DAPO与Dr.GRPO长度偏置问题深度解读
时间:2026-07-02 12:06
上一讲从代码层面解释了GRPO为何能省略critic——本质上是利用同一条prompt的多条response在组内计算相对baseline,而无需单独训练一个value model。但省略critic后,最容易被低估的问题是什么呢? 先给出核心判断:DAPO-style recipe和Dr GRP
上一讲从代码层面解释了GRPO为何能省略critic——本质上是利用同一条prompt的多条response在组内计算相对baseline,而无需单独训练一个value model。但省略critic后,最容易被低估的问题是什么呢?
先给出核心判断:DAPO-style recipe和Dr. GRPO关注的不是“增加一个模型角色”,而是reward形状、advantage归一化以及loss聚合方式。它们实际上都在处理同一个工程现实:LLM后训练阶段,response长度从来不是中性变量。长答案会影响reward如何计算、advantage如何广播、token loss如何聚合、显存如何分配,以及rollout阶段的长尾分布。
先看整体组合图。注意:在verl示例中,DAPO-style recipe仍然设置`algorithm.adv_estimator=grpo`,真正变化的是reward manager、overlong buffer、actor clip、loss聚合和动态batch这些训练旋钮。
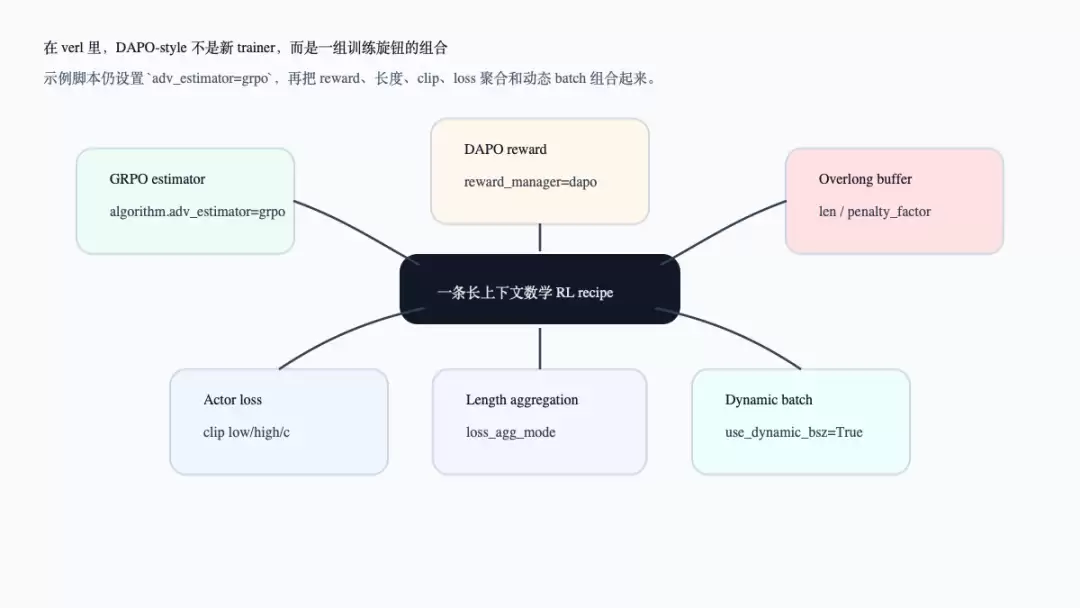
这张图对应`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh`的配置组合:算法依然是`adv_estimator=grpo`,in-reward KL关闭;reward manager设为`dapo`,并开启overlong buffer;数据侧设置最大prompt/response长度;actor侧设置dynamic batch、clip ratio和`loss_agg_mode`(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`)。
### 1. DAPO-style recipe优先调整reward形状
DAPO在该仓库中的直接代码入口是`DAPORewardManager`。它注册名为`"dapo"`,初始化时接收`max_resp_len`和`overlong_buffer_cfg`;若启用overlong buffer,则需要`max_resp_len`存在,且buffer长度必须为正(参考`verl/workers/reward_manager/dapo.py:25-56`)。
reward计算时,manager会解码prompt/response,调用`compute_score()`获得基础score,然后如果启用了overlong buffer,则根据response的有效长度计算额外惩罚:`expected_len = max_resp_len - overlong_buffer_len`,超过expected_len的部分按比例扣分,最后将reward写入最后一个有效response token上(参考`verl/workers/reward_manager/dapo.py:71-132`)。
