主流大语言模型有个通病:文本一长,它们就犯迷糊。上下文太长,记忆就开始混乱,不是答非所问,就是反应迟钝,甚至干脆罢工。问题的根源,出在Transformer架构本身的数学瓶颈上——计算量随文本长度呈平方级增长。换句话说,文本长度翻倍,算力需求就得翻四倍;长度翻三倍,算力需求就得翻九倍。一旦文本量达到百万级Token(大约相当于两三部《三体》),计算量直奔万亿次,再强的GPU也扛不住。
这就是为什么大多数商用模型的上下文窗口都卡在128K到200K Token之间。这个数字听起来不小,但真到了要分析一整年的客服工单、处理装着几百个文件的代码仓库,或是审阅一份300页的并购协议时,模型就算不动了。
不过,最近一家名为Subquadratic的初创公司声称,他们把这个瓶颈打破了。
那么,这个瓶颈到底是怎么来的?
AI在阅读一段文本时,必须把每一个词(Token)和文本里所有的其他词逐一比对,计算它们之间的关联。如果有n个词,大概就要算n²次——这就是二次方的增长。处理100万个词,就需要计算大约100万×100万=1万亿个词与词之间的关系。即便用上最先进的GPU,单次推理也要花上几分钟,成本高达几十甚至上百美元。如果扩展到1200万个词,那就是144万亿次计算,经济上已经完全不现实了。而Subquadratic推出的SubQ模型,正是要大幅削减这个计算量。
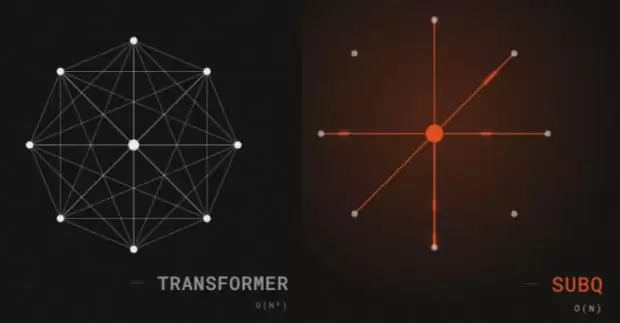
AI如何读懂一句话?
先看一个最简单的句子:“动物没过马路,因为它很害怕。”人一眼就能看懂,“它”指的当然是“动物”,而不是“马路”。但一个既没有眼睛也没有常识的AI,是怎么理解的呢?
第一步,AI得把文字变成数字。每个大语言模型内部都有一本巨大的词典,每个词(Token)对应一排固定长度的数字。比如,动物 = [0.8, 0.1, 0.3, 0.9],马路 = [0.1, 0.9, 0.2, 0.3],它 = [0.6, 0.4, 0.8, 0.5]。这一排数字叫向量,每个维度代表一种特性,相当于这个词在数学空间里的经纬度坐标。“动物”和“马路”在“是否有生命”这个维度上的数值差距很大(0.8 vs 0.1),机器一看就知道它们不是同类。
光有词向量还不够。在“狗咬人”和“人咬狗”这两句话里,“狗”和“人”各自的向量并没有变,模型分不清谁是施动者、谁是被动者。所以,必须给每个词贴上一个“座位号”,这叫位置编码。此后,每个词就变成了一个携带自身坐标和位置的数字包裹,列队进入模型真正的核心区域——Transformer(转换器)。
接下来的一步,是所有语言理解的起点:把离散的符号,变成连续的数学对象。Transformer要给每个词造三张身份牌,分别叫Q(Query,查询)、K(Key,键)和V(Value,值)。
- Q 代表“我在找什么?”
- K 代表“我是什么?”
- V 代表“我带了什么具体信息?”
