文章前言
随着大语言模型在企业中的落地越来越深入,从智能客服、代码生成到安全分析与自动化运维,模型能力正在逐步渗透进核心业务系统。与此同时,部署方式也从最初单纯依赖云端API,逐渐演变为本地化部署、私有化推理以及混合云架构——背后的驱动力,无非是数据安全、合规要求以及性能可控这几个硬性条件。
当模型从“一个可调用的能力接口”变成“企业内部运行的基础设施”时,它的安全边界也就发生了根本性的变化。换句话说,构建企业级大模型应用时,模型部署安全已经不是一个可以事后补救的环节,而是从一开始就必须考虑进去的关键变量。如何在不牺牲可用性的前提下,建立起完善的安全防护机制,确保模型运行环境、输入输出链路以及数据处理流程的安全可信,这正是当前AI工程与安全工程交叉领域最值得关注的研究方向。
生命周期
大模型的部署生命周期,本质上就是把“模型能力”从实验环境一步步推向“可控、可监控、可持续运行的生产系统”的过程。它很少是一次性上线的,主要包含以下几个环节:
模型选型:这个阶段的核心问题是“为什么用模型,以及用什么模型”。企业需要先明确具体业务场景——智能客服、代码生成、数据分析还是安全审计——然后根据任务复杂度选择适合的模型类型:闭源API、开源本地部署,或者混合架构。同时还要评估模型的能力边界,比如上下文长度、多语言能力、推理能力以及成本约束。另外,数据合规与隐私要求也在这一阶段就需要考虑进去,明确哪些数据可以进入模型体系。
模型获取:这个阶段关注的是“模型从哪里来,是否可信”。企业通常会从HuggingFace、ModelScope或商业厂商获取模型,也可能基于内部训练产出自己的版本。在这个环节,需要对模型权重做完整性校验——Hash校验、签名验证——同时评估供应链安全风险,看看是否存在模型投毒、后门或不可信的微调版本。此外,建立模型来源追溯机制也很关键,确保后续可审计性。
环境构建:这个阶段要回答“模型运行在哪里”。企业需要构建稳定的推理运行环境,包括GPU/CPU资源规划、容器化部署(Docker/Kubernetes)、推理框架选择(vLLM、TGI、Ollama等),以及CUDA、驱动和依赖库的配置。环境隔离与权限控制在这一阶段非常关键,目的是避免不同模型服务之间的资源冲突或越权访问。
性能优化:这个阶段解决的是“如何让模型在企业场景中更高效、更可控”。通常包括Prompt模板设计、指令对齐、LoRA或SFT微调、模型量化以及推理优化等。同时,还会针对企业数据进行领域适配,使模型更贴合特定的业务语境。
