上一组最后一篇按 fit() 走完了一轮 PPO/GRPO step。进入第二组,我们换一个视角:在同一轮 step 中,actor、rollout、reference policy、reward、critic 这些角色各司其职,哪些真正在训练,哪些仅提供反馈信号,哪些只用于生成过程?
首先给出一个核心判断:在 LLM 后训练阶段,PPO 真正优化的是 actor 策略模型。如果启用 critic,它会作为辅助的 value baseline 参与训练;而 reference policy 和 reward 并非在这一轮 PPO 中被更新的主策略,它们分别提供偏离基准和偏好信号。如果将这些角色混淆成“多个模型一起训练”,会直接误解 PPO 的工程边界。
下面这张图先呈现角色地图。看图时请重点关注箭头方向:谁产出样本,谁产出分数,谁产出基线,谁被反向更新。
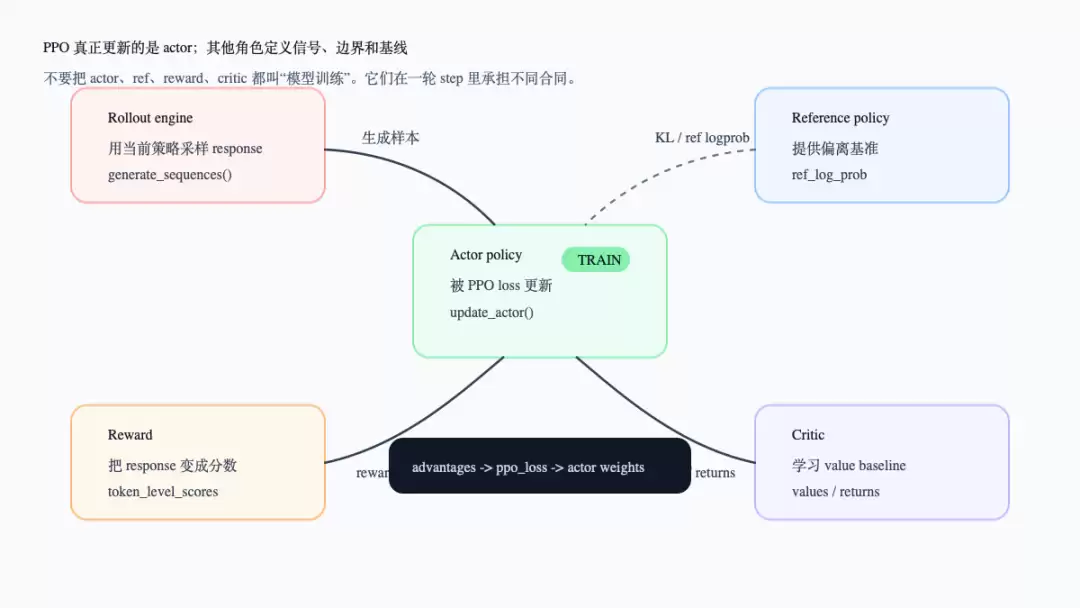
PPO 后训练中的四个角色
这张图特意画出了 rollout engine,因为许多误解源于这里:rollout 负责用策略生成 response,但它不是 loss 中的训练对象。训练后的 actor 权重还需要同步回 rollout 侧,下一轮生成时新策略才会生效。
1. 四个角色的职责分工
actor 是主策略。RayPPOTrainer._update_actor() 会把已经补齐字段的 batch 转换成 TensorDict,写入 mini-batch size、PPO epochs、shuffle、compute_loss=True 等训练控制信息,然后调用 actor_rollout_wg.update_actor()(verl/trainer/ppo/ray_trainer.py:1205-1245)。在 worker 侧,update_actor() 会进一步调用 actor 的 train_mini_batch()(verl/workers/engine_workers.py:646-651)。
critic 是辅助的价值模型。只有当 self.use_critic 为真时,trainer 才会创建 critic worker、设置 value_loss,并在 step 中计算 values、更新 critic(verl/trainer/ppo/ray_trainer.py:714-738,verl/trainer/ppo/ray_trainer.py:785-794,verl/trainer/ppo/ray_trainer.py:1130-1142,verl/trainer/ppo/ray_trainer.py:1247-1272)。它训练的是 value baseline,而不是部署时用于回答用户的策略。
reference policy 是偏离基准。trainer 会通过 need_reference_policy(config) 判断是否需要 ref,并在需要时计算 ref_log_prob(verl/trainer/ppo/ray_trainer.py:290-295,verl/trainer/ppo/ray_trainer.py:1144-1166)。如果 LoRA 场景下 ref_in_actor 为真,reference policy 可能通过 actor worker 中不加载 LoRA adapter 的路径计算,而不是独立 worker(verl/trainer/ppo/ray_trainer.py:303-307,verl/trainer/ppo/ray_trainer.py:1151-1157)。不过这不改变它的职责:提供基准 logprob。
