OpenAI终于正式出手,发布了万众期待的GPT-5.2模型。这一全新模型基于英伟达Blackwell与Hopper架构的AI GPU进行训练和部署,堪称当前公开信息中最前沿的人工智能模型之一。官方数据相当亮眼:企业用户每天可节省40至60分钟工作时间,重度用户一周甚至能腾出超过10个小时。这些节省的时间究竟去了哪里?或许答案就藏在这个新模型之中。
驱动这颗新智脑的核心,正是英伟达整套AI基础设施。Hopper与Blackwell两大架构的AI GPU,不仅肩负模型训练的重任,也是运行部署的底层平台。我们常说“算力就是燃料”——如果说GPT-5.2是一辆顶级跑车,那么英伟达Blackwell架构GPU就是为其铺设的出色赛道。
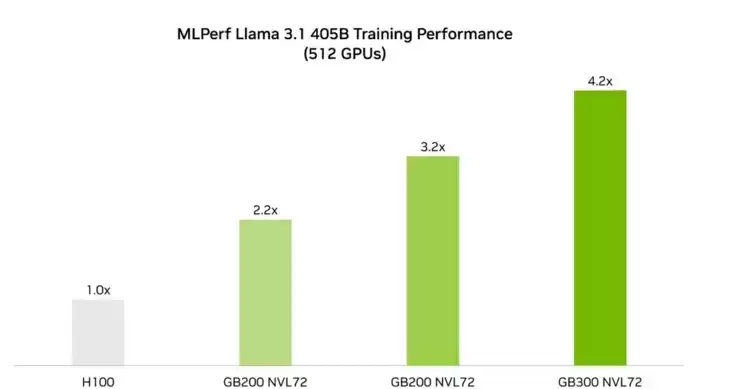
英伟达GPU究竟有多强?两个关键数字足以说明。在MLPerf v5.1基准测试中,Blackwell GPU凭借NVFP4精度模型与最新优化技术,较v5.0版本性能直接提升了45%。更值得一提的是,Blackwell Ultra平台将性能推至GB200 NVL72的1.9倍——与经典Hopper H100方案相比,性能飞跃高达4.2倍。该测试基于512个GPU规模,采用Llama 3.1 405B模型进行验证,数据极具说服力。
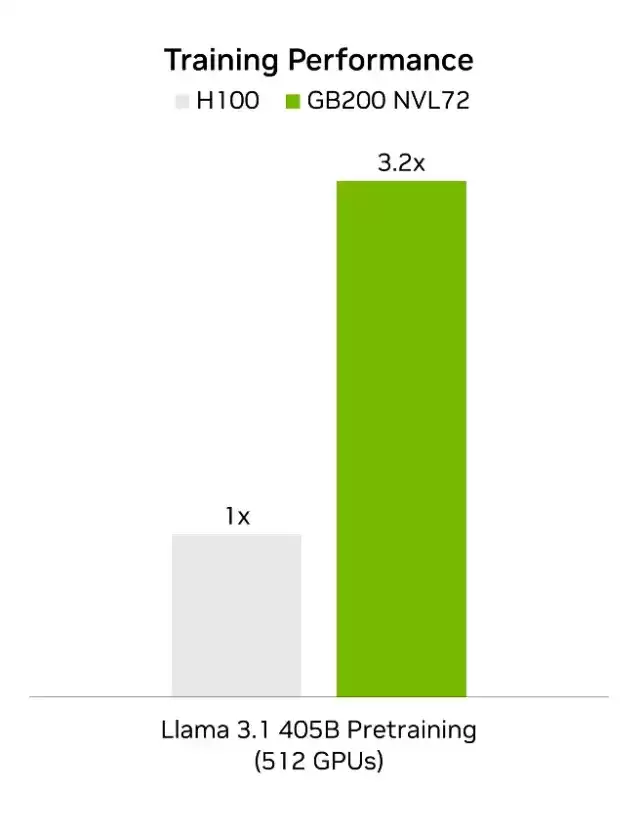
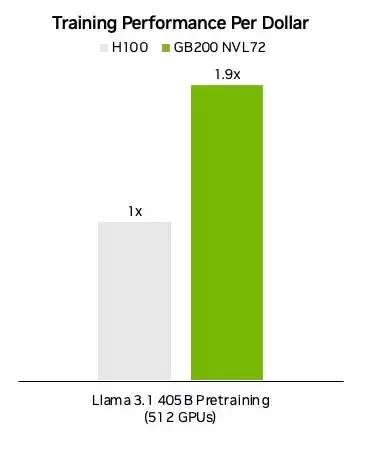
性能突破固然重要,性价比才是真正的较量。Blackwell GB200 NVL72平台在单位成本下的训练性能,相比前代H100方案提升了90%,同时整体训练性能实现了3.2倍的飞跃式增长。这意味着花费相同预算,可以换来接近双倍的训练效率。对于任何一家AI企业而言,这才是实实在在的商业竞争力。
目前,Blackwell与Blackwell Ultra GPU已在主流云服务商、新兴云平台以及服务器制造商中广泛部署。Blackwell Ultra正逐步从服务器厂商和云服务商处推出,而标准Blackwell实例已可通过主流云平台直接获取。算力市场的竞争火药味,这回确实愈发浓烈了。