服务封装:这个阶段的目标是把模型能力转化为“可调用的服务”。企业通常会对模型进行API封装(REST/gRPC),引入统一的模型路由层(Multi-Model Router),同时实现身份认证(API Key/OAuth/RBAC)、访问控制、请求限流以及审计日志记录,形成标准化的模型服务治理体系。
部署发布:这个阶段开始进入生产环境交付。通常采用灰度发布或分批上线方式,结合多副本部署实现高可用能力。还需要配置负载均衡、健康检查以及故障回滚机制,确保模型服务在生产环境中的稳定性与可恢复性。
运行监控:这个阶段负责“持续运行过程中的安全与稳定性保障”。企业需要监控模型的性能指标(延迟、吞吐量)、系统资源消耗以及服务可用性。同时,安全风险也是重点——Prompt Injection攻击、敏感信息泄露、越权调用以及异常请求行为,都需要通过日志审计与检测系统进行识别和响应。
迭代治理:这个阶段形成整个生命周期的闭环机制。企业通过模型版本管理、数据反馈训练(RLHF/DPO)、红队测试以及安全策略更新,不断优化模型能力与安全性。同时,也负责模型生命周期治理,包括模型退役、版本回滚以及策略更新,确保系统长期可持续演进。

模型选型
企业在大模型选型时,通常需要从多个维度综合评估。这本质上是一个在“能力、成本、安全与可控性”之间做平衡的工程化决策过程,远不只是“效果好不好”这一个指标。主要包括以下几个方面:
业务适配性:模型在目标任务上的能力表现,比如代码生成、文本理解、多轮对话、多模态支持以及行业知识覆盖程度。
成本与性能:评估推理延迟、吞吐能力、Token成本,以及在高并发场景下的稳定性。
部署与可控:是否支持本地化部署、是否支持私有化微调、是否具备模型版本管理能力。
安全与合规:数据是否出域、供应商是否保留数据、是否支持审计与访问控制、是否满足行业监管要求。
生态与扩展:模型是否支持工具调用(Tool Calling)、Agent框架集成、RAG能力,以及与企业现有系统(比如MCP、知识库、API网关)的兼容性。
供应链风险:模型更新可控性、服务稳定性以及长期依赖风险。
风险场景
开源模型供应链投毒风险
风险介绍
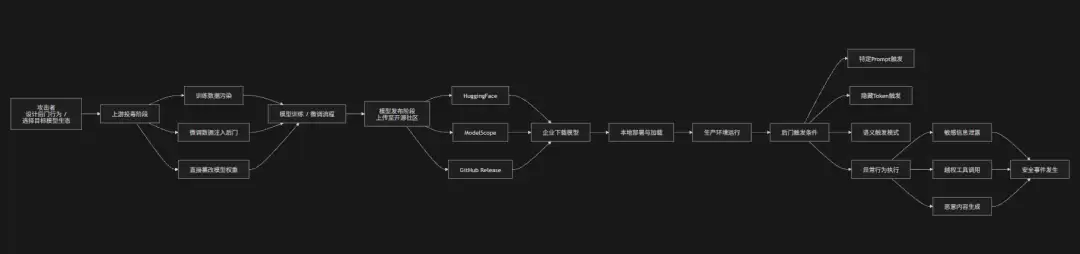
当企业决定拥抱开源大模型,第一个需要警惕的坑就是供应链投毒。简单来说,攻击者通过污染模型从“发布到使用”的分发链路,让企业最终加载和运行的模型,已经在源头或中间环节被植入了恶意行为。