reward 是偏好信号的来源。_compute_reward_colocate() 只是调用 reward_loop_manager.compute_rm_score(batch)(verl/trainer/ppo/ray_trainer.py:504-510)。它可以是 reward model、规则函数或环境反馈的统一入口;在这篇讨论的 PPO 主循环中,它的输出是 rm_scores、token_level_scores 或额外 reward 信息,并不直接参与 actor 参数更新。
2. Actor loss 的输入合同是什么样的
actor 真正被训练的过程发生在 worker 侧的 ppo_loss() 和 policy loss 函数中。ppo_loss() 先从 model output 中获取当前 actor 的 log_probs,再从 data 中选择 response_mask、old_log_probs、advantages,如果存在还会选择 rollout_is_weights 和 ref_log_prob(verl/workers/utils/losses.py:57-91)。这说明 actor loss 的输入并非一个 reward 标量,而是一组已经在 fit() 中准备好的证据。
下面这张图把 actor loss 的合约展开。它补充了上一篇时间线中没有展开的内部接口:old_log_probs 是更新前的锚点,当前 log_prob 来自 actor forward,advantages 决定了强化方向,response_mask 确保仅训练 response tokens。
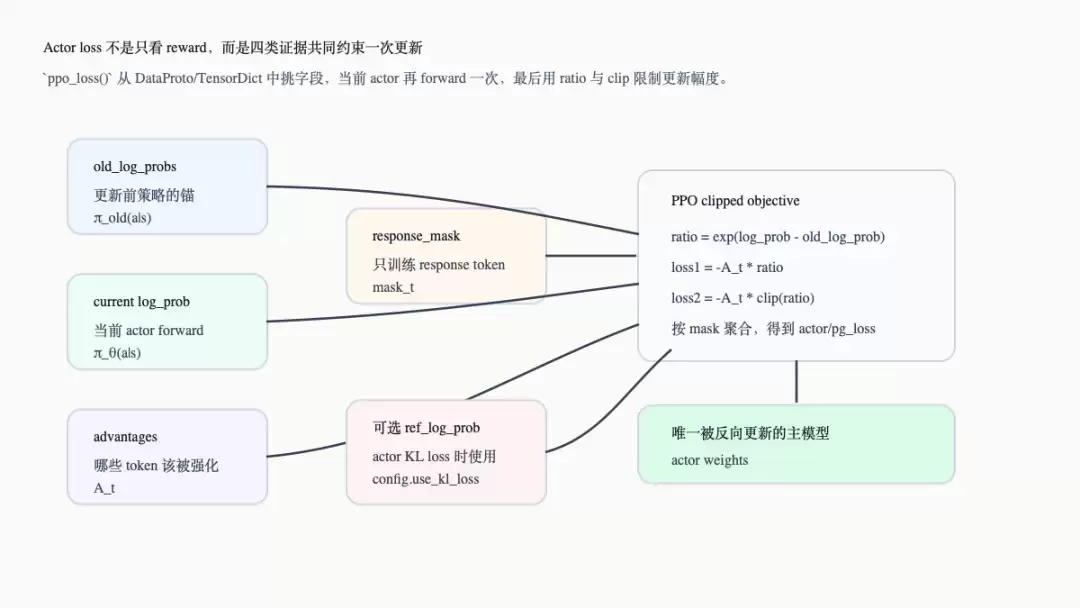
Actor policy loss 的输入合同
源码中默认的 vanilla policy loss 会计算 ratio = exp(log_prob - old_log_prob),再取 unclipped loss 和 clipped loss 中更保守的一项,最后按 response_mask 聚合成 pg_loss(verl/trainer/ppo/core_algos.py:1279-1370)。因此,PPO 的“稳定更新”在工程上体现为两个事实:必须重新计算或保留 old logprob,并且必须只在 response token 上聚合。
如果 actor 配置开启了 use_kl_loss,ppo_loss() 还会读取 ref_log_prob,计算 KL penalty,并把 kl_loss * kl_loss_coef 加入 policy loss(verl/workers/utils/losses.py:131-144)。这条路径会直接改变 actor 的反向传播目标。
3. Critic 训练的是 baseline,而不是另一个策略
critic 的训练合约更加狭窄。value_loss() 从 model output 中获取当前预测的 values,从 data 中选择旧的 values、returns 和 response_mask,然后调用 compute_value_loss() 得到 value loss 及相关指标(verl/workers/utils/losses.py:147-186)。也就是说,critic 不是在学习“怎样回答”,而是在学习 actor 已采样轨迹上的 value baseline。
