上一篇我们详细拆解了 single controller 的核心机制:PPO 主循环整体部署在一个 controller 进程内,每次 WorkerGroup 调用会被分解为 dispatch、Ray remote execution 和 collect 三个步骤。今天进一步探讨一个更具实践意义的问题——那些远程 worker 究竟运行在哪些 GPU 上?为什么 actor、rollout、critic、reward、teacher 无法简单地归为“一组 GPU 任务”?
一句话概括核心结论:verl 并非按照函数或进程来分配 GPU,而是先将系统中的职责抽象为 Role,再将 Role 映射到 ResourcePool,最后通过 WorkerGroup 或对应的 manager 将这些资源转化为可远程调用的执行单元。只有理解这一层,你才能真正说清“GPU 不足”究竟是哪一环的瓶颈——是 actor 的权重更新过慢,rollout 的长尾延迟过长,reward 的计算负担加重,还是 controller 与 collect 之间的边界发生了阻塞。
沿着这条链路往下阅读,所有内容就串联起来了:
Role → worker class / resource pool name → ResourcePoolManager → RayResourcePool → placement group / bundle → RayWorkerGroup / reward loop / teacher manager下面这张图先展示角色、资源池与 WorkerGroup 的整体关系。重点不在于记住每个名称,而在于看清边界所在:Role 是系统职责,ResourcePool 是资源的归属标签,WorkerGroup 则是 controller 能够调用的那个“远程容器”。
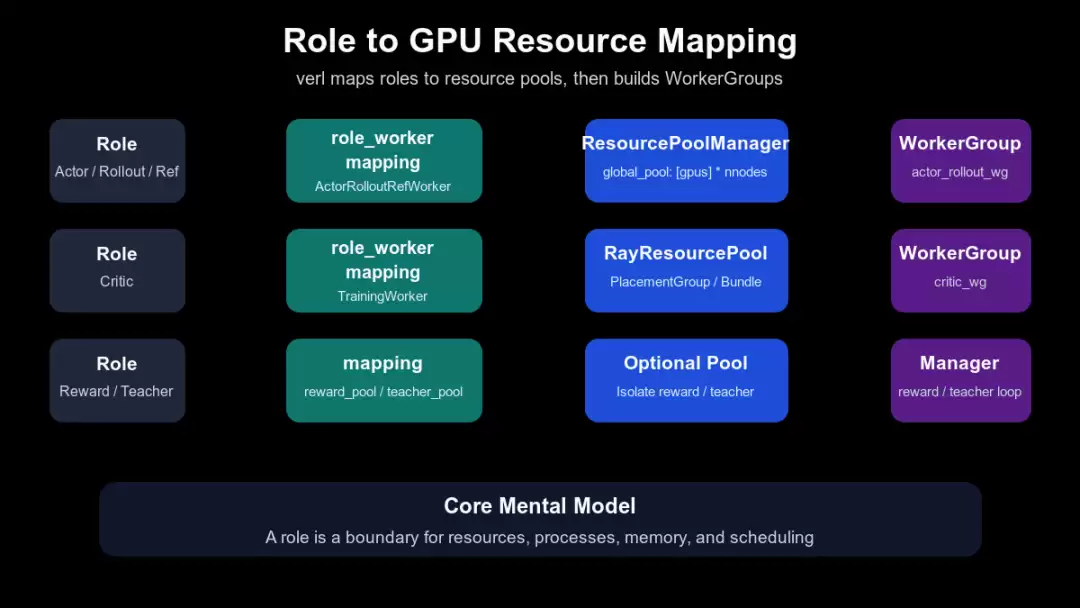
角色如何映射到 GPU 资源
这张图对应 TaskRunner 中的两张关键映射表:role_worker_mapping 决定某个 Role 使用哪个 worker class,mapping 则决定某个 Role 去往哪个 resource pool(对应源码 verl/trainer/main_ppo.py:107-120)。后续整个资源生命周期都源于这两张表。
1. 资源先被“角色化”,而不是先被函数占用
打开 main_ppo.py 可以看到:actor、rollout、ref 等角色被统一映射到 ActorRolloutRefWorker,critic 映射到 TrainingWorker,默认都放入 "global_pool"(verl/trainer/main_ppo.py:122-152)。reward model 和 teacher model 不一定注册为普通的 WorkerGroup,但也会在 mapping 中登记——reward 可以置于 global_pool 或独立的 reward_pool,teacher 则放入 teacher_pool(verl/trainer/main_ppo.py:189-208)。
