 图像
图像
近日,Anthropic公司的Claude Code工程师Thariq在社交平台X上发表了一篇关于AI Agent设计的深度解析。这篇文章发布后引发了广泛关注——许多开发团队反馈,他们从过去那种将上下文视为“信息大杂烩”的传统RAG模式,转向了更为精细化的上下文构建方法,Agent的整体表现因此得到了显著提升。今天我们就来拆解这篇分享中的核心策略,探讨如何让Agent的执行更加稳健高效。
为什么说Agent设计是“艺术”而非“科学”?
Thariq直言不讳地指出:Agent设计更像是一门艺术创作——需要不断迭代、依靠直觉摸索,不存在标准答案。与传统软件工程不同,AI Agent面对的是一个“认知”过程,其核心难点在于如何引导模型高效完成任务,而非被海量信息所淹没。总结而言:切勿将Agent视为万能工具,而应将其设计为一个能够独立思考和决策的智能体。
工具数量别贪多,4–5个就足够了(真的)
这是最常见的设计误区:一次性给Agent配置过多工具,就像让它捧着一整家五金店的浣熊,四处乱抓,疯狂调用大量无关功能,Token消耗居高不下,还容易陷入死循环。正确的做法是——像为顶级厨师准备厨具一样,只保留最得心应手的几把刀、一口锅和一把铲子。将工具数量精简至4-5个,命名越直观越好,这样模型的运行表现反而会更加稳定。
举个例子:
• 糟糕的命名:execute_arbitrary_query_v3_advanced
• 优秀的命名:SearchWeb、ReadFile、WriteCode、AskUser
站在模型的视角来思考:它眼中只有提示词中那几行工具描述。如果描述过于啰嗦或模棱两可,模型就会做出一些令人费解的选择。
渐进式信息披露——这是效率提升最大的关键点
一次性把两万字的系统提示全部塞进上下文,是最低效的做法。上下文会逐渐“变质”:前面重要的信息被后面的噪音淹没,模型会慢慢“失忆”。我们现在几乎全部改用这种方式:
• 根目录中放置一份简短的 summary.md,作为技能总览,内容控制在一两屏内可以看完
• 具体的工具说明、知识库和流程文件则放入嵌套文件夹的markdown中,例如:
• /skills/search.md
• /skills/code-review/grep-patterns.md
• /memory/company-knowledge/product-specs.md