PPO/GAE 为什么需要这个 baseline?compute_advantage() 的 GAE 分支会将 token_level_rewards、values、response_mask 传入 compute_gae_advantage_return(),后者反向递推 advantage,并把 returns = advantages + values 作为 critic 训练目标(verl/trainer/ppo/ray_trainer.py:166-182,verl/trainer/ppo/core_algos.py:216-263)。actor 使用 advantage,critic 使用 returns,两者在同一批 DataProto 上分工协作。
GRPO 的对比能更清楚地说明 critic 的角色。下面这张图将两种 baseline 放在一起对比:PPO/GAE 是可学习的 value baseline,GRPO 则是同一 prompt 多条 response 的组内相对 baseline。
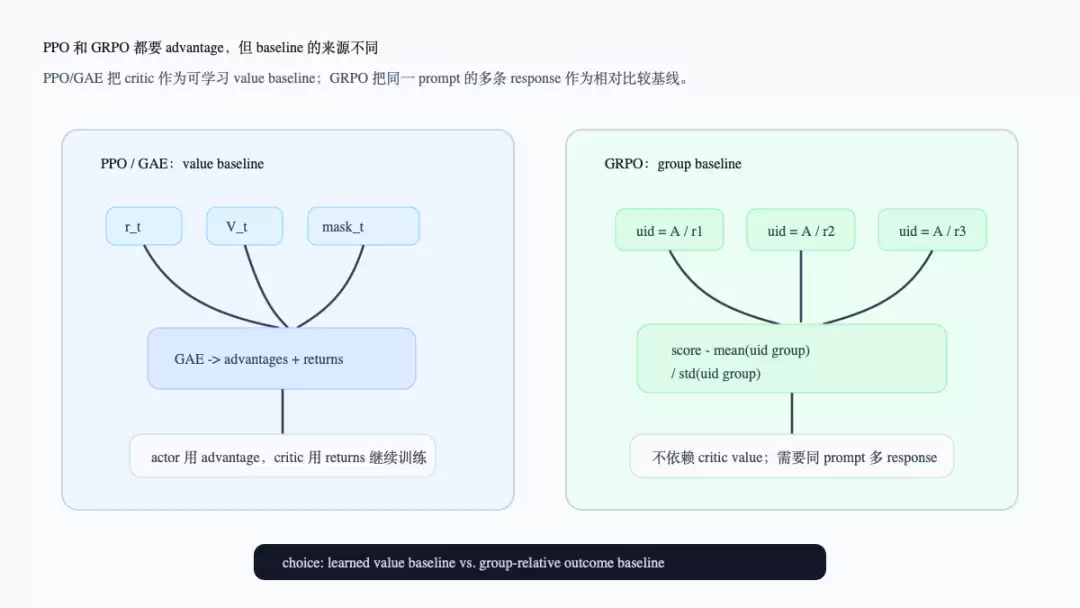
Critic baseline 与 GRPO group baseline 的选择
在 GRPO 分支中,compute_advantage() 调用 compute_grpo_outcome_advantage() 时传入的是 token_level_rewards、response_mask 和 uid,不传 values(verl/trainer/ppo/ray_trainer.py:183-195)。compute_grpo_outcome_advantage() 会将每条 response 的 reward 求和,再按 uid 计算组内均值和标准差,最后把相对分数广播到 response mask 上(verl/trainer/ppo/core_algos.py:268-331)。这也是下一篇《GRPO 为什么能省掉 critic》的入口。
4. Reference policy 有两个 KL 位置
reference policy 的职责容易被误解,因为它可能出现在两个位置。
第一个位置是 in-reward KL。fit() 在计算 advantage 之前会检查 algorithm.use_kl_in_reward;如果开启,会调用 apply_kl_penalty(),用 old_log_probs 和 ref_log_prob 计算 KL,并从 token_level_scores 中扣掉 beta * KL,得到 token_level_rewards(verl/trainer/ppo/ray_trainer.py:1496-1512,verl/trainer/ppo/ray_trainer.py:75-114)。此时 KL 改写的是 advantage 看到的 reward。
第二个位置是 actor KL loss。如前所述,ppo_loss() 在 config.use_kl_loss 为真时,会把 KL loss 直接加入 actor policy loss(verl/workers/utils/losses.py:131-144)。此时 reward 不一定被改写,KL 作为 actor 更新目标的一部分出现。
下面这张图把两个位置分开。它和上一张 actor loss 图互补:上一张解释 loss 合约,这张解释 ref policy 的信号究竟在哪一层进入训练。
