先从最近的一个信号说起——高通发布了一款面向AI数据中心的高带宽计算架构(HBC,High-Bandwidth Compute),他们自己的说法是,这套架构能让单位Token能耗更低、有效存储带宽更高,同时拉低系统总体拥有成本。一句话总结:不堆料,直接重新设计存储和算力的连接方式。
其实,当前大模型落地遇到的最棘手瓶颈,早已不是算力芯片本身不够强,而是整个行业反复在说的那个词——"内存墙"。过去,最粗暴的解法就是不断加显存、堆硬件。但到了今年,行业的共识已经明显转向:不再单纯靠硬件堆料硬扛,而是走两条互补路径——一边是用软件盘活存量,一边是在硬件层面重构底层。说白了,就是全产业链协同,用巧劲去撬动这堵越来越厚的存储墙。
01 AI推理存储矛盾越发激化
我们先拆解一下"内存墙"的本质。问题很简单:CPU和GPU的算力提升速度,远远超过了内存读写带宽和延迟的提升速度。算力芯片跑得飞快,但数据取不出来、存不进去,处理器大部分时间只能干等着,白白浪费。这就在算力和存储之间撕开了一道巨大的鸿沟。
数据也很直观:从2024到2026年,主流大模型的参数量暴涨了上百倍,上下文窗口从万字级扩展到了百万字级。但服务器的内存带宽,年均提升还不到15%,远远落后于AI业务的增速。软硬件的迭代速率严重错配,内存资源的低效浪费问题全面爆发。
当前AI推理产业面临的存储困境,可以归纳为三重,而且都不是靠传统硬件扩容就能解决的。第一,显存和高端内存极度稀缺。单台AI推理服务器的DRAM和HBM消耗量,是传统数据中心服务器的十倍以上。全球将近六成的DRAM晶圆产能,已经被AI集群占掉,消费电子和中端服务器的产能持续被挤压,HBM更是长期处于"锁单缺货"状态。第二,存储资源利用率极低。传统架构下,GPU没法直接调度外部存储,大量低频KV缓存、闲置权重参数一直盘踞在高价的HBM显存上,推理过程中的临时张量、碎片化缓存,又额外占掉30%以上的内存,资源浪费触目惊心。第三,存储成本居高不下。内存相关的支出,已经占到AI服务器硬件总成本的一半以上。中小企业因为存储门槛,根本没法落地大模型服务;头部厂商自己也因为存储产能限制,没法无限扩容推理集群。
面对这些难题,各大企业都在布局针对性的软硬件存储优化技术。精细化的调度、数据压缩、架构重构、生态联动——多种手段齐上,全面破解内存墙桎梏。
02 算法重构存储调度逻辑,盘活存量存储
软件层面的革新,核心逻辑其实就一条:不新增任何存储硬件,而是通过压缩、分层调度、跨设备资源复用,把服务器上闲置的内存和闪存盘活,削减高价显存的无效占用。这条路径落地门槛低、见效快,是当下行业的主流过渡方案。市面上各类厂商自研的工具、量化算法,本质上都是这套思路的具体落地。