造牌的方法很简单:词向量分别乘以三个不同的矩阵。这三个矩阵是模型在训练阶段自己学出来的,对每个词都一样。拿“动物”来说:Q可能是[1.0, 0.0, 1.0, 0.0](我在找一个能做动作的主语),K可能是[0.9, 0.1, 0.8, 0.2](我是有生命、能移动的实体),V可能是[0.2, 0.7, 0.5, 0.1](我身上的具体信息是“四条腿、毛茸茸”)。三者的用途截然不同:Q是拿出去提问的,K是供其他词匹配的,V是等着被提取的。同样,“它”也会生成自己的Q——[1.0, 0.0, 1.0, 0.0],它也在找“有生命的主语”。
现在,“它”拿着自己的Q,要去和句子中所有其他词的K做一次关系测试。这个测试在数学上就是两个向量的点积。先跟“动物”的K做测试:1.0×0.9 + 0.0×0.1 + 1.0×0.8 + 0.0×0.2 = 1.7。再跟“马路”的K做测试:1.0×0.1 + 0.0×0.8 + 1.0×0.1 + 0.0×0.9 = 0.2。1.7比0.2大得多——“它”跟“动物”之间的亲密度,远超跟“马路”的。
随后,利用Softmax函数,将各个点积转化为归一化的权重,也就是注意力权重。对于“它”这个词来说,“动物”占据大约68%的权重,“马路”只占32%。最后,把所有词的V按这个权重混合,生成一个全新的向量Z它 = 动物的V×68% + 马路的V×32%,得到[0.424, 0.508, 0.436, 0.324]。至此,“它”从一个没有上下文的空壳代词,变成了指向明确实体的词。在最终的Z它中,68%是动物的信息,32%是马路的信息。
以上操作被称为注意力层,本质上就是一次加权平均。但这种操作是线性的,光靠它,模型还学不会复杂的逻辑。因此,在每一层的“加权平均”之后,紧跟着还要加上一个前馈网络(FFN)。FFN的结构很简单:对Z先后施加两次线性变换,第一次大幅升维,第二次降回原维度,中间夹一个用来清零无关特性的筛选函数。这一步能提炼出更高层次的抽象特征,并从海量参数中检索出与当前上下文最相关的事实信息。注意力层让“它”指向“动物”,FFN则在这个基础上进行统计学联想,把“动物”“害怕”和“不过马路”匹配起来。
这只是第一层。在真实的Transformer架构中,通常有几十层这样的结构——GPT-4就有120层以上。每一层都在处理不同级别的抽象信息:浅层关注词性和语法,中层关注指代关系和语义角色,深层关注逻辑推理和情感。每一层的输出都是下一层的输入,每一层都在改写每个词的向量。第一层让“它”知道自己是“动物”,第二层让“动物”知道自己是“害怕”的主体,到了第30层,“动物”这个向量里已经浓缩了整句话的因果逻辑。
几十层简单操作的反复迭代和逐级抽象,这就是AI模型理解文本的秘密。
SubQ有何优化?
理解了Transformer的完整原理,也就明白了SubQ到底在优化什么。
在Transformer每一层的注意力层中,每个词的Q都要跟所有词的K算一遍点积,这叫密集注意力,是目前的主流做法。举个例子,AI要总结《红楼梦》,就必须同时看到从第一个词到最后一个词的全部词语,并把它们两两组合起来——不管这些组合有没有意义。假设在圆周上点出n个点,每个点代表一个词,然后在每两个点之间连一条线,代表一对组合。最终线条的条数是n(n-1)/2,简化后就是O(n²)。
而SubQ则把这个数目压缩到O(n log n)或O(n·k)(k是一个很小的常数)。如果n极大,削减量就相当可观。100万个词原本需要大约10¹²次运算,SubQ把这个数字压低大约64倍——这就是“算得动”和“算不动”之间的差别。到了1200万个词,差距就更大了:原方法的成本会变成天文数字,而SubQ的花费仍然在可承受范围内。
SubQ的办法是稀疏注意力——跳过那些不重要的组合,只算关键的组合。回到“动物没过马路,因为它很害怕”这个句子,人凭直觉就能判断“它”指代的是“动物”,根本不会去算“它”和“马路”的关系,更不会去琢磨“很”和“马路”之间有什么关联。问题在于:AI如何判断哪些关系重要,哪些不重要?