由于开源模型通常依赖第三方平台(比如HuggingFace、ModelScope、GitHub Release)进行分发,企业往往直接下载权重文件或微调版本,而无法完整验证其训练过程与数据来源。攻击者在上游阶段对训练数据投毒、在微调过程中植入后门,或者直接篡改模型权重文件——这就导致模型在正常测试环境下表现完全正常,但在特定触发条件下(比如特定Prompt、隐藏Token或语义模式)执行恶意行为,比如泄露系统提示词、生成攻击代码或绕过安全策略。
这类攻击的危险性在于其“隐蔽性强、传播范围广、难以回溯”。一旦受污染模型被纳入生产环境,就等于把不可见的攻击能力引入了内部系统。
攻击链路
防御措施
模型来源白名单机制:模型下载时,仅允许从官方仓库或企业认证的模型源(比如HuggingFace官方组织、内部Model Registry)下载模型,禁止直接使用未知来源或未审计的社区模型。
模型发布者版本追溯:模型下载后,需要对模型进行完整性校验检查——使用SHA256等方式校验模型权重、配置文件与Tokenizer是否被篡改。
模型版本管理与回滚:做好版本控制管理,一旦发现或监测到对应版本的模型存在投毒、越狱等风险,可以快速切换到可信版本,降低投毒模型造成的持续影响。
开源模型微调数据污染风险
风险介绍
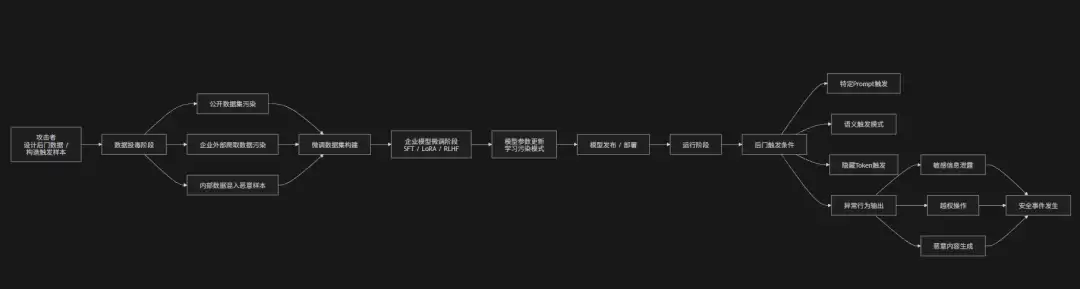
企业在使用开源模型进行微调(Fine-tuning/SFT/LoRA)时,面临的“微调数据污染风险”本质上也是攻击者通过操控训练数据集,让模型在学习过程中吸收错误、恶意或带有隐藏后门的行为模式。
由于企业通常会从内部业务数据、外部公开数据或第三方数据源构建微调语料,数据来源如果未经严格清洗或被恶意注入,攻击者就可以通过“数据投毒”的方式影响模型参数更新。结果就是模型在正常测试集上表现良好,但在特定触发条件下(比如特定关键词、语义模式或上下文结构)输出异常结果——泄露敏感信息、生成不安全内容或绕过安全对齐策略。
这类攻击的隐蔽性极强,因为它发生在模型训练阶段,属于“学习过程中的污染”,传统运行时安全检测手段往往难以发现。
攻击链路
防御措施
微调数据来源分级与白名单:仅允许可信数据源进入训练集,针对外部爬取数据、第三方数据集和众包数据进行分级评估与准入控制,避免未知来源数据直接参与微调。
微调训练数据清洗与毒性检测:数据进入训练前进行去重、异常样本检测、语义一致性校验以及恶意模式识别,降低隐藏后门样本混入的概率。
数据投毒特征检测与安全过滤:结合规则与模型方式识别异常标记(trigger token、异常标签映射、低频触发语义组合),拦截潜在后门样本。
微调数据审计与版本追溯记录:微调数据进行版本管理与可追溯记录,确保可回溯到具体数据源与处理流程,便于安全审计与回滚。
闭源模型数据安全合规风险
风险介绍
