今日午后,DeepSeek 研究团队再度发布重磅成果——一篇聚焦改进稀疏注意力机制(NSA)的学术论文,旨在实现超高速的长上下文训练与推理。NSA 的核心价值在于,它能在训练阶段以极低成本引入稀疏性,从而在推理与训练两大场景中均实现显著的加速效果,尤其在解码阶段,速度最高可提升 11.6 倍。
此次论文还有一个令人瞩目的细节:DeepSeek 创始人兼 CEO 梁文锋出现在作者名单中,位列倒数第二。这表明他作为项目管理者,切实参与了前沿研究工作。此外,论文第一作者 Jingyang Yuan 是在实习期间完成此项课题的。

据 DeepSeek 介绍,NSA 架构包含三大核心模块:动态分层稀疏策略、粗粒度 token 压缩、以及精粒度 token 选择。三者协同运作,不仅提升了计算效率,还能让模型保持对全局上下文的感知能力,同时兼顾局部精确性。
这一机制专为现代硬件做了深度优化,支持原生模型训练。它在加速推理的同时,能够有效降低预训练成本,且几乎不影响模型性能。事实上,采用 NSA 的模型在通用基准测试、长上下文任务以及基于指令的推理中,表现与全注意力模型持平甚至更优。
在 8 卡 A100 计算集群上,NSA 的前向传播速度比全注意力模型快 9 倍,反向传播速度提升 6 倍。由于大幅减少了内存访问量,NSA 在长序列解码时的速度优势尤为突出。
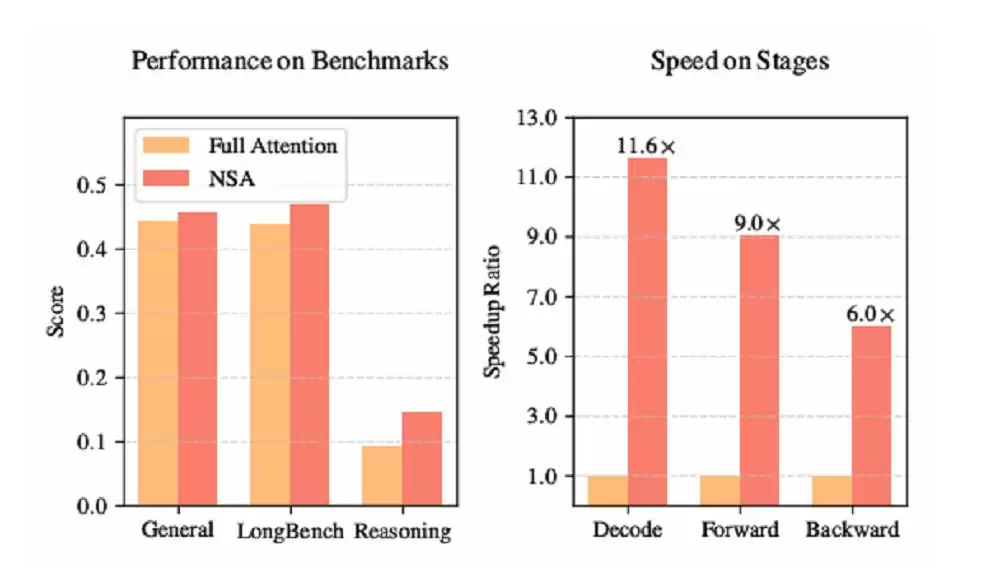
NSA 在部分测试中的表现(图源:DeepSeek)
01. 现有稀疏注意力机制的短板,正是 NSA 要填补的空白
长文本建模是下一代语言模型必须具备的关键能力,然而传统注意力机制的高复杂度使其在处理长序列时力不从心。例如,当解码 64k 长度的上下文时,注意力计算本身可能占据总延迟的 70% 到 80%。为此,稀疏注意力机制应运而生,它通过有选择地计算关键的查询-键对,来降低计算负荷。
不过,许多稀疏注意力方法虽然在理论上降低了复杂度,但在实际推理中,延迟的减少并不显著。问题出在哪里?一些方法仅在自回归解码阶段应用稀疏性,而预填充阶段仍然进行密集计算(例如 H2O);另一些方法只关注预填充阶段的稀疏性(如 MInference),导致无法实现全阶段加速。还有一些方法难以适配现代高效的解码架构(如 MQA 和 GQA),导致 KV 缓存访问量居高不下,稀疏性的优势无法充分发挥。更关键的是,现有方法大多只在推理阶段使用稀疏性,缺乏对训练阶段的支持。
DeepSeek 推出 NSA,正是为了攻克这两个核心难题:一是事后稀疏化带来的性能退化(例如预训练模型的检索头容易被剪枝);二是现有稀疏方法难以应对长序列训练的效率需求。许多现有方法存在非可训练组件以及低效的反向传播问题,这阻碍了高效训练和长上下文模型的发展。
02. 软硬件协同优化,逼近计算强度的最优解