以前那些稀疏注意力的方法,大多依赖于固定模式。比如,每个词只跟它左右512个邻居计算点积,或者每隔一段固定距离再选一个词计算。这些方法确实压缩了计算量,但也让模型变成了近视眼——如果关键信息刚好隔了600个词,肯定就遗漏了。
SubQ模型的SSA架构所做的,就是在注意力层这一步引入了一个经过训练的智能筛选器。Subquadratic声称,他们的SubQ模型第一次实现了真正的动态选择性稀疏注意力:不靠固定规则,而是让模型自己学会判断——在当前这段文本里,哪些词与词之间的关系真的有用,然后只算这些组合之间的点积。关系模式随文本内容动态变化,每一段文本的关注清单都不一样。
检验与争议
Subquadratic上个月刚刚走出隐身模式,就发布了这个消息,很多人表示怀疑。一个月后,公司请了第三方评估机构来做独立测试。结果相当亮眼:在LiveCodeBench(编程能力测试)中,SubQ得分89.7%,跟OpenAI、Anthropic、Google DeepMind的顶级编程模型处于同一梯队。在大海捞针测试(长上下文检索)中,面对600万和1200万Token的上下文,SubQ达到了98%的准确率,属于近乎完美的顶尖水平。速度测试显示,SubQ比一种更早的稀疏注意力模型快了56倍。成本方面,在RULER 128测试中,Anthropic的Opus 4.6运行一遍的成本是2600美元,而SubQ只花了8美元。
独立测试的高分表现证明了SubQ的能力,但争议也随之而来。最关键的质疑点在于:SubQ并非从头开始训练,而是复用了中国开源模型Qwen已经训练好的模型参数,因此并不能完全证明SSA架构的优越性。一些研究人员认为,目前的公开证据还不足以说明SubQ已经彻底解决了长文本处理的瓶颈。此外,SubQ至今没有大规模开放试用,也让很多人持观望态度。
又一次变革?
目前,处理长文档的主流方案是RAG(检索增强生成)——把文档切成小块,先搜索相关内容块,再送给模型生成答案。但RAG有两个固有缺陷:第一,检索环节可能漏掉关键信息;第二,跨文档的复杂逻辑会被切碎。如果SubQ真的能以极经济的成本处理百万甚至千万级Token的上下文,情况将大为不同:模型可以直接吞下整份文档或整个代码库,无需任何中介替它筛选。
在跨文档分析方面,一次演示中,SubQ分析了400份文档里的信息,只需几秒就能做出回应,而Perplexity连400份文档都没能全部加载。
Subquadratic明确表示,公司正在逐步扩大访问范围,接下来的目标是继续优化SSA架构,并计划发布更多经过第三方验证的测试结果。他们踌躇满志,希望用SSA架构改变大语言模型的构建方式。“我们想开启一个新时代,”该公司联合创始人兼CEO Justin Dangel说,“我们认为,几年之后,谁也不会再用标准Transformer来建模型了。”
这话听上去很狂。但回想2017年,那篇题为《Attention Is All You Need》的论文刚发表时,很多人也觉得,抛弃AI的正统循环神经网络、代之以注意力机制,是个非常疯狂的想法。那时还没什么名气的OpenAI率先注意到了Transformer的潜力,五年后,ChatGPT横空出世,从此Transformer成了构建AI的主流方式。
变革会不会重演,取决于SubQ接下来的表现。此外,像OpenAI和Google这样的巨头是不是已经找到了同样的答案,只是秘而不宣?让我们拭目以待。
参考文献
https://www.technologyreview.com/2026/06/19/1139313/a-startup-claims-it-broke-through-a-bottleneck-thats-holding-back-llms/
https://www.mindstudio.ai/blog/what-is-sub-quadratic-sparse-attention-subq-ssa




