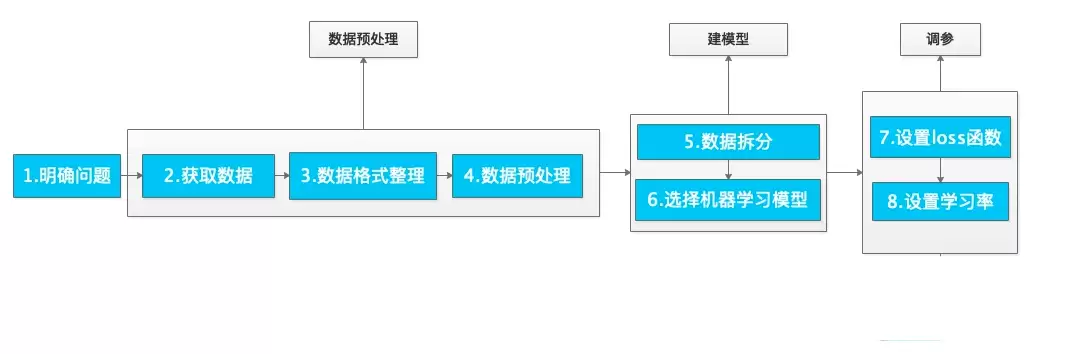
想要顺利交付一个机器学习项目,通常可以遵循以下几个步骤来推进。这套流程并非硬性规定,但在大多数实际场景中,按照这个顺序执行能显著减少返工与调试的麻烦。
1) 明确问题
首先要清楚要达成的业务目标。这一步的关键在于:如果公司已经积累了海量数据,就应当基于现有数据来定义目标;如果数据尚未采集,则需要先锁定目标,再反向推导所需的数据集类型。方向一旦偏离,后续所有努力都可能白费。
2) 获取数据
数据来源主要有两条路径:一是公司内部数据库(这是项目中最常用的渠道),二是利用公开数据集。常用的开源数据集平台包括UCI、Google Trends、Kaggle、AWS公用数据集、ImageNet、MNIST、麻省理工学院人脸识别数据集、歌曲数据库、COCO(图像处理领域)、YouTube视频数据集等。具体选哪个平台取决于任务类型,但切忌贪多,够用即可。
3) 数据格式整理
原始数据大多以数据库文件形式存在,其中的维度信息并非全部有用。需要先将数据转换为txt、csv、xsl等格式,方便机器学习库直接读取。接着对所有变量进行量化处理,最终整理为包含特征数据(Data)与标签(Labels)的数据框结构,这样才能直接进入建模环节。
4) 数据预处理
这一步的核心是“先打扫干净屋子再请客”。首先要做偏差检测,找出导致数据偏差的因素,识别离散点和噪声;然后进行数据清洗,处理缺失值与异常值;最后执行标准化,将不同维度的数据统一到相同的量级。
5) 数据拆分
将数据集随机打乱,按7:3或8:2(或其他合理比例)拆分为训练集和测试集。务必实现随机打乱,否则如果数据本身存在顺序性,模型可能会学到不正确的规律。
6) 根据场景选择合适的机器学习模型
选择模型时需要综合考量几个因素:数据的维度大小、数据质量、特征属性;可用的计算资源;项目组的时间预期;现有数据能否复用到其他项目。不同场景有不同的首选方法——如果目标是降维,主成分分析(PCA)是经典方案;需要快速完成手写数字预测,决策树或逻辑回归即可胜任;要做数据分层,则分层聚类更为合适。没有万能的模型,只有最适配当前场景的模型。
7) 设置损失函数
损失函数决定了模型优化的方向。常见的选择包括:
- 0-1损失函数:预测错误记为1,正确记为0,不考虑误差程度。
- 平方损失函数:计算预测值与实际值之差的平方。
- 绝对值损失函数:与平方损失类似,但采用绝对值,不会被平方放大差异。
- 对数损失函数(Log Loss)。
- Hinge Loss(常用于SVM模型)。
8) 设置学习率
学习率直接影响收敛速度与最终效果。对于不同大小的数据集,需要调整不同的学习率;更精细的做法是在每次迭代中动态调节学习率。通常可以从0.01或0.001开始尝试,再根据损失曲线的走势进行微调。
9) 测试与检验
使用测试集评估模型的泛化能力,看模型在实际场景中是否真的表现优异。如果效果理想,就可以部署上线;如果效果不佳,则需要回溯前面的步骤——数据、特征、模型、参数,总有一个环节需要优化调整。
综上,整个大致流程如下图所示: