AI2新模型OLMo2颠覆LLM格局训练过程全公开数据架构双升级
时间:2026-06-30 15:50
非营利机构AI2发布OLMo2系列开源模型,含7B和13B两个型号,性能与Llama3 1等主流模型相当或更优,计算效率更高。模型训练过程、数据、代码全面公开,采用多阶段训练策略降低能耗,耗电量仅为同类模型的十分之一。
【导读】非营利研究机构AI2最近拿出了他们的新作品——OLMo 2系列,并且直言不讳地称之为“迄今为止最好的完全开源模型”。这个系列不仅包含7B和13B两个型号,在性能上与Llama 3.1、Qwen 2.5等主流开源模型打平甚至更优,而且计算效率更出色,为开源大模型开辟了一条新路。
最近,非营利机构AI2上新了OLMo2系列模型,他们称之为「迄今为止最好的完全开源模型」。

OLMo 2系列包含7B和13B两个型号,与Llama 3.1和Qwen 2.5等开源模型相比,性能相当甚至更优,同时所需的FLOPS计算量更少。这意味着它在性能和计算效率之间找到了一个极佳的平衡点,为开源LLM打开了新的可能性。
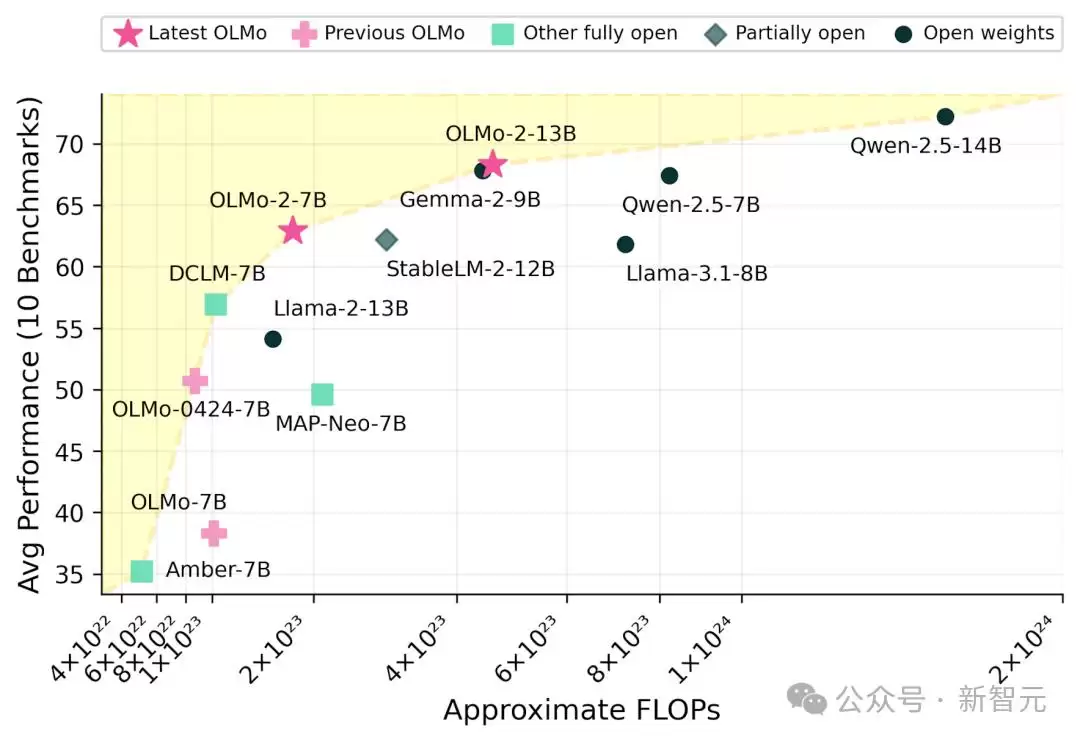
不同大小开源模型的性能对比,OLMo 2的表现优于同参数规模模型。
在多个下游任务测试中,OLMo 2的泛化能力和适应性表现突出。在10个基准测试上,OLMo-2-13B全面超越了Llama-2-13B,而OLMo-2-8B的基准均分也超过了Llama-3.1-8B。
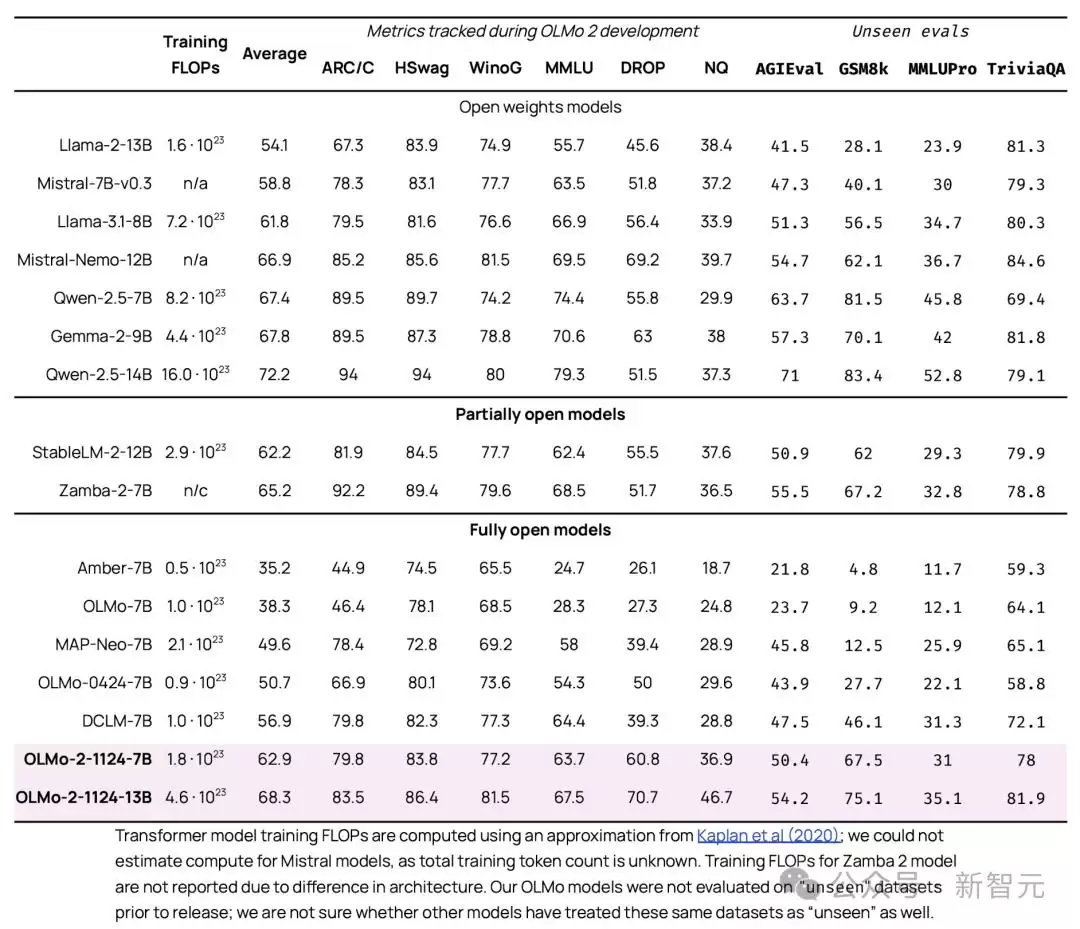
## 训练过程全公开
与Llama、Qwen这类只开源模型权重的项目不同,AI2这次依然坚持了他们一向的风格——不仅发布训练好的OLMo 2模型权重,还大方地公开了训练数据、代码和完整的训练过程。这对后续LLM的研究和应用来说,无疑是极其宝贵的资源。

论文地址:https://arxiv.org/pdf/2501.00656
OLMo 2的训练过程被清晰地划分为三个阶段:预训练、中期训练和后期的指令调优。预训练的数据混合了高质量的网页数据、代码数据和学术论文数据等。