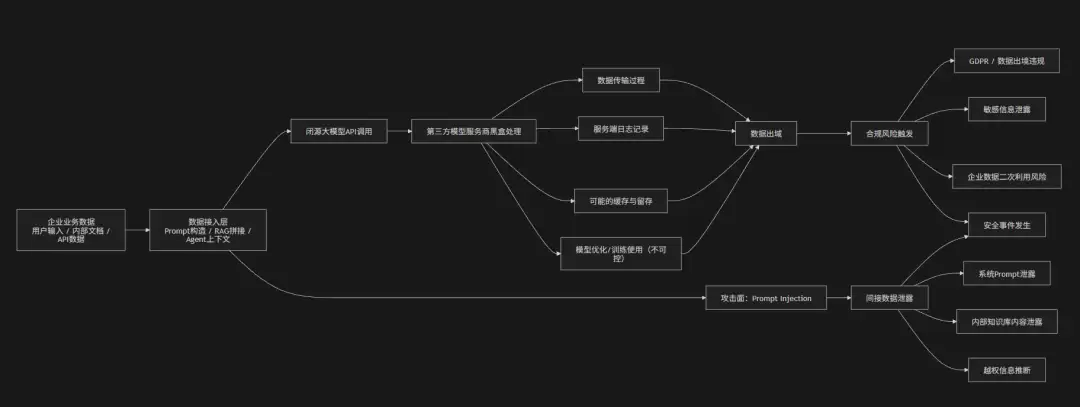
企业在使用闭源大模型(API形式,比如商业LLM服务)时,数据安全与合规风险的核心特征可以概括为三个词:数据出域不可控、处理过程黑盒化、合规责任外包不完整。
企业将用户输入、业务数据或内部知识通过API发送给第三方模型服务时,数据在传输与推理过程中可能经过外部服务商基础设施,其存储、日志记录、缓存机制以及是否用于模型训练往往缺乏完全透明性。这不可避免地带来了数据泄露、合规违规(比如GDPR、数据出境合规)、敏感信息被二次利用等风险。
必须警惕的是,在Agent或RAG场景下,如果将企业内部文档、数据库查询结果或权限信息拼接进Prompt上下文,一旦发生Prompt Injection或越权调用,隐私数据可能被间接推理或输出泄露。此外,由于闭源模型内部机制不可审计,企业难以验证数据是否被持久化、是否跨区域存储、是否参与后续模型优化——整体风险呈现出“可用但不可控”的特征。
攻击链路
防御措施
数据分级与最小化输入原则:在调用闭源模型前,对输入数据进行分级管理与脱敏处理,仅传输完成任务所必需的最小数据集,避免敏感信息(比如密钥、身份证号、内部配置)进入Prompt或RAG上下文。
敏感数据统一脱敏处理:在数据进入模型前进行结构化脱敏(替换、遮蔽或Token化),确保即使数据被外泄,也无法直接还原原始敏感内容。
闭源模型服务商合规审查:针对API提供方进行安全与合规评估,包括数据是否用于训练、是否跨境存储、日志保留策略、数据隔离机制,以及是否具备合规认证(比如ISO27001、SOC2等)。
数据不落盘与零留存策略:优先选择支持“Zero Data Retention”的模型服务,并在合同或配置层明确禁止服务端存储用户输入与输出数据——虽然写在合同里有时候也不一定靠谱。
RAG知识库访问权限控制:针对检索系统中的文档与数据源进行细粒度权限控制,确保模型仅能访问其授权范围内的信息,防止越权检索。
开源模型内网部署环境隔离
风险介绍
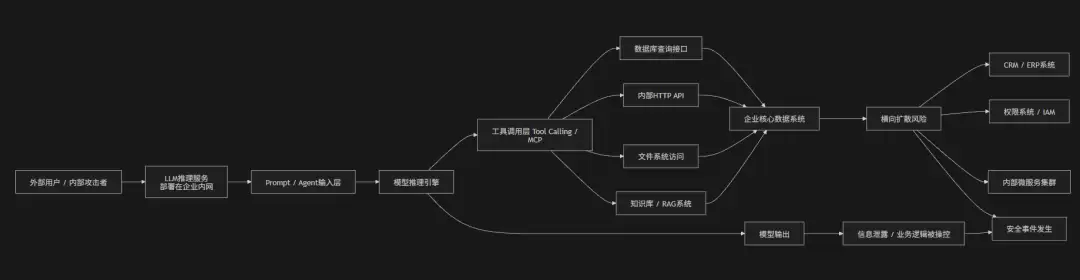
企业在内网部署开源大模型时,如果没有单独构建AI安全域(AI Zone),而是直接把模型推理服务部署在企业通用内网环境中,与数据库、微服务、文件系统、API网关等内部系统直接互通——这种情况下的架构问题在于:AI系统变成了一个“内网高权限中枢节点”。
问题的核心是——大模型已经不再只是一个被调用的服务,而是一个可以访问企业内部资产的“智能执行节点”。模型一旦被Prompt Injection、Agent工具滥用或应用层漏洞利用,就可能直接触发内网API调用、数据库查询、文件读取,甚至横向访问其他业务系统,从而绕过传统的零信任边界控制。