下面这张图展示了overlong buffer的形状。它不是简单截断response,而是在reward层对过长答案施加连续负反馈。

这个设计的系统意义在于:长度管理不仅仅发生在tokenizer或rollout max length上。`data.max_response_length`决定生成上限,overlong buffer决定接近上限时的reward曲线,二者共同影响模型学到的“适宜长度”。
### 2. Dr. GRPO调整的是归一化和loss聚合
Dr. GRPO在当前`examples/grpo_trainer/README.md`中既不是新worker,也不是单独trainer。README给出的启用方法是在canonical GRPO上叠加三个配置:`actor_rollout_ref.actor.loss_agg_mode=seq-mean-token-sum-norm`、`actor_rollout_ref.actor.use_kl_loss=False`、`algorithm.norm_adv_by_std_in_grpo=False`(参考`examples/grpo_trainer/README.md:30-38`)。
这三个配置分别对应两段源码。第一段是GRPO advantage:`compute_grpo_outcome_advantage()`默认会将`score - group_mean`再除以组内std;当`norm_adv_by_std_in_grpo=False`时,它只做`score - group_mean`(参考`verl/trainer/ppo/core_algos.py:294-328`)。第二段是loss聚合:`agg_loss()`对`seq-mean-token-sum-norm`会先按序列求token-sum,再按global batch做seq-mean,最后除以固定scale factor或response horizon(参考`verl/trainer/ppo/core_algos.py:1141-1187`)。
下面这张图将两个关键开关放在一起。它补充说明:Dr. GRPO不改变actor/ref/reward/rollout的角色图,而是改变同一批token loss如何被缩放。
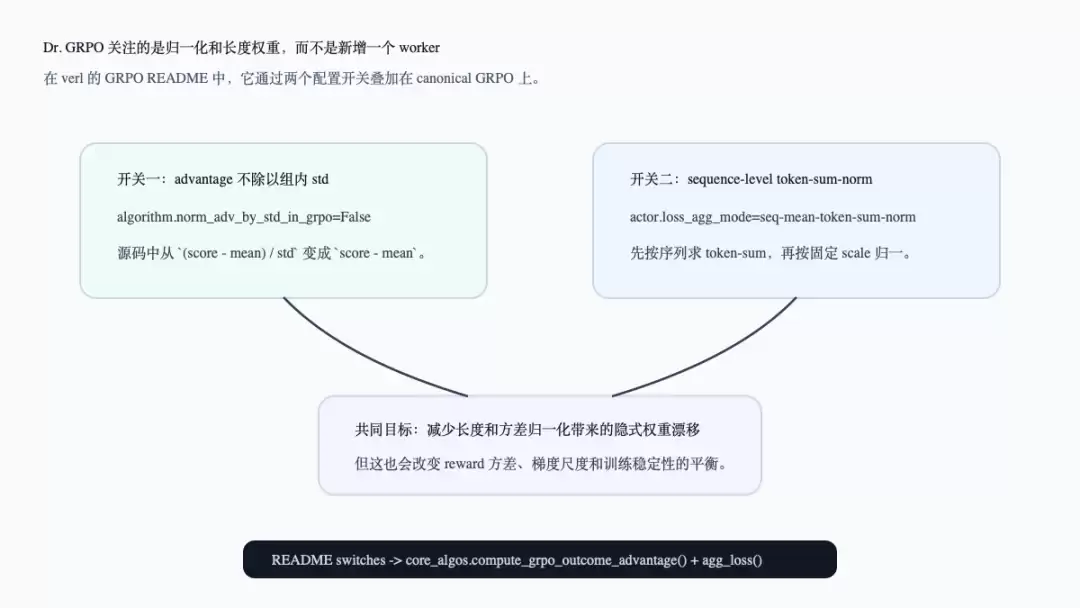
这里需要谨慎区分源码事实和工程解释。源码事实是:一个开关控制GRPO advantage是否除以组内std,另一个开关控制actor loss的token/sequence聚合方式。工程解释是:这两个开关都会改变长度、方差和梯度尺度之间的平衡,因此它们属于长度偏置和稳定性管理的一部分。
### 3. 长度偏置从三条路径进入训练
长度偏置不是一个单点bug,而是三条路径叠加产生的系统效应。
第一条是reward路径。DAPO overlong buffer明确将response长度纳入reward:超过expected_len后,reward会被额外扣分(参考`verl/workers/reward_manager/dapo.py:121-132`)。