在预训练阶段,团队通过多种技术手段来提升训练稳定性,比如过滤重复的n-gram、采用更好的初始化方法、架构优化以及超参数调整。这些都确保了模型在训练过程中不会出现崩溃或损失值剧烈波动的问题,从而最终模型的表现更上一层楼。
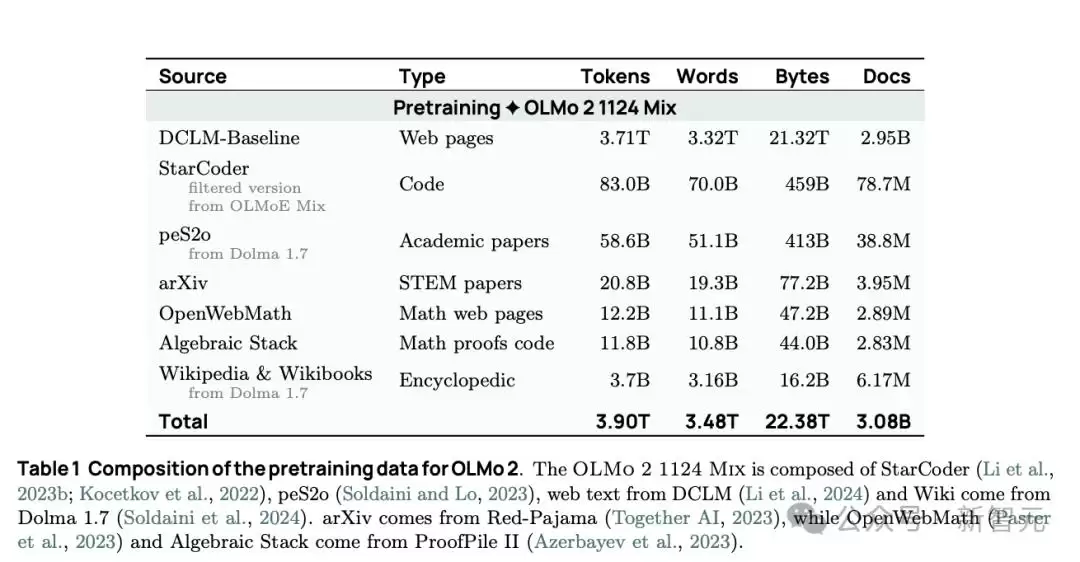
预训练使用的高质量数据集
接下来的中期训练阶段,团队使用了高质量的领域特定数据(比如数学数据)以及合成数据,重点增强模型在数学任务上的表现。配合微退火技术来评估和筛选高质量数据源,进一步优化了中期训练的效果。
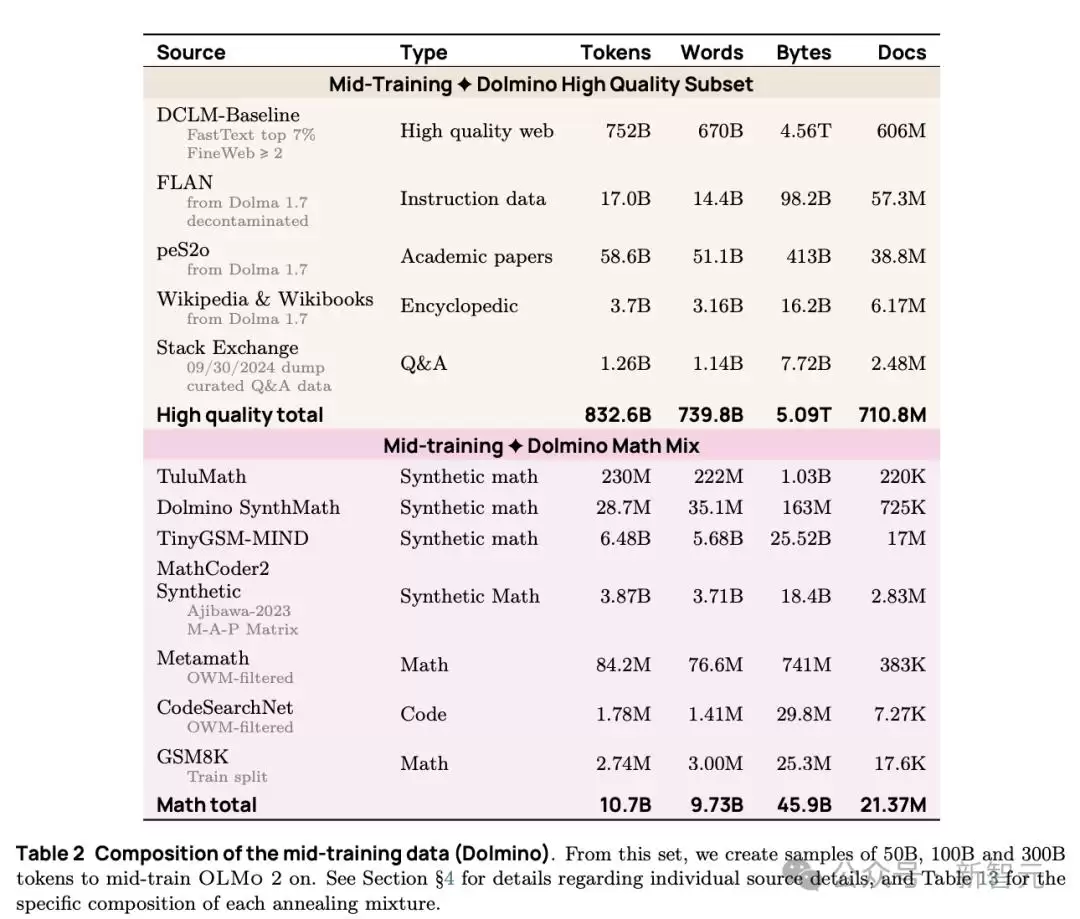
中期训练使用的高质量数据集
最后的指令调优阶段,研究人员基于Tülu 3的指令调优方法,开发出了OLMo 2-Instruct模型。这个阶段严格使用许可数据,并在最终阶段扩展了强化学习与可验证奖励(RLVR)的运用。