换句话说,verl 的入口并非“创建几个 GPU 进程”,而是“这些进程究竟承担什么角色”。这个先后顺序至关重要:actor 的压力主要来自训练显存、优化器状态与权重同步;rollout 的压力集中在 KV cache、decode 吞吐和长尾延迟上;reward 可能是简单的 CPU 规则,也可能是大模型甚至环境模拟器;teacher 则是蒸馏场景中的额外推理负载。如果只关注“占了多少 GPU”,这些本质差异便会被完全掩盖。
角色注册完成后,TaskRunner.run() 才创建 ResourcePoolManager,然后将 role_worker_mapping、resource_pool_manager 与 ray_worker_group_cls 一同传给 RayPPOTrainer(verl/trainer/main_ppo.py:219-311)。这意味着 PPO trainer 拿到的并非散落的 Ray actor,而是一套已按角色规划好的资源方案。
2. ResourcePool 把配置变成 Ray 可调度的物理位置
角色映射敲定之后,ResourcePoolManager.create_resource_pool() 会遍历 resource_pool_spec,为每个 pool name 创建 RayResourcePool,同时检查 Ray 集群中可用的 GPU 是否满足总需求(verl/single_controller/ray/base.py:181-240)。像 global_pool = [8, 8] 这样的配置并非抽象数字——它表示该 pool 横跨两个节点,每个节点需要 8 个可调度位置。
再往下,RayResourcePool.get_placement_groups() 将 pool 转换为 Ray 的 placement group。每个 bundle 包含 CPU 配额,若启用 GPU 还会携带一个 GPU/NPU 资源;placement group 创建完成后会等待 ready,并按节点 IP 排序(verl/single_controller/ray/base.py:112-160)。这一层把“逻辑资源池”变成了 Ray 可稳定调度的物理占位。
下面这张生命周期图补充了从 resource pool spec 到 worker 的中间层。请留意其中的 env vars 步骤:worker 不仅被创建出来,还会获得 WORLD_SIZE、RANK、MASTER_ADDR、MASTER_PORT 这些分布式训练必需的身份信息。
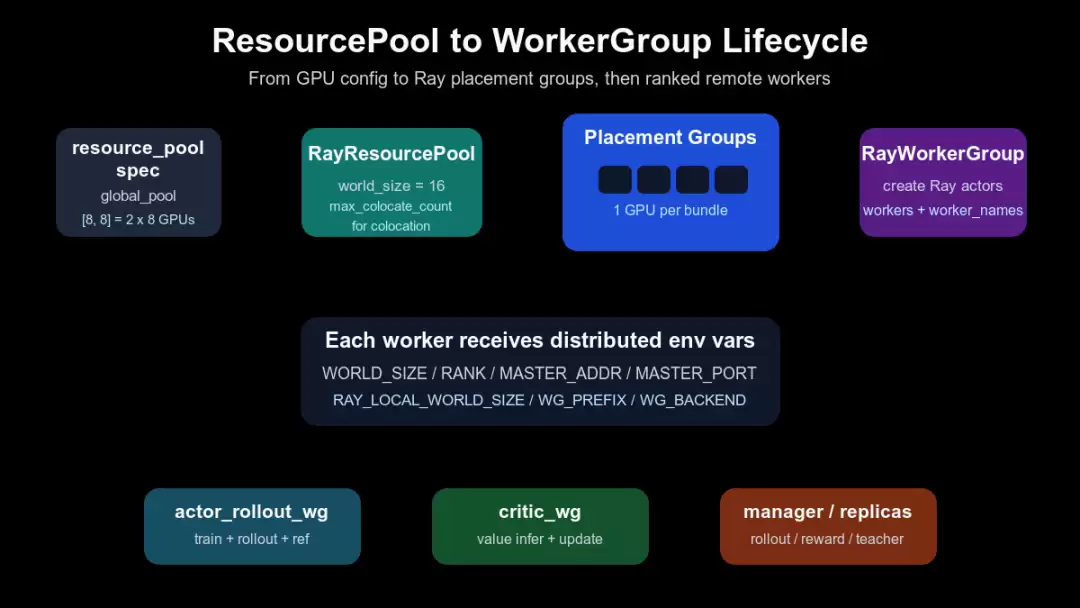
ResourcePool 到 WorkerGroup 的生命周期
RayWorkerGroup._init_with_resource_pool() 从 resource pool 中取出 placement groups,按 node 和 local rank 创建 worker;_create_worker() 向每个 Ray actor 注入 WORLD_SIZE、RANK、WG_PREFIX、RAY_LOCAL_WORLD_SIZE、MASTER_ADDR、MASTER_PORT 等环境变量,再将 actor handle 记录到 WorkerGroup 中(verl/single_controller/ray/base.py:536-681)。所以 WorkerGroup 不仅仅是一个名称列表,它携带了完整的 rank 拓扑和远程 actor 句柄,是直接的执行边界。
