AI时代就这么悄无声息地来了。
谁能想到,今年春节最火的不再是互联网红包大战,也不是谁和春晚合作了,而是一家AI公司。
各家大模型公司春节前都赶着更新了一波产品,但最吸睛的,还是去年才崭露头角的DeepSeek(深度求索)。1月20日晚,DeepSeek发布推理模型DeepSeek-R1正式版,训练成本不高,性能却直接对标OpenAI的o1推理模型,而且完全免费开源。消息一出,行业震动。
这是第一次国产AI在全世界范围内,尤其是美国科技圈,引发如此强烈的反响。开发者们纷纷表示,正在认真考虑用DeepSeek“重构一切”。经过一周的发酵,1月刚上线的DeepSeek移动应用,直接登顶美区苹果应用商店免费App榜首——不仅超越了ChatGPT,还超越了所有其他热门应用。这还没完,DeepSeek的成功甚至直接反映到了美股市场上:一家没有动用巨量昂贵GPU就训练出顶级模型的公司,让市场重新审视AI的训练路径,英伟达股价一度暴跌17%。
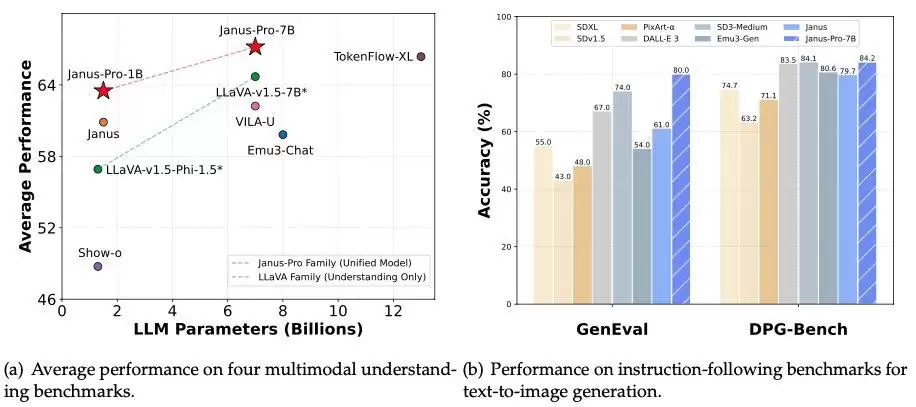
而故事还在继续。1月28日凌晨,除夕夜前一晚,DeepSeek又开源了多模态模型Janus-Pro-7B,宣布在GenEval和DPG-Bench基准测试中击败了OpenAI的DALL-E 3和Stable Diffusion。
DeepSeek真要血洗AI圈了吗?从推理模型到多模态模型,“用DeepSeek重构一切”,会是蛇年开年的主旋律吗?
Janus Pro:多模态模型创新架构的验证
这次DeepSeek深夜发布了两款模型:Janus-Pro-7B和Janus-Pro-1B(1.5B参数量)。从命名就能看出,这是2024年10月首次发布的Janus模型的升级版。
和DeepSeek的一向风格一样,这次又采用了创新架构。市面上不少视觉生成模型都用统一的Transformer架构来处理文生图和图生文任务,但DeepSeek走了另一条路:他们提出将理解(图生文)和生成(文生图)的视觉编码进行解耦。这么做的好处是提升了模型训练的灵活性,有效缓解了单一视觉编码带来的冲突和性能瓶颈。
为什么叫Janus?这来自古罗马的门神,通常被描绘成有两张面孔、分别朝向相反方向。DeepSeek的解释很形象:模型就像Janus一样,用不同的“眼睛”看向视觉数据,分别编码特征,然后用同一个“身体”(Transformer)去处理这些信号。