此外,监督微调(SFT)、直接偏好优化(DPO)和RLVR等多阶段训练策略,显著提升了模型的指令跟随能力和生成质量。
OLMo 2的开源是全方位的,所有用于复制和扩展这些模型的训练代码、评估代码、数据集、模型检查点、日志以及超参数选择,全部公开。相比只开放权重,这种做法能让更多研究人员和开发者真正上手使用、甚至改进这些模型。
通过开源所有组件,OLMo 2有助于更深入地理解语言模型的行为和使用方式,也促进了语言模型研究的透明度和可重复性。这些积累有望成为未来研究的重要基础设施。
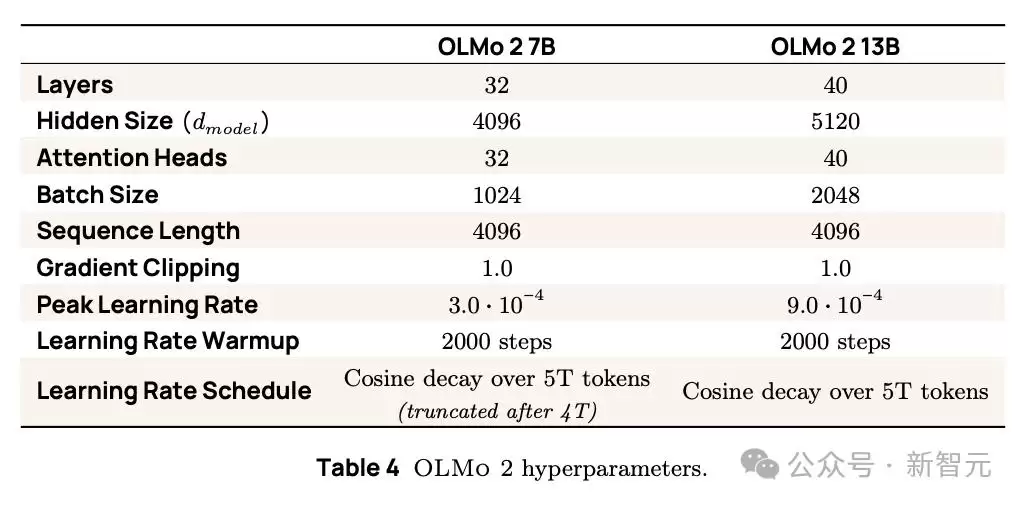
OLMo 2 7B和13B模型训练过程中的超参数
## 多管齐下造就「低碳」LLM
在大规模语言模型的训练中,计算资源和环境影响是绕不开的话题。Deepseek V3能以二十分之一的成本完成训练,而OLMo 2团队同样通过减少主机-设备同步、优化数据预处理、数据缓存等多种方法,大幅降低了训练成本,效果显著。