3. colocate 和拆分是资源取舍,不是风格偏好
来看 RayPPOTrainer.init_workers():它先创建 resource pool,然后将 actor/critic/ref 等角色包装成 RayClassWithInitArgs,按 resource pool 聚合到 resource_pool_to_cls,最后对每个 pool 分别调用 create_colocated_worker_cls() 和 RayWorkerGroup 来生成可调用的 WorkerGroup(verl/trainer/ppo/ray_trainer.py:688-783)。
这段代码旁边有一句很直白的设计提示:如果你想为不同角色分配不同的 resource pool、支持不同的并行规模,那就不要使用 colocated worker class,而是直接将不同的 pool 传给不同的 WorkerGroup(verl/trainer/ppo/ray_trainer.py:750-755)。因此 colocate 和拆分本质上是资源拓扑选择,与代码风格毫无关系。
下面这张图清晰地展示了这种取舍。左半部分强调共置的好处:actor、rollout、critic/ref 挤在同一个 global pool 里,资源拓扑简单,训练与 rollout 之间的权重同步路径也短;右半部分强调隔离的优势:当 reward 或 teacher 变重时,可以避免它们挤占主训练链路。
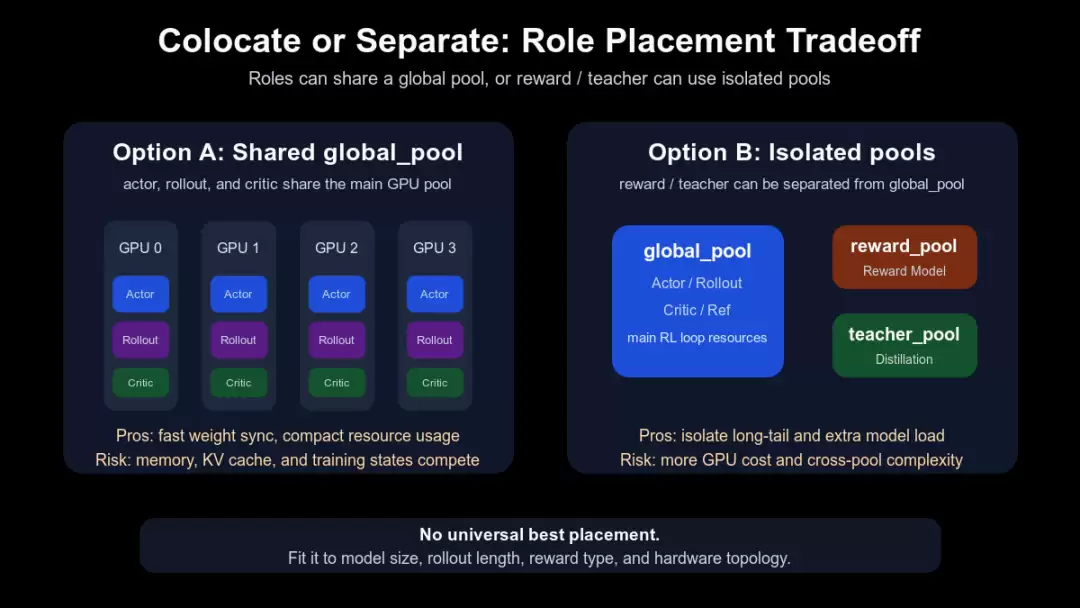
共置还是拆分
文档也进一步说明:ActorRolloutRefWorker 可以同时承担 actor、rollout 和 reference policy 的角色。actor 和 rollout 共置的一个关键原因是为了方便通过 NCCL 进行快速的权重传递;actor 和 reference 共置则能让 LoRA PPO 更高效(docs/hybrid_flow.rst:118-120)。但这绝不意味着“永远共置”。RewardLoopManager 会根据 reward model 是否使用额外 resource pool 来接收不同的资源,teacher policy 也会通过 MultiTeacherModelManager 使用 teacher_pool(verl/trainer/ppo/ray_trainer.py:812-868)。
4. 看瓶颈时要按角色来,而不是按模块名来
ResourcePool 和 WorkerGroup 的真正价值,不只是让代码跑起来。它们为我们提供了一套定位瓶颈的坐标系。
如果 actor 慢,通常需要检查训练显存、forward/backward 耗时、optimizer state 大小、micro-batch 设置和通信效率;如果 rollout 慢,要关注 KV cache 占用、response 长度、采样长尾和推理引擎的吞吐;如果 critic/ref 慢,要看额外的 forward 是否拉长了 step 时间;如果 reward 慢,要弄清它是规则函数、模型推理、环境调用还是工具链;如果 controller 慢,那多半是 DataProto 的分发、序列化、collect 聚合和调度等待出了问题。
