智源See3D模型开源 1600万视频解锁空间智能
时间:2026-07-01 14:45
我们刚刚见识了李飞飞团队的成果,它被视为通向“空间智能”的第一步。而See3D则展现了截然不同的技术路径——它彻底跳出了传统方法对昂贵相机参数和三维标注的依赖。 传统的三维生成模型大多需要明确的相机位置信息(即pose-condition)来告知模型“应从哪个视角观察”。但See3D另辟蹊径,采用了
我们刚刚见识了李飞飞团队的成果,它被视为通向“空间智能”的第一步。而See3D则展现了截然不同的技术路径——它彻底跳出了传统方法对昂贵相机参数和三维标注的依赖。
传统的三维生成模型大多需要明确的相机位置信息(即pose-condition)来告知模型“应从哪个视角观察”。但See3D另辟蹊径,采用了一种“视觉条件”(visual-condition)技术。简单来说,它仅依赖视频本身提供的视觉线索,就能推断出相机应朝哪个方向移动,并生成几何一致的多视角图像。这就好比:你无需提供相机参数,只需给它观看几段物体持续旋转的视频,模型自己就学会了“旋转”这一三维概念。
这一策略的关键在于,它彻底绕开了昂贵的三维数据采集与标注。传统数据集如DLV3D、RealEstate10K,规模最多只有几十万到百万级,积累过程耗时费力。而互联网视频源源不断,这使得See3D具备了强大的数据可扩展性。
此外,See3D的学习成果非常全面。它不仅能够实现零样本的开放世界三维生成,还能无需额外微调,直接执行三维编辑、表面重建等任务,通用性相当出色。

**效果一览**
* **解锁三维交互世界**:输入一张图片,即可生成一个能实时探索的三维场景。当然,为了在浏览器中实现流畅交互,模型与渲染过程做了简化;若采用离线渲染,真实效果会更佳。
* **基于稀疏图片的三维重建**:只需提供3到6张图片,模型就能精细重建出整个场景。这相当于给你几张不同角度的房间照片,模型就能帮你填充出完整的室内空间。
* **开放世界三维生成**:输入“一个未来的赛博朋克城市”这类文本提示,模型先生成一张艺术化图片,再基于该图片进一步生成完整的三维场景。
* **基于单视图的三维生成**:这是最直接的应用场景。输入一张照片,模型就能“脑补”出该场景在其他视角下的样貌,并生成完整的三维结构。
**研究初衷:为何非得“看视频”?**
问题很现实:高质量的三维数据太昂贵了。
现有的三维数据集,无论是艺术家手工制作、立体匹配算法生成,还是通过运动恢复结构(SfM)重建,都耗时耗力且难以大规模扩展。目前最大的公开数据集,规模也仅有80万个对象,对于训练一个泛化的三维模型来说,杯水车薪。
