:零信任,不假设模型本身是安全的
OWASP这一版清单里贯穿始终的,就是零信任理念。说白了,就是别指望模型自己管好自己。
具体来说:不相信模型的自我约束能力,不相信模型输出的安全性,也不相信模型能完美执行系统指令。听起来有点绝对,但这就是现实。
所以,防御的终极目标,是实现安全控制与模型能力的解耦。换句话说,安全逻辑必须建立在模型之外,由确定的代码和规则来执行。不管模型变得多聪明、能力多强,安全防线都不能依赖它的“听话”程度。要依赖的,是一套可审计、可预测的、自动化的多层防御体系。

防御的本质:不是让AI变好,而是让它即使犯错也伤害不了核心系统
最后想说的是,防御的本质并不在于绞尽脑汁让AI变“好”。就算你费尽心思,也无法保证它永远不出错。真正有效的做法,是通过架构设计,让AI即使犯错,也无法对核心系统和数据造成实质性伤害。
所以,真正的安全架构不是单点防御。它不是靠一个防火墙、一次扫描就能解决问题的。只有跨越数据层、模型层、输出层和运营层的立体网络,才能有效抵御LLM带来的系统性风险。这才是真正值得认真对待的地方。