NSA 的核心思路是通过动态分层稀疏策略,结合粗粒度的 token 压缩与细粒度的 token 选择,来平衡全局上下文感知能力与局部精确性。
从架构上看,NSA 将输入序列通过三个并行的注意力分支处理:压缩注意力、选择性注意力以及滑动窗口注意力。每个分支都有独特的注意力模式,它们相互配合,覆盖不同维度的信息。
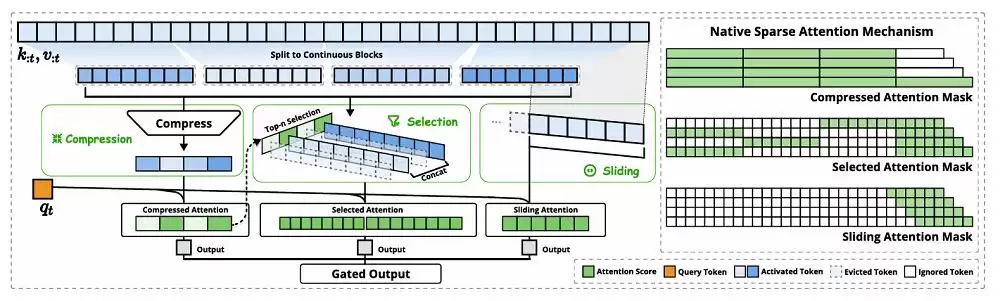
NSA 架构概览(图源:DeepSeek)
其中,压缩注意力通过将键和值聚合成块级表示,捕捉粗粒度的语义信息。这种压缩表示能够抓住更高层的语义,同时减轻计算负担。但问题在于,仅使用压缩后的键和值,可能会丢失一些重要的细粒度信息。因此,DeepSeek 引入了选择性注意力,通过一个“块选择机制”来保留这些关键信息。他们为每个块分配一个重要性分数,然后根据分数挑选出排名靠前的块,仅用这些块中的 token 进行注意力计算。这样一来,关键信息得以保留,计算负担也显著降低。
在注意力机制中,局部模式往往会快速适应并主导学习过程,这可能阻碍模型从压缩和选中的 token 中有效学习。滑动窗口注意力正是为了应对这一问题——它专注于局部上下文信息,防止模型过度依赖局部模式,从而保证学习效果的均衡。
为了实现高效的稀疏注意力计算,NSA 还针对现代硬件做了深度优化。DeepSeek 在 Triton 上实现了硬件对齐的稀疏注意力内核。他们专注于共享 KV 缓存的架构,例如分组查询注意力(GQA)和多查询注意力(MQA),这些架构与当前最先进的 LLM 保持一致。其关键优化策略是采用不同的查询分组方案,通过几个关键特性实现了近乎最优的计算强度平衡:
- 以组为中心的数据加载:在每个内循环中,加载组内所有头的查询及其共享的稀疏 KV 块索引。
- 共享 KV 加载:在内循环中,连续加载 KV 块,以最小化内存加载。
- 网格循环调度:由于内循环长度在不同查询块中几乎相同,将查询/输出循环放在 Triton 的网格调度器中,以简化和优化内核。
03. 性能实测:训练提速 6-9 倍,推理最高飙 11.6 倍
为了验证 NSA 在实际场景中的表现,DeepSeek 采用当前最先进 LLM 的常见实践,构建了一个结合 GQA 和混合专家(MoE)的骨干架构作为样本模型。该模型总参数量为 27B,其中活跃参数为 3B。他们分别使用 NSA、全注意力以及其他注意力机制进行了评估。
结果如何?在多个通用基准测试中,采用 NSA 的模型尽管具有稀疏性,但总体性能依然优于所有基线模型,包括全注意力模型——在 9 项指标中,有 7 项表现最佳。
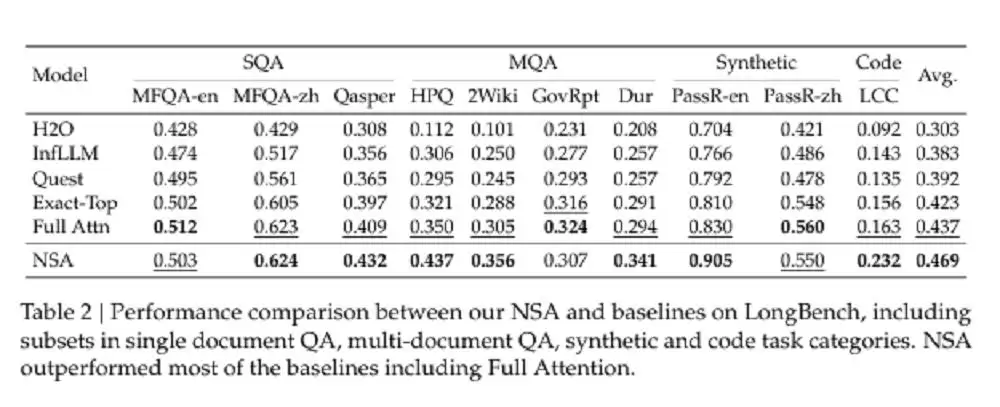
不同注意力机制在通用基准上的表现(图源:DeepSeek)