但换个角度思考:人类如何理解三维世界?我们不需要任何三维标注,只需用眼睛从不同角度观察物体或场景,大脑就能构建出三维模型。视频正是这种连续多视角信息的天然载体——来源广泛、取之不尽,且天然具备相机运动与视角关联性。See3D的出发点,就是让模型“像人一样”去观看视频,从海量的“看”中学习并推理三维结构,而不是直接去建模一个复杂的几何网格。
**技术路径:如何实现?**
为了实现可扩展的三维生成,See3D搭建了一套系统化的方案:
**1. 数据集:从海量视频中“淘金”**
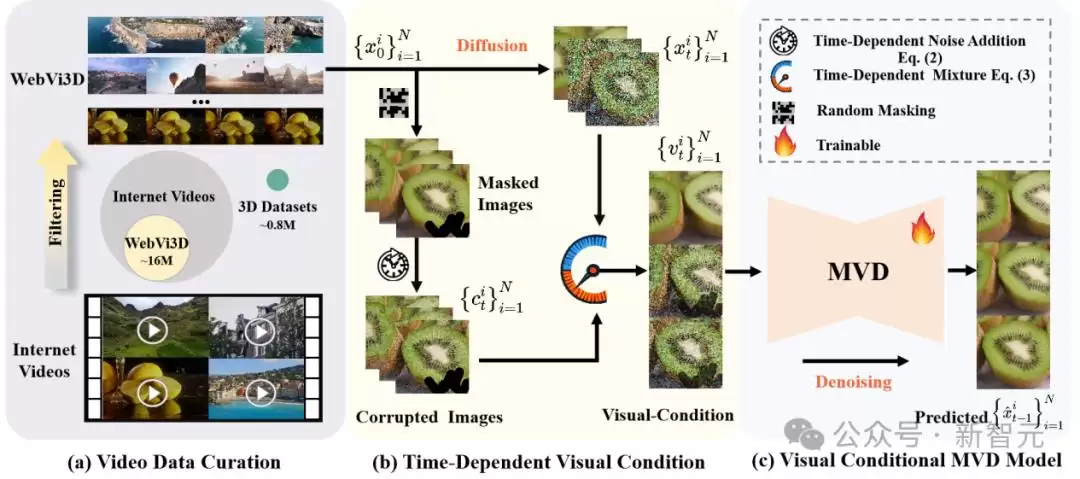
团队设计了一套自动化的视频筛选流程,从海量互联网视频中剔除视角单一或运动不一致的片段,最终构建了一个名为WebVi3D的高质量、多样化多视角图像数据集。该数据集包含来自1600万个视频片段的3.2亿帧图像,且这套流程可自动运行。随着互联网视频的增长,数据集也能同步扩充,彻底解决了过去数据“不够吃”的问题。
**2. 模型:视觉条件,抛弃相机标注**
这是最核心的技术难点。为每段视频标出精确的相机参数,成本极高且不现实。See3D的聪明之处在于,它提出了一种新的“视觉条件”。通过对掩码视频数据添加与时间相关的噪声,生成一种纯粹的二维视觉信号。这个信号充当了“老师”,指导模型学习多视角之间的对应关系。这样一来,模型可以不依赖相机条件,仅通过这个精心设计的视觉信号,就能训练出一个可扩展的多视角扩散模型。
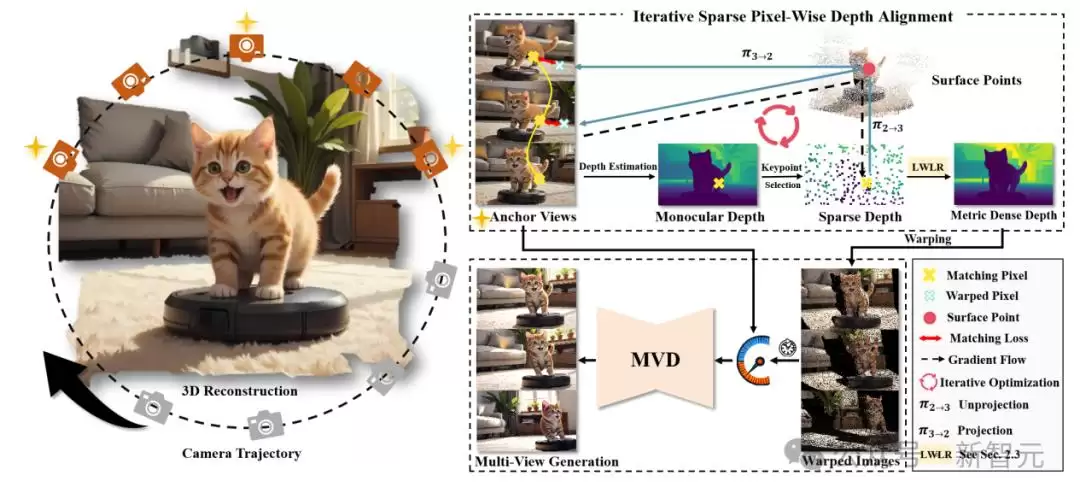
**3. 三维生成框架:学到的先验,应用在各处**
See3D学到的三维先验知识,能够支撑起一系列创作任务。无论是单视图生成、稀疏视图重建,还是开放世界场景下的三维编辑,它都能胜任。它支持在物体与场景级别的复杂相机轨迹下,生成长序列的新视角视图——这意味着你可以让镜头在场景中自由漫游,也能聚焦于某个物体的细节。
**突出优势:三大核心能力**
* **数据可扩展性**:训练数据规模达到1600万量级,相较传统方法实现了数量级提升,并且可持续扩展。
* **相机可控性**:能够支持任意复杂轨迹下的场景生成。你可以设定一条复杂的相机路径,模型会忠实地沿着该路径生成每一帧。
* **几何一致性**:即使生成长序列的新视角,模型也能很好地保持前后帧的几何一致性。换句话说,当你让镜头绕一圈再回到原点时,场景不会变得面目全非,依然保持高逼真度和真实物理规则。
**总结**
通过将数据规模做大,并巧妙利用视觉信号替代昂贵的相机标注,See3D为三维生成领域提供了一条极具潜力的技术路线。它所习得的通用三维先验,正为一系列三维创作应用赋能。这项工作的真正价值,或许在于它让研究社区看到了大规模无标注视频数据的巨大潜力,并有望缩小与那些强大但闭源的商业三维解决方案之间的差距。




