
ICWM 是如何设计的?
与传统 VLA 模型相比,ICWM 的核心变革在于:它先根据交互上下文推断当前系统配置,然后才生成后续动作。整个流程分为训练和推理两个阶段。 **训练阶段**:团队在每个任务样本之前拼接一段与任务无关的交互片段,作为上下文输入。模型通过观察交互带来的画面变化,推断当前系统的配置。值得关注的是,ICWM 并未单独构建一个独立的世界模型,而是直接利用 VLA 主干网络处理这段交互历史。这种设计既简化了整体架构,又能使信息直接服务于动作预测。 **推理阶段**:机器人并不立即执行任务,而是先进行一轮主动探测——记录动作前后的观测变化,形成所谓的“交互上下文”。随后,模型将当前的上下文、画面以及任务指令一并作为输入,判断下一步应如何行动。 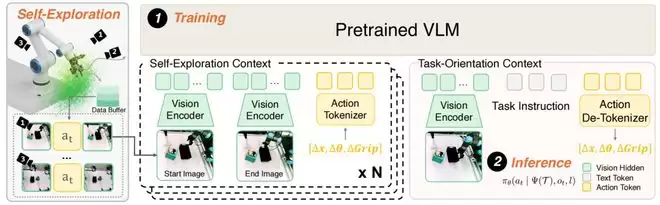
图|ICWM 的训练与推理流程概览。
实验结果
团队在跨视角、真实机器人以及多种分布外扰动场景下均进行了实验。结果表明,ICWM 借助交互上下文大幅增强了对新环境的适应能力,并且展现出向语义变化和机器人形态变化等场景扩展的潜力。1. 仿真结果
在 LIBERO 仿真基准的跨视角实验中,ICWM 在已见视角和新视角下均优于基线方法。相比单纯依赖多视角训练的方法,它在已见视角下平均高出 8.1%,在新视角下平均高出 13.0%。即使直接将真实相机参数输入模型,其泛化表现依然不及 ICWM。在长时序任务中,ICWM 对累积误差的控制也更为出色。 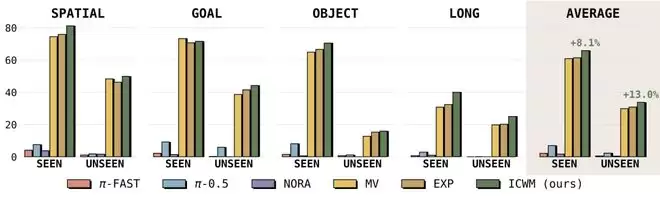
图|在 LIBERO 基准上,已见视角与未见视角的成功率(%)。
2. 真实机器人实验
在 UR5e 真实机器人平台上,ICWM 同样明显优于基线方法。团队采用了一套 12 相机的多视角系统进行评估,任务涵盖堆叠、抓取、拾取、放置等操作。标准 VLA 对视角变化极为敏感——从训练视角切换到测试视角后,平均成功率从 68% 骤降至 17%,而 ICWM 的表现则稳定得多。 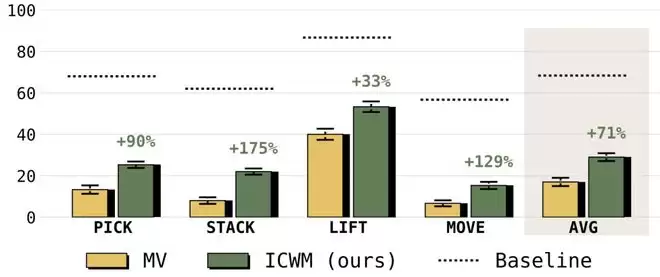