OLMo 2的训练主要在两个集群上完成:Jupiter和Augusta。Jupiter集群配备了128个节点,每个节点8张H100,总共1024个GPU;Augusta集群由160个A3 Mega虚拟机组成,每个虚拟机同样有8张H100,总共1280个GPU。
OLMo 2的7B模型在4.05万亿token上训练,13B模型则在5.6万亿token上训练。整体训练时间取决于模型的参数规模和数据量。
为了进一步降低能源消耗,团队还采用了水冷系统来给GPU降温和控功耗,这既提高了训练效率,也降低了电力成本。
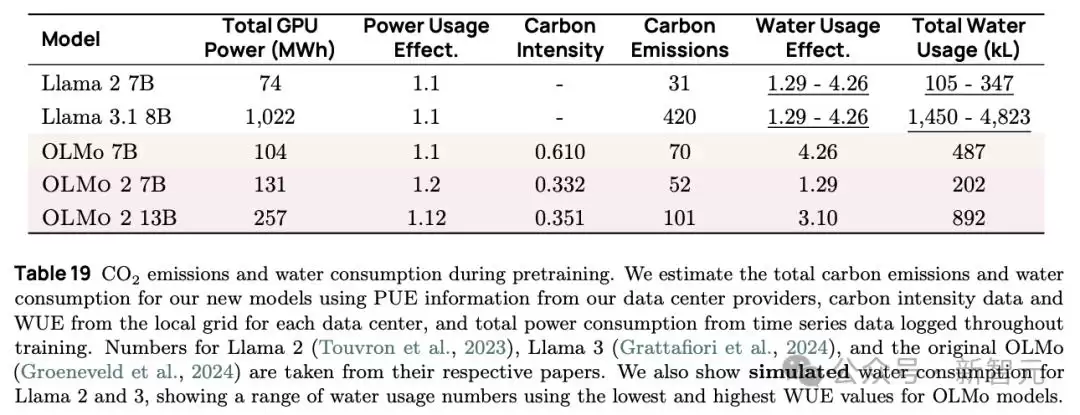
所有这些措施加在一起,效果惊人:相比训练同等大小的Llama 3.1所消耗的1022MWh电力,OLMo 2 7B在整个训练过程中只消耗了131MWh,相当于只有十分之一的耗电量。训练所需的算力、能源以及碳足迹都显著下降。
OLMo 2的发布,标志着开源LLM在持续进步,也为相关领域的研究建立了一个全新的生态系统。在这个生态里,新的训练方法和技术需要被理解、被分享、被传承。