更麻烦的是,由于缺乏AI专属隔离域,日志、缓存、RAG向量库、工具调用接口等也往往与生产系统共享基础设施,攻击者可以通过模型入口“借道”访问整个内网生态——这就形成了典型的“AI成为内网跳板”的风险结构。
攻击链路
防御措施
构建独立AI安全域:大模型推理服务从企业通用内网中隔离出来,部署在独立网络域或微隔离环境中,与核心业务系统通过受控AI网关交互,避免直接内网横向访问。
统一AI网关接入控制:模型访问内部系统(数据库、微服务、文件系统)必须通过统一AI网关进行编排与鉴权,禁止模型直接调用内网服务接口。
最小权限工具原则:对LLM可调用的工具(Tool Calling/MCP/Function Call)进行严格权限控制,仅开放业务必需能力,禁止默认全内网访问。
服务之间网络微隔离:通过VPC分段、安全组、K8s NetworkPolicy等方式,限制AI服务与其他业务系统的通信路径,防止横向移动。
敏感系统需二次认证:针对高敏感系统(比如IAM、支付系统、核心数据库)增加二次验证或人工审批机制,防止模型直接自动执行高危操作。
开源模型容器化部署风险
风险介绍
开源大模型容器化部署(Docker/Kubernetes)虽然大幅提升了部署效率与可移植性,但也引入了一类典型的基础设施安全风险:容器边界薄弱、配置复杂、默认权限过高。
在实际落地中,许多LLM服务为了方便调用GPU、挂载模型权重或加速推理,会默认使用特权容器(privileged container)、挂载宿主机目录或开放过多系统能力(SYS_ADMIN、GPU device访问等)。这带来的问题是:容器内部的推理服务、API接口或依赖库如果存在漏洞,攻击者就有可能通过Prompt Injection联动工具调用漏洞、Web服务漏洞或依赖包RCE漏洞,实现容器逃逸,进一步访问宿主机资源。
此外,模型容器通常还会挂载模型文件、向量数据库、日志目录与缓存数据,如果缺乏隔离与加密控制,这些敏感数据可能被直接读取或外泄。在K8s环境中,如果RBAC配置不当或ServiceAccount权限过大,还可能形成从单个模型Pod横向扩散至整个集群的攻击路径。
攻击链路
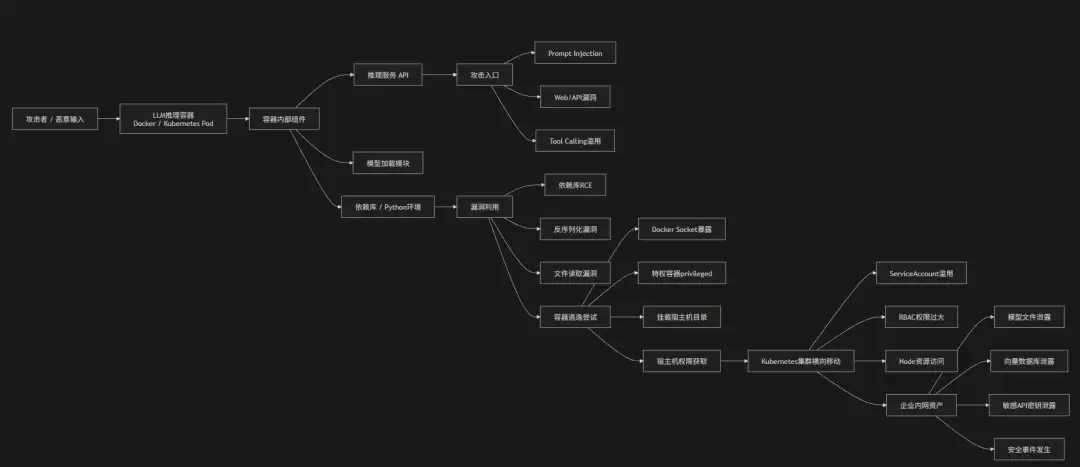
防御措施
容器最小权限运行原则:禁止使用privileged容器运行LLM服务,严格限制capabilities(比如SYS_ADMIN、NET_ADMIN等),以非root用户运行推理服务,降低容器逃逸风险。