在Janus系列模型中,这种新思路已经展现出不错的潜力。团队表示,Janus模型指令跟随能力强,有多语言能力,模型更“聪明”,能读懂meme图片,还能处理LaTeX公式转换、图转代码等任务。而到了Janus Pro,团队对训练流程做了优化,直接实现了在GenEval和DPG-Bench基准测试中击败DALL-E 3和Stable Diffusion的成绩。
与模型一同发布的,还有Janus Flow——一个旨在统一图像理解与生成任务的新型多模态AI框架。Janus Pro模型能用简短的提示词提供更稳定的输出,视觉质量更好,细节更丰富,还具备了生成简单文本的能力。
这个模型既能生成图像,也能描述图片内容,比如识别地标景点(例如杭州西湖)、识别图像中的文字,甚至对图片中的相关知识(如“猫和老鼠”蛋糕)进行介绍。X上已经有不少用户开始上手体验了。
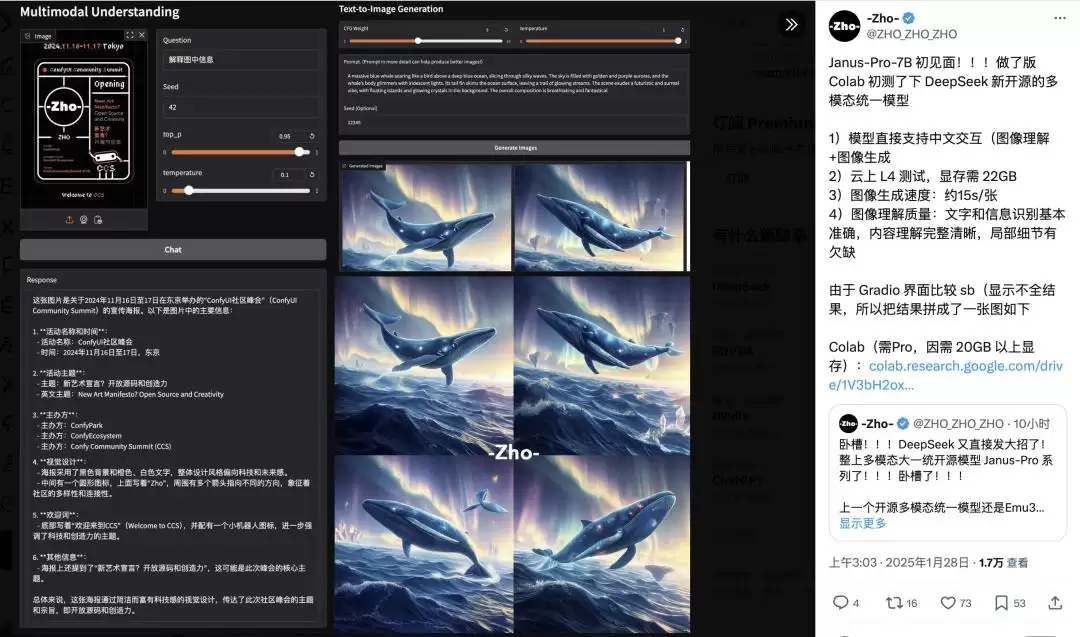
上图左侧是图像识别测试,右侧是图像生成测试。
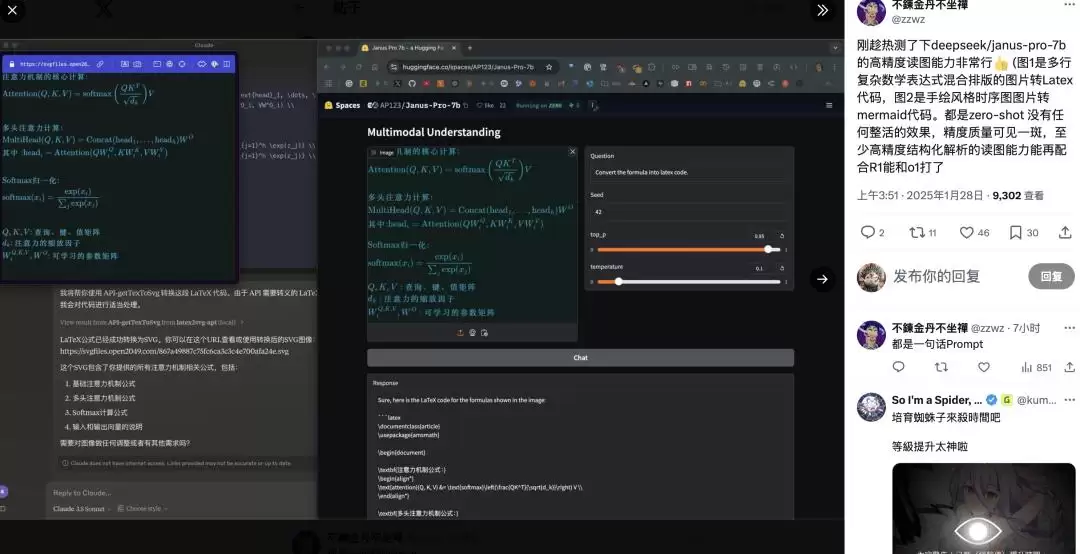
可以看到,在高精度读图方面,Janus Pro的表现相当不错,能够识别数学表达式和文字的混合排版。未来如果搭配推理模型使用,可能会有更大的应用空间。
1B和7B的参数量,或能解锁新应用场景
在多模态理解任务上,Janus-Pro采用SigLIP-L作为视觉编码器,支持384x384像素的图像输入;图像生成任务中,则使用一个来自特定来源的分词器,降采样率为16。不过坦白说,这个图像规模尺寸仍然偏小。X上有用户分析认为,Janus Pro模型更多是方向性的验证——如果验证通顺,后续就会推出可以直接投入生产的模型。
但值得注意的是,Janus Pro的创新不只体现在架构上。在参数量方面,这次也是一次新的探索。对比项DALL-E 3之前公布的参数量是120亿,而Janus Pro的大尺寸模型只有70亿。在这么紧凑的尺寸下,能做出这样的效果,已经很不容易。尤其是1B版本的Janus Pro,只用了15亿参数。外网上已经有用户将对模型的支持添加到了transformers.js——这意味着该模型现在可以在WebGPU的浏览器中100%本地运行!