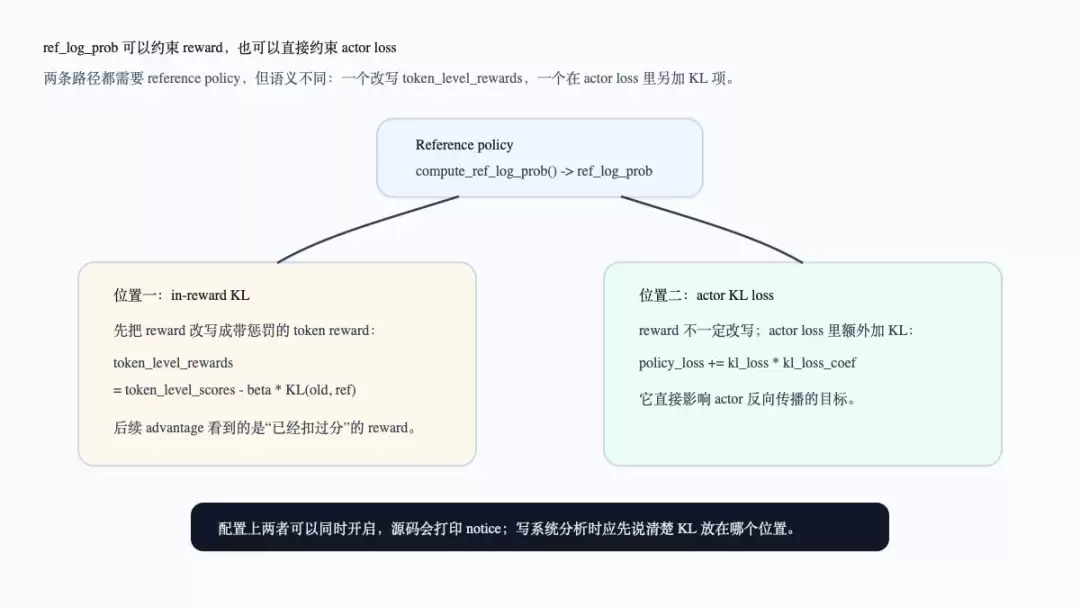
Reference policy 的两个 KL 位置
配置校验里也能看到这两个位置的关系:如果同时开启 in-reward KL 和 actor KL loss,validate_config() 会打印 notice(verl/utils/config.py:169-170)。这并非说明一定错误,而是提醒读代码和写系统分析时必须先讲清楚:KL 是放进 reward,还是放进 actor loss,还是两者都开。
小结:PPO 训练的是策略,其他角色定义训练问题
这一篇可以压缩成一句话:
reward 定义偏好信号,reference 定义偏离边界,critic 定义 baseline,actor 才是被 PPO policy loss 更新的主策略。这句话也打开了第二组的路线。下一篇写 GRPO 时,重点不再是重复 actor/ref/reward/critic 的角色,而是解释为什么把 baseline 从 critic value 换成 group-relative reward 后,系统可以省掉 critic 路径,同时会引入 rollout.n、同 prompt 多样本、reward 方差和长度偏置等新问题。
本文源码索引
verl/trainer/ppo/ray_trainer.py:290-312:trainer 如何判断 reference policy、critic、in-reward KL 是否启用。verl/trainer/ppo/ray_trainer.py:714-807:init_workers()如何创建 actor、critic、ref worker。verl/trainer/ppo/ray_trainer.py:504-510:reward loop 如何提供 reward 分数。verl/trainer/ppo/ray_trainer.py:1130-1166:critic value 和 reference logprob 的计算路径。verl/trainer/ppo/ray_trainer.py:1205-1272:actor update 与 critic update 的 trainer 入口。verl/trainer/ppo/ray_trainer.py:1496-1512:advantage 前 token-level reward 与 in-reward KL 的位置。verl/workers/utils/losses.py:57-144:ppo_loss()的输入字段、policy loss 和 actor KL loss。verl/workers/utils/losses.py:147-186:value_loss()如何训练 critic baseline。verl/trainer/ppo/core_algos.py:216-331:GAE 与 GRPO 两种 advantage/baseline 路径。verl/trainer/ppo/core_algos.py:1279-1370:vanilla PPO clipped objective 的实现。verl/workers/engine_workers.py:646-651:actor worker 如何进入train_mini_batch()。verl/utils/config.py:169-170:同时开启 in-reward KL 与 actor KL loss 的配置提示。