Agent只会在真正需要的时候,才会主动调用 ReadFile 工具去翻查更深层的文件。这就好比做菜时,你不会一次性读完整本菜谱,而是只找到“红烧肉”那一页仔细阅读。采用这一策略后,许多团队反映Agent的表现从“经常跑偏”直接飞跃到了“像拥有大脑一样可靠”。
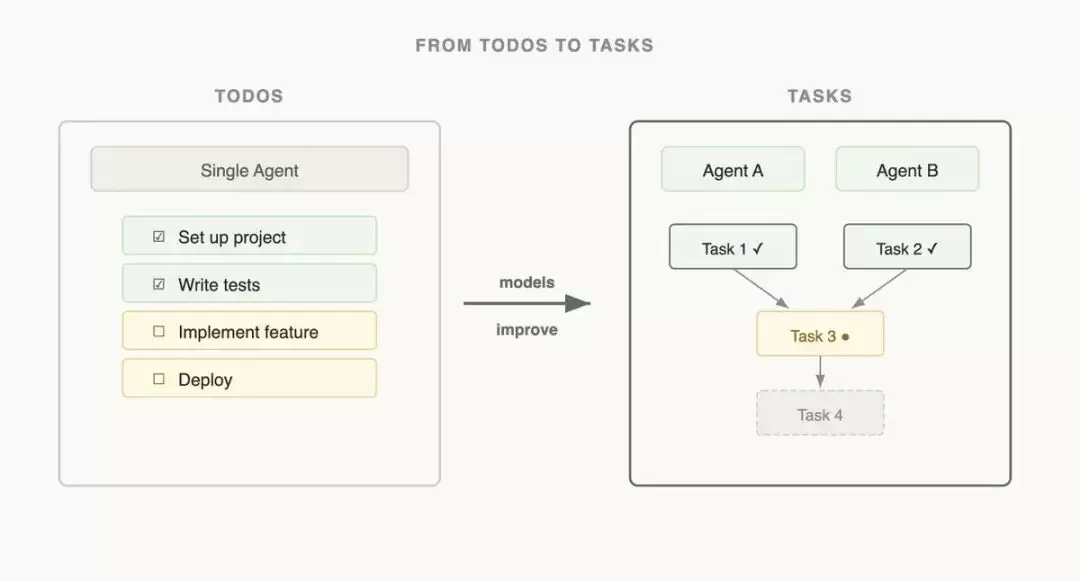
使用“任务”而非“待办清单”来管理
 图像
图像
传统的ToDo列表会导致提示词无限膨胀。更优的做法是将状态(Memory)与计算(Interaction)进行解耦。Memory层通过文件或文件夹持久化存储(JSON、Markdown均可),而Interaction层只负责处理当前这一步需要执行的具体操作。多个子Agent之间可以共享同一份Memory文件,无需在提示词中重复填充状态信息。这样不仅能大幅降低Token消耗,也让调试过程变得轻松许多。
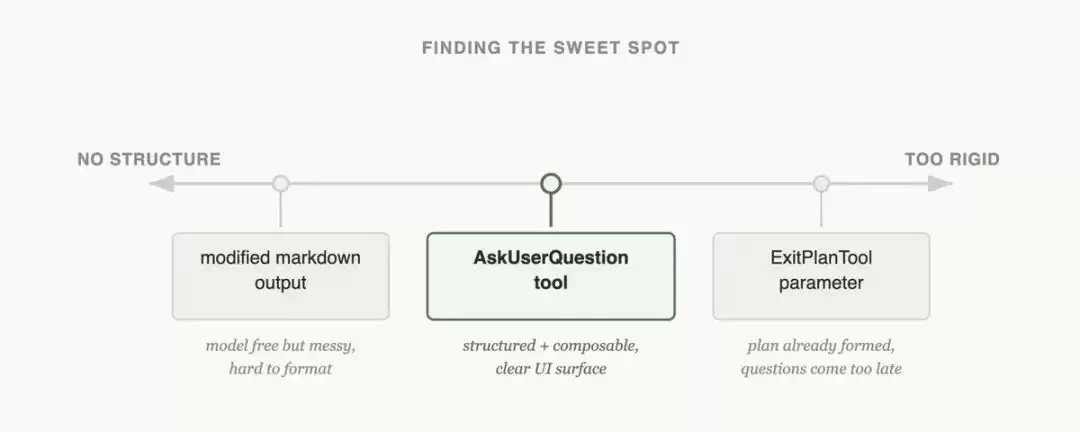
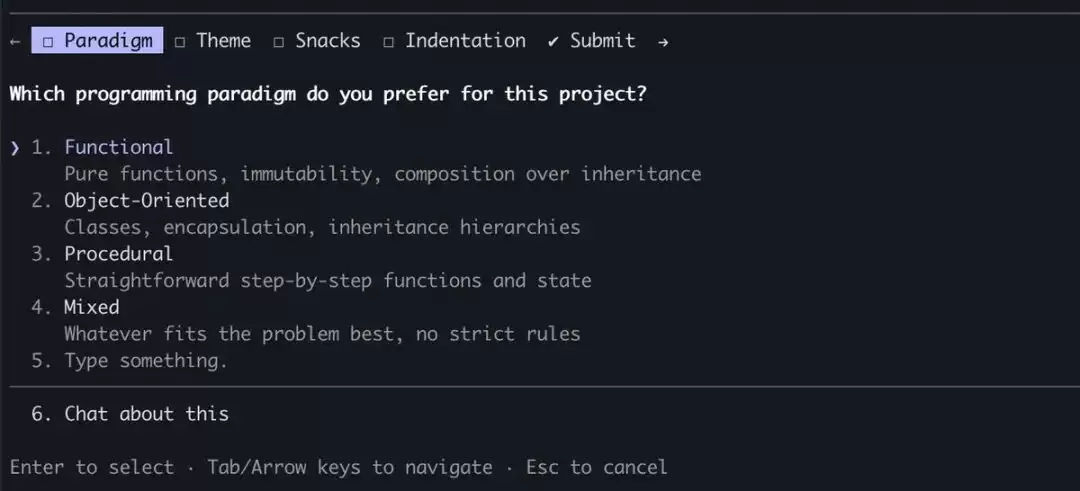
务必配备“AskUserQuestion”工具
 图像
图像
当遇到歧义或需要确认时,不要让模型自己凭空猜测,而是直接向用户提问。这是防止无限循环最简单直接、也是最有效的方法。
危险操作前必须“预览计划,等待确认”
删除文件、调用付费API、发送邮件等操作之前,务必让模型先输出完整计划——明确列出操作步骤、预期结果,然后等待你明确回复“Yes”。有人甚至专门构建了一个 ExitPlanTool,输出结构化计划,待用户确认后才真正执行。这不仅关乎系统安全性,更让整个操作流程变得可控。
文件系统竟然是目前最好的“AI大脑”
最令人意外的发现是:为AI提供长期记忆和技能扩展的最佳方式,竟然就是——好好整理文件夹和Markdown笔记。将简短总结写在前面,具体细节往深层嵌套,Agent需要时自己会去翻阅。这比塞入一个巨型提示词要更干净、更易维护、更便于版本控制和搜索。如今,许多构建者已经将文件系统视为“Agent的交互界面”来设计。
从AI的视角重新审视你的Agent
Thariq的分享并非孤立的技巧,而是对Agent设计的一次哲学性反思:像Agent一样去思考。从人性化工具到Token优化,一切的核心都指向同一个方向——Seeing like an agent。这不仅是提升AI Agent性能的实用指南,更是重新定义人机协作方式的深度思考。




