先说结论。在云端私有化部署这个领域,DeepSeek 模型的性能表现一直是业界关注的焦点。最近,针对两台 4090 服务器上运行的 deepseek-R1 模型,做了一组系统性的压力测试——从 5 并发一直拉到 55 并发,覆盖了从低负载到高负载的全场景。关键是,所有请求全部成功,没有一个失败。这一点,值得先放在这里。
从服务方案来看,智星云把 Deepseek 全系模型都纳入了支持范围,包括 R1 满血版、V3、70B、32B 以及各种量化版本。同时,提供了模型调优、RAG 知识库构建和实时联网搜索能力。集成的 Agent 智能体框架可以处理多任务,再加上多级鉴权体系,数据安全方面也算做得比较周全。这套方案适配不同规模的企业用户,算是针对性很强的定制服务。
那么,实际跑起来表现如何?来看测试数据。
DeepSeek 云端私有化方案测试报告
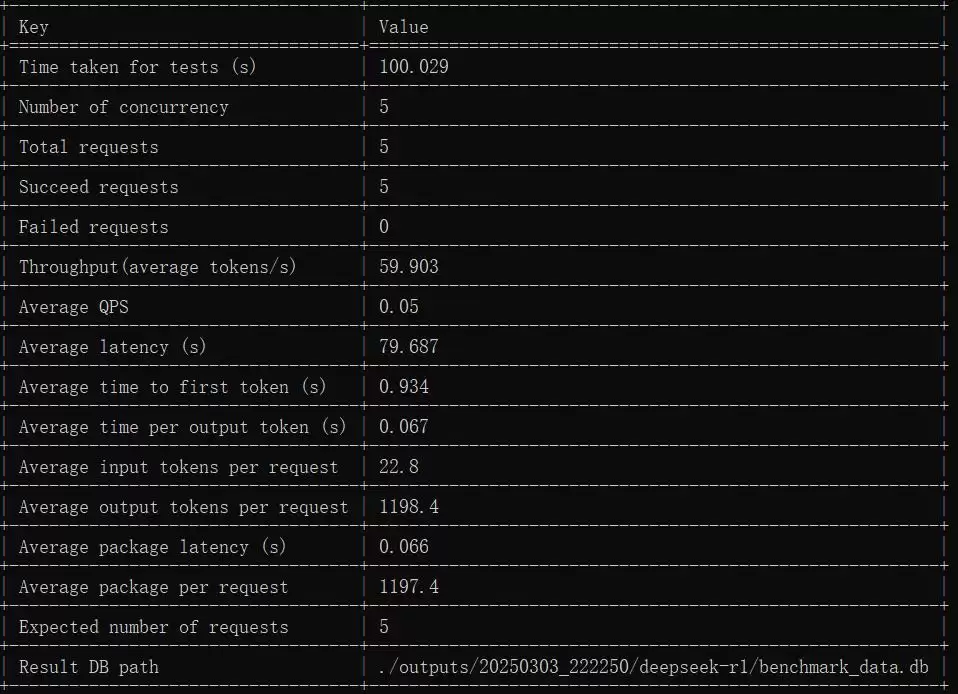
本报告针对两台 4090 服务器上部署的 deepseek-R1 大语言模型,在不同并发场景下(5 到 55 并发)进行了系统测试。测试指标涵盖整体耗时、吞吐量、每秒请求数(QPS)、平均响应延时、首 token 响应时间(TTFT)、每个输出 token 生成耗时(TPOT),以及输入/输出 token 数量。所有数据均来自标准 openqa 数据集。
综合各并发级别的数据来看,deepseek-R1 模型在低并发(5、15)下响应较快,但并发数一提高(25 至 55),吞吐量虽然不断上升,平均延时和每 token 生成时间也跟着往上涨。特别是在高并发场景下,尾部延时明显上升——不过,模型在高并发环境下依然能够稳定处理请求,没有出现断崖式崩溃。