宿主机资源隔离与只读挂载:对模型权重、配置文件、日志目录进行只读挂载(read-only mount),避免容器内进程篡改或回写宿主机关键文件。
Docker Socket与敏感接口隔离:禁止将/var/run/docker.sock挂载到容器内,防止攻击者通过容器直接控制Docker守护进程实现宿主机接管。
Kubernetes RBAC最小权限控制:对LLM Pod绑定独立ServiceAccount,严格限制其访问API Server的权限,避免通过K8s接口横向扩散。
网络策略微隔离(NetworkPolicy):使用K8s NetworkPolicy或Service Mesh,限制容器之间及容器到内网系统的访问路径,仅开放必要端口与服务。
镜像安全扫描与供应链防护:对基础镜像与依赖库进行漏洞扫描(CVE检测),使用可信镜像仓库与签名机制,防止恶意镜像注入。
开源模型推理框架自身风险
风险介绍
企业在使用开源大模型时,通常会依赖vLLM、TGI(Text Generation Inference)、Ollama、TensorRT-LLM等推理框架来提升性能。这些框架本身也构成了一个独立且容易被忽视的攻击面。安全风险主要来自三个方面:
资源滥用风险:攻击者通过超长Prompt、递归调用或高并发请求,耗尽GPU显存与计算资源,导致服务不可用。
接口暴露风险:推理框架通常提供HTTP/gRPC服务接口,如果未做鉴权或暴露在内网甚至公网,攻击者可以直接通过构造请求触发模型推理或执行未授权操作。
代码执行风险:部分框架支持动态加载模型、插件或自定义算子,一旦依赖库存在漏洞或加载恶意模型文件,可能触发反序列化漏洞、远程代码执行或路径遍历。
攻击链路
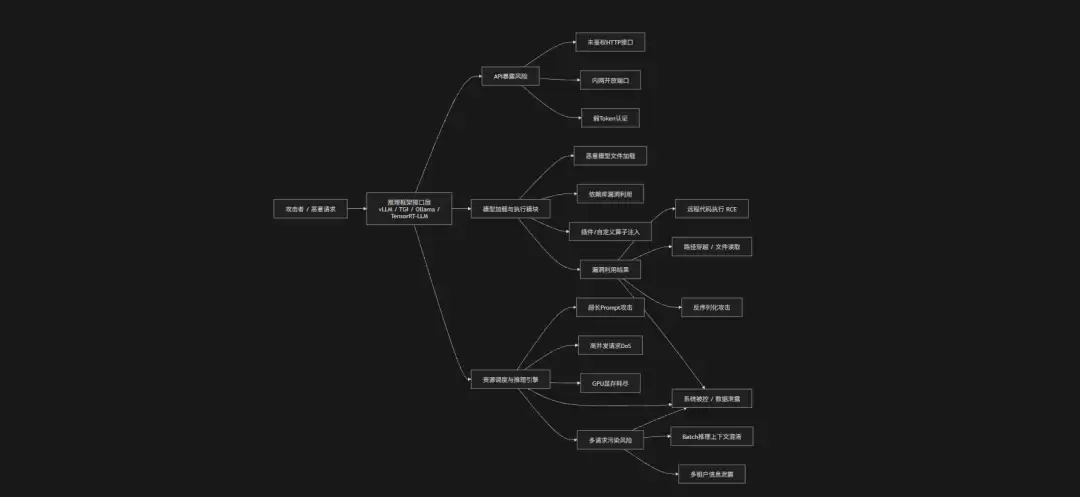
防御措施
模型加载安全校验机制:对加载的模型文件进行Hash校验、签名验证与来源校验,防止恶意模型文件或被篡改权重触发后门行为。
依赖库与推理框架漏洞管理:对vLLM/TGI等框架及其Python/C++依赖进行CVE扫描与版本锁定,定期更新修复已知RCE与反序列化漏洞。
输入长度与资源使用限制:对Prompt长度、最大Token数、并发请求数进行严格限制,防止超长输入或高并发导致GPU显存耗尽或服务DoS。
推理任务隔离与多租户安全控制:在多用户或多业务场景下,采用隔离推理队列或独立Worker,避免Batch推理导致上下文污染或信息泄露。
API网关统一入口与访问控制:所有推理请求必须经过统一API网关进行鉴权、限流与审计,禁止直接访问推理框架原生端口,避免绕过安全策略。