行业不约而同地把KV缓存作为显存消耗的核心攻坚对象,优化方向分成了两大分支。第一个是无损低比特量化压缩。它跳出传统量化会损伤模型精度的局限,靠数学变换和误差校正机制,在极低比特位宽下维持模型输出效果,直接压缩显存占用、拉高推理吞吐。谷歌推出的TurboQuant是这条路线的一个典型验证案例——依靠极坐标变换与误差校正,实现了3比特近乎无损的KV缓存压缩,实测在长文本场景下,显存占用压缩了6倍,推理吞吐提升了8倍。英伟达的NVFP4量化套件也走的是同一个逻辑,3比特档位的精度损失控制在0.8%以内,而他们的研究团队还提出了一种KVTC(KV缓存变换编码)技术,把压缩的理论上限推到了20倍,进一步印证了低比特压缩的潜力。
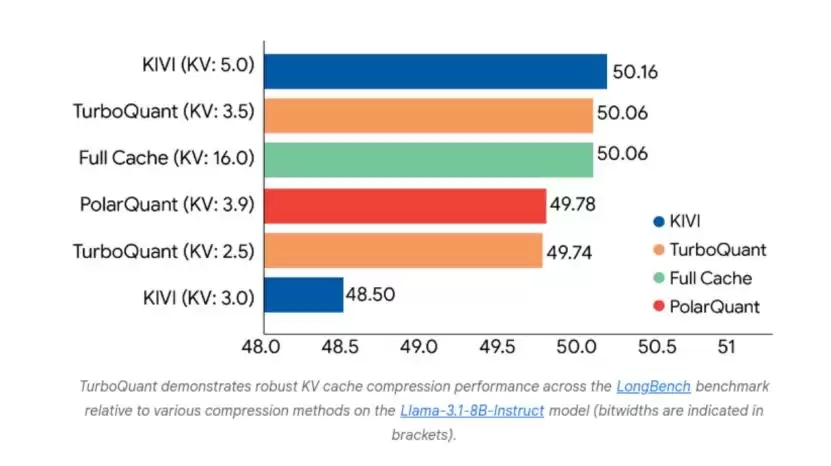
▲ TurboQuant的缓存压缩性能图(来源:谷歌正式)
第二个方向是全域分布式分层调度。打通GPU、HBM、主机DRAM、本地闪存、远端存储等多层介质,靠冷热数据自动分流,打破单卡显存孤岛,降低硬件综合成本。英伟达的Dynamo 1.0推理操作系统搭配BlueField-4 CMX平台,就是这套机制的完整落地——自研的缓存管理和低延迟RDMA传输模块,能自动区分高、中、低频上下文,把温冷缓存下沉到共享存储池,在GB200集群实测中,MoE模型吞吐最高提升7倍,单位Token硬件成本下降40%。AMD收购的MEXT推出的AI预测内存技术,则补充了闪存扩容分支的落地案例——通过算法抹平闪存与DRAM的性能差距,实现可用内存扩容2到4倍,基础设施成本减半,完善了低成本扩容的软件解法。
整体来看,所有软件技术都围绕"存量挖潜"展开。只是各家厂商基于自身的芯片、DPU、处理器硬件禀赋,在压缩、集群调度、闪存扩容等不同侧重点上做了选择,但底层目标完全一致。
03 重塑存算物理底层,消耗传输损耗
软件优化毕竟只能在现有硬件框架内做资源再分配,它突破不了芯片互联和存储介质的物理上限。要承载万亿参数模型、大规模AI智能体并行任务,就必须重构存算协同的底层硬件架构。
当前行业因此分化出三条主线。第一条:拉高单节点高速存储上限,打造一体化高性能整机集群。核心思路是提升原生HBM规格、增加专用存储硬件来分担缓存压力,重构总线通路实现GPU直连外部存储,搭建多层级硬件存储底座。比如,专门为破解长上下文KV缓存显存挤占问题而设计的BlueField-4 STX专用存储机架,就是英伟达Vera Rubin全栈AI计算存储平台的核心落地方案。整套平台以NVL72 GPU机架作为算力底座,单卡搭载288GB HBM4,单机架合计20.7TB高速显存,用来存放超低延迟实时交互的热数据;STX机架则新增独立CMX上下文存储层,作为外置共享缓存池,承载海量复用型KV缓存,从硬件层面拆分冷热数据、分流显存负载。