吞吐量与并行数的关系,可以直观地从下图中看到:

一、测试环境与配置
- 模型信息:deepseek-R1
- 超时设置:连接与读取超时均为 120s
- 测试数据集:openqa
- 请求参数:最大输出 token 2048,输入 token 数约 22~28,输出 token 数大致在 650~1200 范围内
- 并发测试:共测试了 5、15、25、35、45、55 并发,无一例失败请求
二、各并发级别数据概览
下表展示了各并发场景下的核心指标(平均吞吐量单位:tokens/s;QPS:每秒请求数):
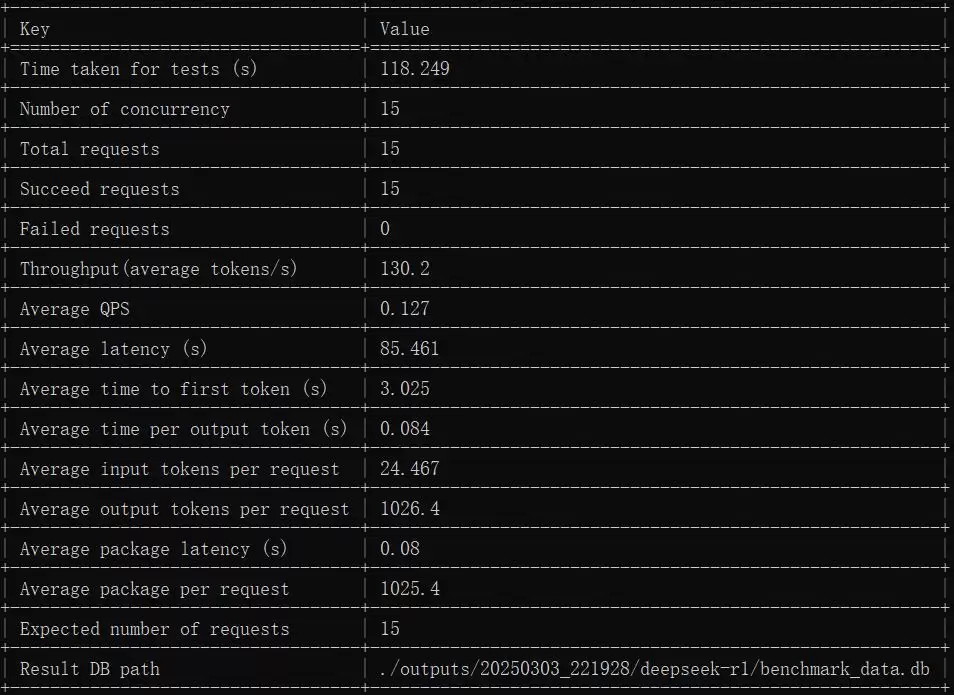
从 5、25、35、45、55 并发的测试数据来看,系统整体吞吐量随着并发数提高呈上升趋势,平均延时以及每个输出 token 的生成耗时也逐步增加。不过,15 并发测试中 TTFT 明显偏高(平均 3.025s),这可能受测试样本较少或调度偶发延时影响,属于可以关注的异常点。
三、关键性能指标
指标本身没有单独列出,但从各并发层级的走势可以提炼出几个关键判断:吞吐量与并发数正相关,但延时的增长曲线需要重点关注——尤其是在高并发场景下的尾部延迟表现。
四、详细数据
以下是各并发级别的具体测试结果,每个场景均附带完整数据图表。
5 请求 5 并发
15 请求 15 并发
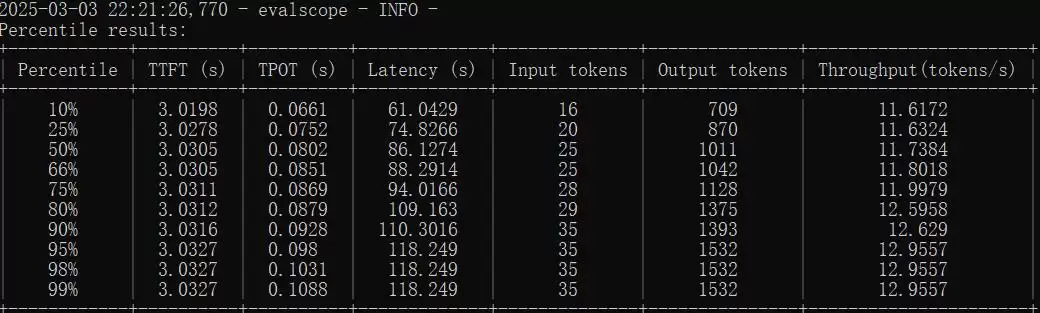
25 请求 25 并发
35 请求 35 并发
45 请求 45 并发
55 请求 55 并发