第二条是advantage路径。GRPO的outcome score是标量,但`compute_grpo_outcome_advantage()`会把这个标量乘以`response_mask`广播到所有有效response token上(参考`verl/trainer/ppo/core_algos.py:329-331`)。同一个scalar advantage作用于多少token上,取决于response长度。
第三条是loss聚合路径。`agg_loss()`支持`token-mean`、`seq-mean-token-sum`、`seq-mean-token-sum-norm`、`seq-mean-token-mean`等模式;不同模式对长短response的权重不同(参考`verl/trainer/ppo/core_algos.py:1168-1197`)。actor默认配置也将`loss_agg_mode`作为一等配置项,并说明它支持这些模式(参考`verl/trainer/config/actor/actor.yaml:81-86`)。
下面这张图将三条路径整合在一起。它与前两张图互补:前面分别讲reward和Dr. GRPO开关,这张图说明为什么它们最终都落到长度偏置。
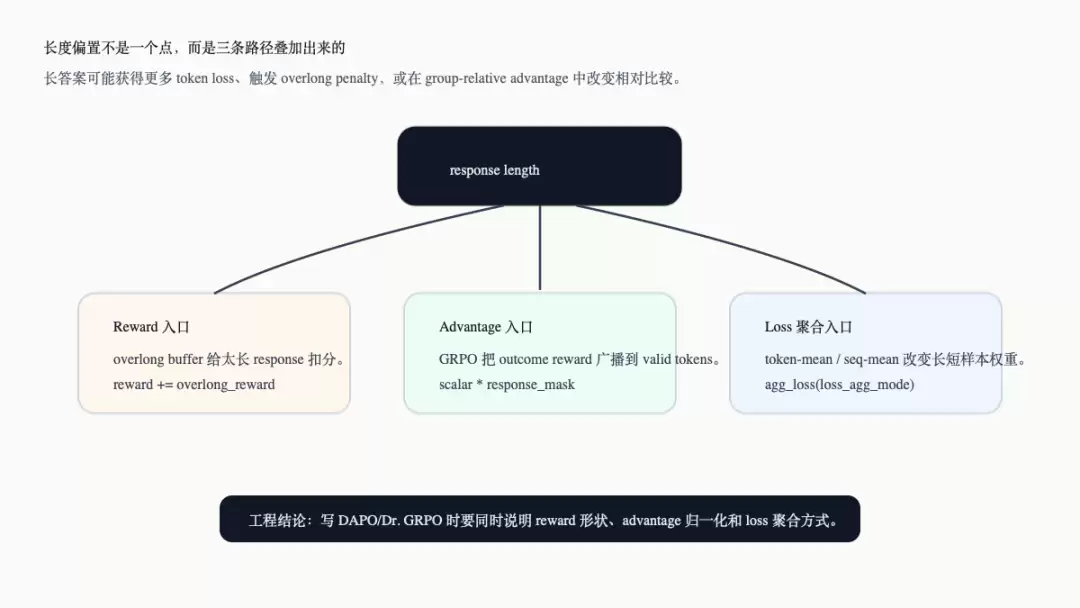
因此,写到DAPO/Dr. GRPO时,不能只说“用了GRPO”。更完整的描述应同时说明reward形状、advantage归一化、loss聚合方式和max response length。否则同样是`adv_estimator=grpo`,训练语义可能已经不同。
### 4. 动态batch和sequence balancing是性能侧的配套
长度问题还会影响性能。GRPO/DAPO场景常见长上下文和多response,短样本与长样本混在一起时,padding、micro-batch token数和DP rank负载都会变成系统问题。
示例脚本中,actor侧会启用`actor_rollout_ref.actor.use_dynamic_bsz=True`,并设置`ppo_max_token_len_per_gpu`;rollout/ref logprob也经常跟随dynamic batch配置(参考`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:134-147`,`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:148-172`)。actor配置文件也说明`ppo_max_token_len_per_gpu`通常需要与prompt/response长度相关(参考`verl/trainer/config/actor/actor.yaml:26-33`)。
trainer侧还有`balance_batch`:它会根据attention mask的有效token数计算workload,再对batch重排,使DP rank上的token数更接近;源码注释也提醒,这通常会改变样本顺序,但advantage依赖uid,因此不影响advantage计算(参考`verl/trainer/ppo/ray_trainer.py:1060-1128`,`verl/trainer/ppo/ray_trainer.py:1408-1415`)。
这些是性能侧配套,不是算法替代。它们解决的是“长短样本如何高效进worker”,而非“长度本身该被奖励还是惩罚”。后者仍由reward manager、advantage和loss聚合共同决定。