相较传统方案,集群Token处理效率提升了5倍。此外,英伟达与亚马逊联合推出的GIDS直通技术,实现了GPU绕开CPU直连SSD,整机有效可用存储硬件扩容16倍。这套分层架构的实测证明,依靠外置专用存储池分担显存压力,可以稳定支撑百万Token超长上下文、上千智能体并行的高负载推理场景。
第二条路线:搭建标准化通用共享内存池,走开放兼容路线。依托通用互联协议,打通全品类算力与存储,把分散的内存资源整合成统一的逻辑池。它不绑定自有硬件,能适配多品牌混合部署。英特尔以CXL 2.0架构为核心落地了这套方案——依靠至强6代处理器的原生协议,打通CPU、GPU、FPGA与各类内存介质,并联合阿里云、腾讯云、美光完成了商业化落地。这是当前跨节点内存共享成熟度最高的方案,用产业生态合作的成果,验证了开放内存池的规模化落地能力。
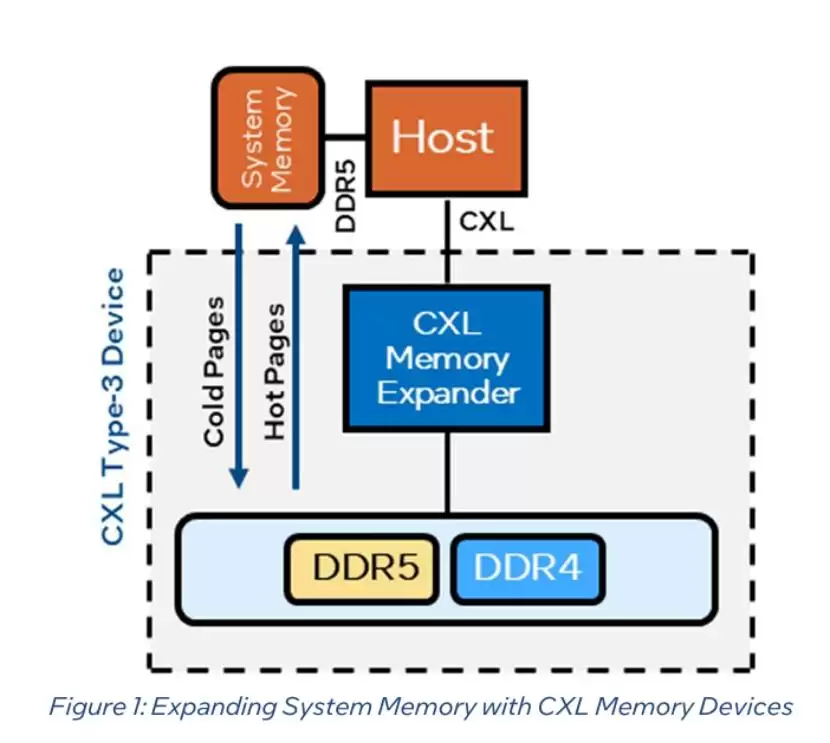
▲ 来源:英特尔正式
第三条路线:补齐大容量低成本高速存储介质,构建混合分层存储体系。针对HBM带宽虽高但容量小、造价昂贵的短板,研发新型高带宽闪存作为中频缓存载体,形成"HBM热数据 + HBF中频缓存 + 普通闪存冷数据"的三级硬件架构。SK海力士与闪迪联合研发的HBF高带宽闪存,就是这条路线的核心验证载体——单模块最高512GB,容量是同规格HBM的8到16倍,读取性能远超传统SSD,还能降低成本。
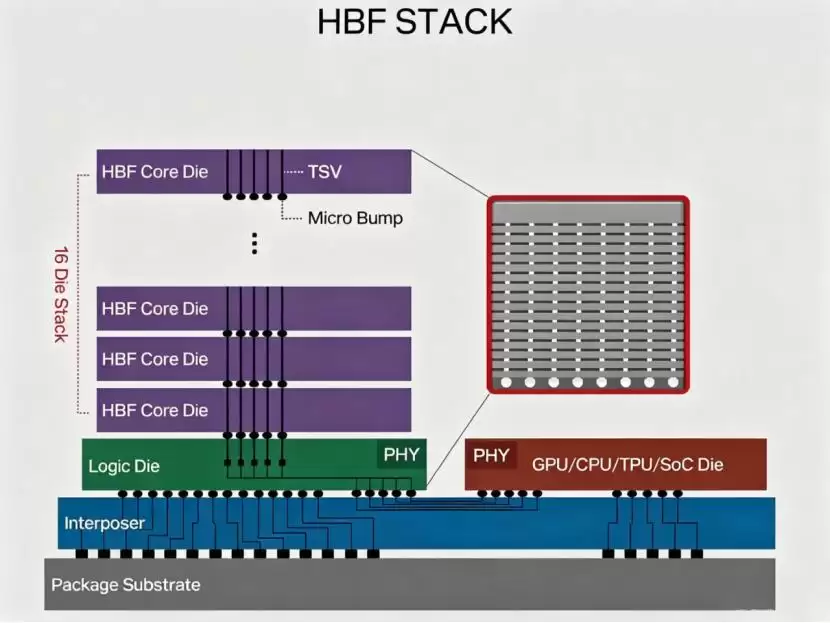
▲ HBF堆叠架构示意图(来源:Tom's Hardware)
与上述三种方式不同,高通最近提出的HBC高带宽计算3D堆叠架构比较新颖——它把翻跟斗直接放到LPDDR堆栈下方,通过TSV直连来规避HBM的高成本。最新数据显示,HBC相较传统HBM实现了每瓦带宽提升6倍,对比SRAM达成了每瓦容量提升200倍。第一代HBC Gen1搭载在AI250上,单卡读写带宽133TB/s,相比AI200带宽提升了18倍;新一代HBC Gen2赋能Dragonfly AI300推理翻跟斗,整体性能比AI200提升了54倍,单卡每瓦内存带宽相较主流GPU架构高出4到8倍。
业内专家的判断是:软件算法负责短期降本和缓解显存紧缺,革新的硬件架构则负责打开长期性能天花板。软硬协同、分层混合存储,将是未来很长一段时间破解内存墙的核心产业路径。它的影响远不止于推理提速和硬件成本下降——它还会重塑全球存储供需格局与定价体系,降低中小企业落地大模型的硬件门槛,同时缓解行业普遍存在的内存资源浪费问题。