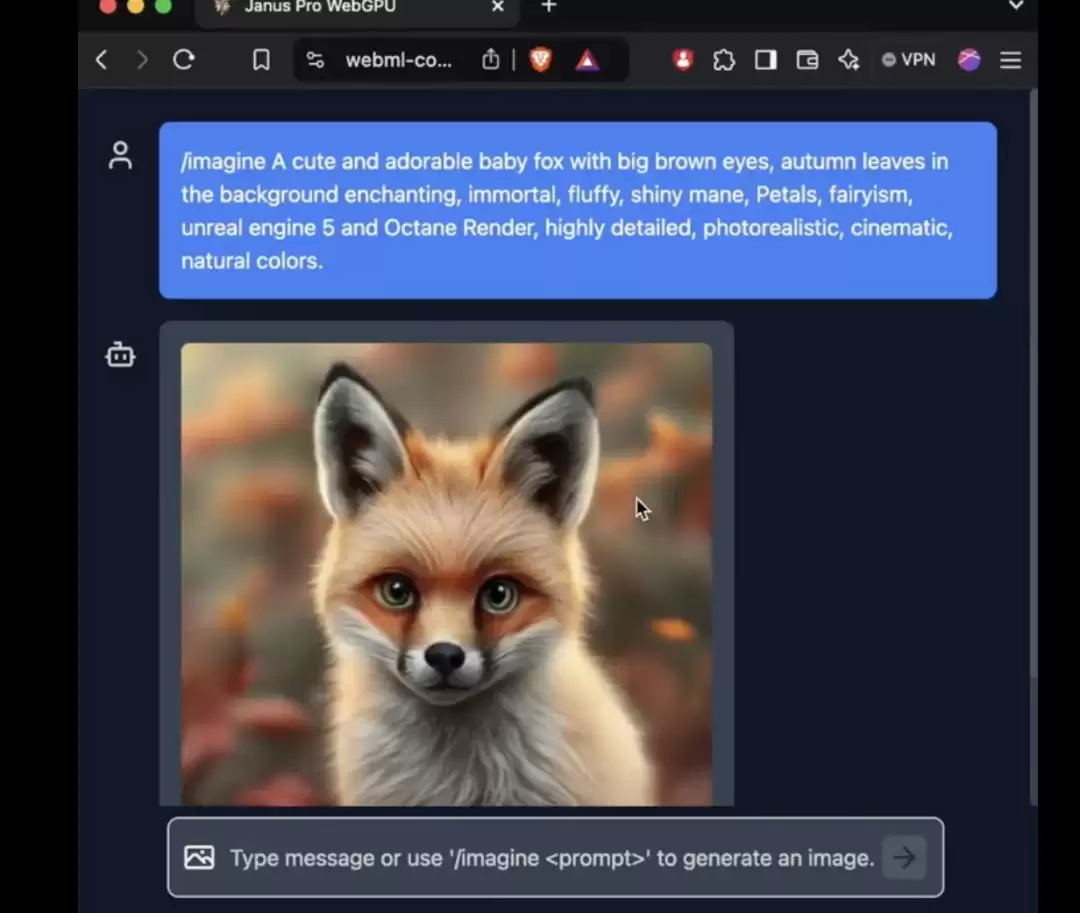
虽然截至发稿,笔者还没能在网页版上真正使用到Janus Pro新模型,但参数量小到能在网页端直接运行,这本身就是一个令人惊叹的进步。这意味着图片生成和图片理解的门槛正在进一步降低。我们有机会在更多原本无法使用这些功能的地方看到AI的身影,从而改变日常生活。
2024年的一大热点,是如何让AI硬件通过多模态理解更好地介入我们的生活。而参数量越来越低的多模态模型,或许让我们可以期待:端侧运行的模型,将进一步推动AI硬件的爆发。
DeepSeek搅动新年,万事万物可以用中国AI重做一遍?
AI世界一日千里。去年春节前后搅动全球的是OpenAI的Sora,但一年下来,中国公司在视频生成方面已经迎头赶上,让年底Sora的正式发布显得有些平淡。而今年,搅动世界的变成了中国的DeepSeek。
DeepSeek算不上传统的科技巨头,却用远低于美国大模型公司的GPU卡数和成本,做出了极具创新性的模型。美国人纷纷感叹:R1模型的训练只花了560万美元,这甚至只相当于Meta GenAI团队一位高管的年薪——这到底是什么神秘的东方力量?