推理服务接口强鉴权与零暴露原则:推理框架(vLLM/TGI/Ollama等)必须默认关闭公网暴露,仅允许通过内网API网关访问,并启用强认证机制(API Key + mTLS + RBAC),防止未授权调用。
RAG与知识库被污染风险
风险介绍
企业在使用闭源大模型结合RAG与知识库增强能力时,会引入一类典型的“检索层数据污染攻击风险”。由于闭源模型本身不可控,企业通常依赖外部知识库(比如向量数据库、Wiki文档、FAQ系统、日志数据等)作为模型推理的外部上下文来源——这些知识源一旦被攻击者注入恶意内容,就可能在检索阶段被模型误引用,从而间接影响最终输出结果。
攻击者可以通过投放伪造文档、SEO污染、API写入篡改或利用权限漏洞向向量数据库注入恶意向量,使其在语义检索时被优先命中,从而诱导模型生成错误信息、泄露敏感数据或执行错误操作。在Prompt Injection与RAG结合的场景下,恶意内容还可能携带“指令型文本”,诱导模型绕过系统提示词限制,进一步扩大攻击影响范围。
这类攻击的本质是:攻击者不直接攻击模型,而是污染模型依赖的外部知识来源。
攻击链路
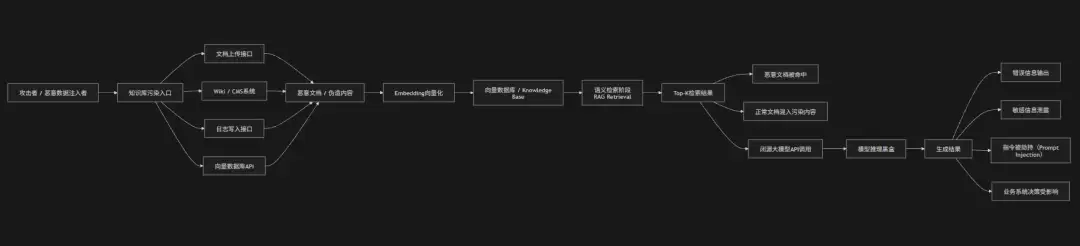
防御措施
向量数据访问控制隔离:针对向量数据库实施细粒度访问控制(RBAC/ABAC),避免不同业务、不同租户之间的数据交叉污染或越权检索。
数据写入权限隔离控制:对文档上传、日志写入、向量数据库写入等接口进行权限控制,采用最小权限原则,防止攻击者通过写入接口注入恶意内容。
RAG数据清洗与内容安全检测:在数据进入Embedding前进行文本安全过滤,包括恶意指令识别、Prompt Injection检测、异常语义模式分析与敏感内容扫描。
知识源准入与分级管理:对RAG数据源进行严格分级与白名单控制,仅允许可信系统(比如受控CMS、官方文档库、经过审核的数据库)进入索引体系,禁止任意外部或用户可写数据直接进入知识库。
闭源模型请求链路风险
风险介绍
企业在使用闭源大模型(API形式)时,请求链路本质上是一条从“业务系统 → Prompt构造 → 网络传输 → 第三方模型推理 → 返回结果”的跨边界数据流。在这个链路中的每一个环节,都可能引入安全风险。
首先是客户端与业务层,风险来自Prompt构造不安全(比如拼接用户输入与系统指令导致Prompt Injection)、敏感数据未脱敏直接进入请求体,以及应用层逻辑错误导致越权信息被拼接进上下文。