图|在 UR5e 平台上的真实世界评测。
定性结果同样引人注目:切换到新环境后,普通模型容易出现位置偏移、夹爪过早闭合等问题,而 ICWM 则基本保持稳定。 
图|定性对比。
3. 消融与分析
消融实验证实,ICWM 的性能提升确实源于交互上下文,而非简单的模式匹配。去除图像信息后,模型表现下降最为严重——平均成功率从 25.0% 降至 10.9%;去除动作信息或不提供交互上下文,模型表现也会下降。更有趣的是,如果输入一段错误的上下文,模型表现甚至比没有上下文时更差。对照实验还表明,模型必须经过专门训练才能利用交互上下文适应环境;否则,即便在测试时提供相同信息,性能也几乎为零。 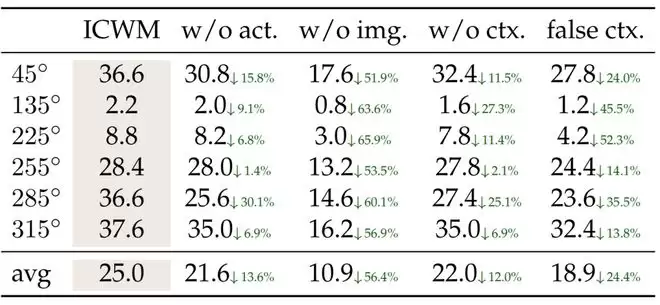
图|交互上下文消融实验。
从可视化结果来看,模型已经能够区分不同视角和配置:相同视角下的数据分布更加集中,不同视角之间的区分也更清晰。 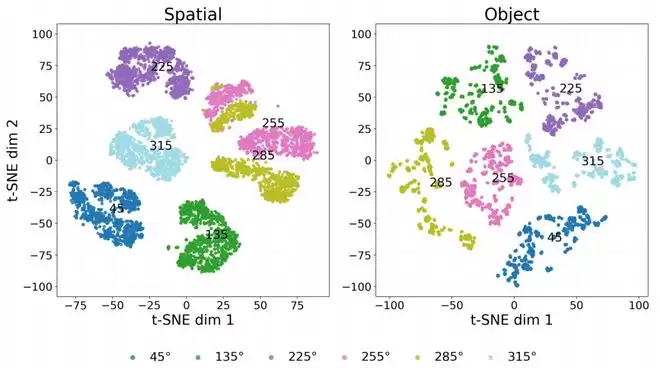
图|不同分布外(OOD)视角下的 Ψ(T) 的 t-SNE 可视化。
团队还发现,ICWM 的效果并不依赖于某一种特定的探测方式。无论是采用随机探测,还是仅沿 XY、Z 或旋转方向运动,ICWM 均稳定优于对照方法,成功率提升约 15% 到 27%。泛化实验也显示,ICWM 对机器人形态变化具有较强的适应性,在语义扰动场景下同样有一定提升。 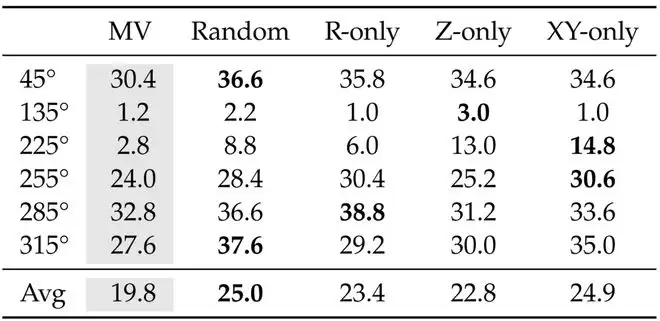
图|分布外(OOD)视角下,不同探测策略的成功率(%)。
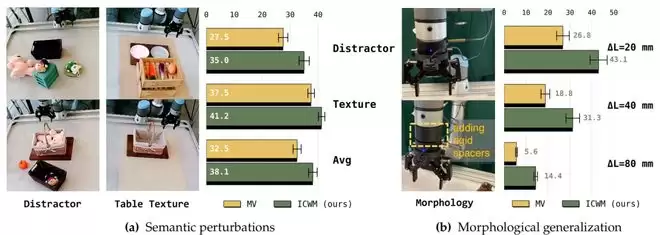
图|对语义场景变化和机器人形态变化的鲁棒性。