### 小结:DAPO/Dr. GRPO是对GRPO主线的长度与尺度管理
把第08、09篇连起来看,第二组的逻辑是:
```
PPO 需要 critic baseline
GRPO 用组内相对 reward 替代 critic baseline
DAPO / Dr. GRPO 继续管理 reward 长度、advantage 归一化和 loss 聚合尺度
```
DAPO-style recipe在verl中不是替换GRPO主线,而是在GRPO上调整reward和训练配置。Dr. GRPO也不是新增worker,而是通过`norm_adv_by_std_in_grpo`和`loss_agg_mode`改变advantage与token loss的尺度。
下一篇可以继续写KL、clip、entropy:当reward、advantage和长度都进入系统后,还需要一组限速器防止actor更新过快。
### 本文源码索引
`examples/grpo_trainer/run_qwen3_30b_a3b_megatron.sh:100-147`:DAPO-style recipe中GRPO estimator、DAPO reward、overlong buffer、actor clip与loss aggregation配置。
`examples/grpo_trainer/run_qwen3_8b_fsdp.sh:130-172`:常规GRPO示例中的data、actor、rollout/ref dynamic batch配置。
`examples/grpo_trainer/README.md:30-38`:Dr. GRPO的三个配置开关。
`verl/workers/reward_manager/dapo.py:25-56`:`DAPORewardManager`的注册与overlong buffer参数校验。
`verl/workers/reward_manager/dapo.py:71-132`:DAPO reward计算、overlong penalty和reward写入位置。
`verl/trainer/ppo/core_algos.py:294-328`:GRPO advantage是否按组内std归一。
`verl/trainer/ppo/core_algos.py:329-331`:GRPO scalar advantage如何广播到response tokens。
`verl/trainer/ppo/core_algos.py:1141-1199`:`agg_loss()`的token/sequence聚合模式。
`verl/trainer/config/actor/actor.yaml:26-33`:dynamic batch与token长度上限配置。
`verl/trainer/config/actor/actor.yaml:81-86`:actor loss aggregation配置。
`verl/trainer/ppo/ray_trainer.py:1060-1128`:按有效token数做batch balance。
`verl/trainer/ppo/ray_trainer.py:1408-1415`:`fit()`中response mask与balance_batch的位置。