其次是API调用与传输层,存在API Key泄露、请求被中间人攻击、日志抓取导致数据泄露以及请求重放攻击等问题。
在网关与袋里层(比如企业API Gateway或LLM Proxy)中,如果缺乏鉴权、限流与审计能力,可能导致滥用调用、Token耗尽攻击或绕过策略访问模型。
进入第三方模型服务层后,风险转变为黑盒不可控——数据是否被存储、是否用于训练、是否跨区域流转,以及服务端日志留存带来的合规风险。
最后,在响应返回与业务消费层,模型输出可能携带被污染信息、敏感数据泄露内容或被Prompt Injection操控的结果。如果未进行输出过滤,还可能直接影响业务决策系统。
值得强调的是,在Agent或Tool Calling扩展场景下,请求链路还会延伸至外部工具执行层,使攻击面进一步扩大到数据库、API服务甚至内网系统。
攻击链路
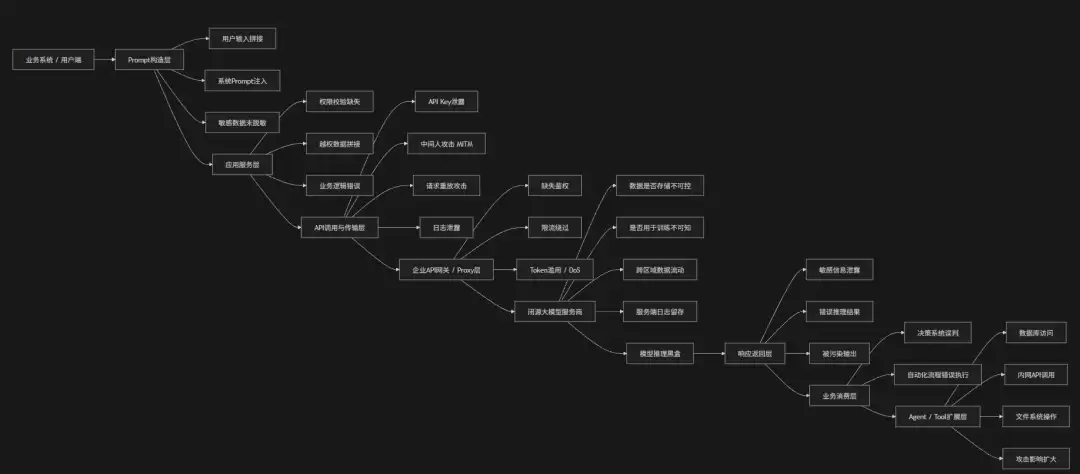
防御措施
统一AI安全网关接入与访问控制:所有闭源模型调用必须通过统一AI安全网关进行鉴权、限流与审计,禁止直接访问模型API接口,防止策略绕过。
输入侧安全治理与Prompt构造规范:业务系统构造Prompt时,实施严格的输入校验与结构化拼接,比如通过提示词注入检测能力,降低Prompt Injection与数据泄露风险。
敏感数据输入/输出脱敏处理能力:在进入模型请求链路前对数据进行分级处理,仅传输完成任务所需的最小信息集,并对PII、密钥、内部系统信息进行Token化或掩码处理。
文末小结
大模型正在从技术探索阶段走向企业级生产应用。模型部署已经不是简单的基础设施建设问题,而是涵盖模型、数据、平台、网络、应用以及运营管理等多个层面的系统性安全工程。
从模型选型、供应链管理、训练与微调、推理框架部署,到RAG知识库建设、请求链路安全以及Agent能力扩展——每一个环节都可能成为攻击者利用的入口。对企业来说,大模型带来的不仅是智能化能力的提升,也意味着攻击面和安全责任边界的进一步扩大。
无论是开源模型面临的供应链投毒、数据污染、容器与推理框架风险,还是闭源模型涉及的数据安全、合规治理、知识库污染以及请求链路风险——都需要企业建立覆盖全生命周期的安全防护体系,而不是依赖单一产品或单点技术进行防御。
未来,大模型安全建设将逐步从传统的网络安全、应用安全向AI安全演进。企业需要围绕“可信模型、可信数据、可信环境、可信调用”四个核心目标,构建覆盖模型生命周期的纵深防御体系,将安全能力融入模型部署、运行和治理的全过程。只有在安全与业务价值之间建立平衡,大模型才能真正成为企业数字化转型和智能化升级的重要生产力——而不是新的风险来源。