值得注意的是,虽然在较短序列上 NSA 未必能充分发挥效率优势,但其性能依然强劲。更关键的是,在推理相关的基准测试中,NSA 取得了显著提升。这说明 NSA 的预训练机制有助于模型开发出专门的注意力策略,迫使模型专注于最重要的信息,并通过过滤掉无关注意力路径中的噪声,潜在提升性能。
在长上下文任务中,NSA 在 64k 上下文的“大海捞针”测试中展现了超强的检索精度。这得益于其分层稀疏注意力设计——通过粗粒度的压缩 token 实现高效的全局上下文扫描,再通过细粒度的选择标记保留关键信息,从而在全局感知与局部精确性之间找到了平衡点。

大海捞针测试结果(图源:DeepSeek)
在 LongBench 上,NSA 在多跳 QA 任务和代码理解任务中表现优于所有基线,也展现了在复杂长文本推理任务上的优势。这些结果都表明,NSA 的原生稀疏注意力机制不仅提升了模型性能,还为长文本任务提供了更优的解决方案。
NSA 还能与推理模型结合,适配前沿的后训练方式。DeepSeek 从 DeepSeek-R1 中蒸馏知识,并结合监督微调(SFT),使采用 NSA 的模型在 32k 长度的数学推理任务上获得了链式数学推理能力。在实验中,NSA-R(稀疏注意力变体)和全注意力-R(基线模型)在 AIME 24 基准测试上进行了对比,结果显示,NSA-R 在 8k 和 16k 上下文设置下均显著优于全注意力-R,验证了其在复杂推理任务中的优势。
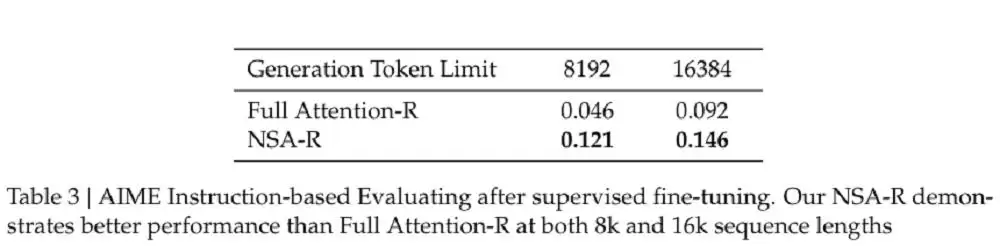
NSA-R 与全注意力-R 在 AIME 上的表现(图源:DeepSeek)
在计算效率方面,DeepSeek 在 8-GPU A100 系统上进行了对比。在训练层面,随着上下文长度的增加,NSA 的加速效果愈发显著。在 64k 上下文长度时,NSA 的前向传播速度提升了 9 倍,反向传播速度提升了 6 倍。这种加速主要得益于其硬件对齐设计:块状的内存访问模式通过合并加载最大限度地提高了 Tensor Core 的利用率,而内核中精细的循环调度则消除了冗余的 KV 传输。
在解码层面,注意力机制的解码速度主要受限于 KV 缓存加载的内存瓶颈。随着解码长度的增加,NSA 的延迟显著降低,在 64k 上下文长度时实现了高达 11.6 倍的速度提升。而且,这种内存访问效率的优势会随着序列长度的增加而变得更加明显。
04. 结语:DeepSeek 给开源 AI 带来的持续惊喜
尽管 NSA 已经取得了显著成果,但 DeepSeek 研究团队也指出了几个可能的改进方向,例如进一步优化稀疏注意力模式的学习过程,以及探索更高效的硬件实现方式。
正如 DeepSeek 之前发布的所有技术报告一样,这篇详解 NSA 机制的论文内容详实,对技术细节的阐释清晰,可操作性很强。可以说,这是 DeepSeek 给开源 AI 研究社区带来的又一份实实在在的礼物。