一个模仿DeepSeek创始人梁文峰的parody账号直接在X上发了一张有趣的图片:

图片借用了2024年全球爆火的土耳其射击选手迪凯奇的梗。在巴黎奥运会10米气手枪决赛中,51岁的迪凯奇只戴了一副普通近视眼镜和一副睡眠耳塞,单手插兜,潇洒摘银。而其他所有选手都戴着两块专业镜片和防噪声耳塞。这个画面,和DeepSeek用极其低廉的成本挑战OpenAI的“非对称竞争”,有异曲同工之妙。
自从DeepSeek“破解”了OpenAI的推理模型,美国各大科技公司都背上了巨大压力。终于,Sam Altman也扛不住压力,出来回应了一段官方发言。
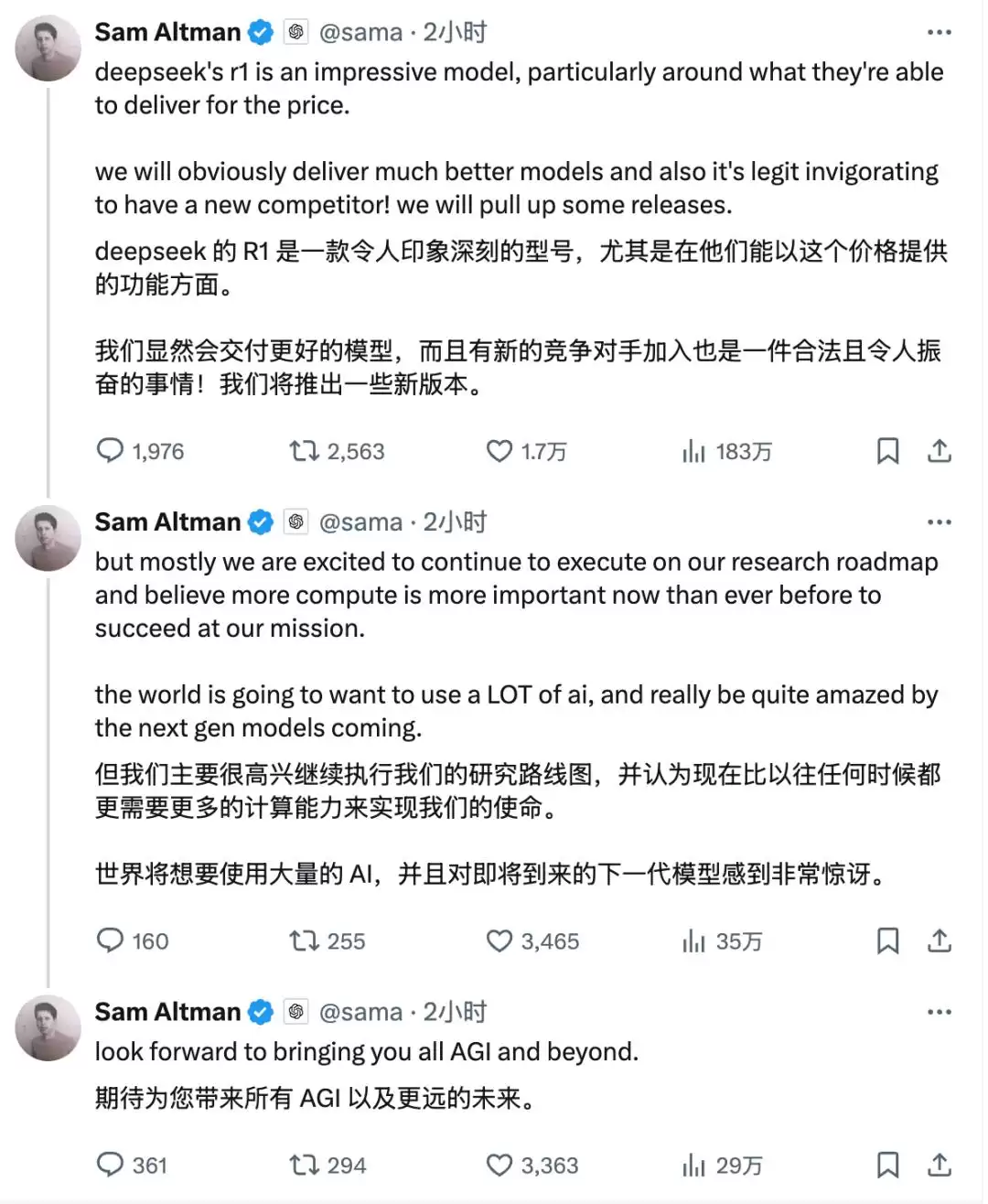
2025年,会是中国AI冲击美国认知的一年吗?DeepSeek手里还藏着什么秘密?这注定是个不平凡的春节。