下面这张图将这些压力点放回到各个角色身上。它并非要穷举所有性能问题,而是提醒读者:同样都是 GPU 利用率低,背后等待的原因可能完全不同。
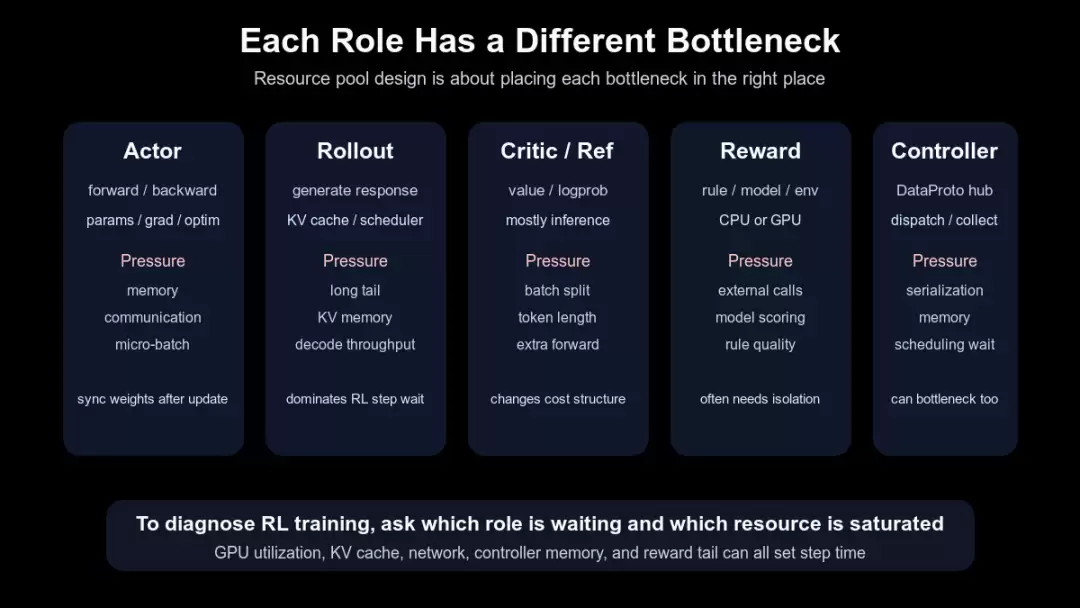
不同角色的瓶颈地图
这也解释了为什么这篇文章必须放在 DataProto 之前讲——只有先搞清楚哪些角色在消耗 GPU 资源,下一篇讨论“这些角色之间流动的数据”时才不会跑偏。否则 DataProto 不过是一个容器;一旦放到 ResourcePool/WorkerGroup 的上下文里,它就会变成 controller、worker、reward、rollout 之间的数据协议和潜在的瓶颈环节。
小结:GPU 资源在 verl 里先变成角色,再变成 worker
verl 的资源组织可以压缩成一句话:
先定义系统角色,再把角色映射到资源池,最后把资源池实例化成可调用的 WorkerGroup 或 manager。这套分层让 PPO 主循环无需操心每个角色具体放在哪张卡上,但它并未消除资源取舍。共置可以缩短权重同步和共享路径,拆分可以隔离 reward/teacher 这类长尾或额外负载——但具体选择哪个,需要回归到模型大小、rollout 长度、reward 形态和硬件拓扑等实际因素上去判断。
下一篇进入 DataProto:当 actor、rollout、critic、reward、teacher 都被角色化以后,它们之间传来传去的那批数据到底是什么?为什么它会不断变胖?又为什么它会成为 controller 边界上的系统成本?
本文源码索引
verl/trainer/main_ppo.py:107-120:TaskRunner中 role 到 worker class、resource pool 的两张映射表。verl/trainer/main_ppo.py:122-152:actor/rollout/ref 与 critic 的 worker class 和默认 pool 映射。verl/trainer/main_ppo.py:154-187:global_pool、reward_pool、teacher_pool的 resource pool spec。verl/trainer/main_ppo.py:189-208:reward model 和 teacher model 的资源池登记。verl/trainer/ppo/ray_trainer.py:688-783:init_workers()如何创建 role class、colocated worker class 和 WorkerGroup。verl/trainer/ppo/ray_trainer.py:812-868:reward loop、LLM server manager、teacher manager 如何接入资源池。verl/single_controller/ray/base.py:112-160:RayResourcePool如何创建 Ray placement group。verl/single_controller/ray/base.py:181-240:ResourcePoolManager如何创建资源池并检查资源。verl/single_controller/ray/base.py:536-681:RayWorkerGroup如何按 rank/local rank 创建 worker 并注入分布式环境变量。




