你在终端里敲下 tab,AI 补全了剩下的代码。编译通过,逻辑通顺,变量命名比你写的还漂亮。你甚至有点恍惚——这家伙是不是真的懂我在干什么?
然后你把这段代码放到多卡环境跑,三秒后 GPU 全部 hang 住,nvidia-smi 显示进程还在,但通信像被按下了暂停键。
AI 编程的真实水平就在这里:它能写出让你惊叹的局部代码,但一旦涉及它没见过的跨设备协同失败模式,再强的模型也会交出编译通过但死锁的东西。
局部能打满分,全局就开始露馅
Together AI 最近放出了一个叫 ParallelKernelBench 的 benchmark,里面包含 87 个真实的多 GPU 内核生成任务。每一个任务都要求替代 PyTorch NCCL 的标准实现,自己写 CUDA kernel 直接走 NVLink、走对称内存、走 GPU 之间的数据搬运。单 GPU 写 kernel 已经够难了,多 GPU 的设计空间还要乘上 tensor 切分、context 切分、data 切分、expert 切分、sequence 切分、FSDP 切分的排列组合。瓶颈从本地算力/显存漂移到了互联/通信,模型还得自己选 GPU 间数据搬运的方式——copy engine、TMA、SM load/store 还是 NVLS。
结果怎么样?zero-shot 最好的模型只对了 28/87,其中 22 个比 PyTorch NCCL 基线快。给三次机会,最好成绩提到 36/87 正确、27/87 更快。fast_1@3 卡在 31%。
这些数字背后有两个规律,比数字本身重要得多。
第一个规律:弱模型更容易卡在编译阶段——语法错、类型对不上、API 调用不对;强推理模型的问题则更多上移到运行时:代码能编译,结构也工整,但跑起来要么输出错,要么直接死锁。这里不要把它读成精确百分比,重点是失败位置从“语法层”移到了“协同层”。
这恰好戳穿了一个幻觉:AI 写代码的分层可靠性,关键变量已经从「它理解逻辑」滑向了「它见过足够多相似样本」。局部语法和模式匹配是 AI 的舒适区,因为 GitHub 上到处都是单 GPU kernel 的写法。但多 GPU 的 rank 协调、数据分区、集合通信排序、传输机制选择——这些在训练数据里稀疏得多,而且每个场景的组合都不一样,没有现成模板可以抄。强模型翻车发生在它没见过足够多样本、也推导不出正确组合的空间里——不是写不出语法正确的代码,而是写出的代码能顺利编译,一跑就死。
第二个规律:agent 循环确实有帮助,但有一个硬天花板。Gemini 3 Pro 从单次 24/87 正确,经过 agent 循环(跑代码、看报错、修 bug 再跑)提升到 35/87 正确、26/87 更快,修复的主要是语法错误、shape 不匹配、简单的运行时 bug。原测试记录里,约 20 步 refinement 之后,增益就平了。
这很说明问题。agent 循环能修的东西都是有明确反馈信号引导你修的东西——编译器报错告诉你第几行哪个变量类型不对,你改就是了。但死锁没有这种信号。八个 rank 互相等着对方发消息,没有报错信息,没有栈回溯,除了超时你什么都不知道。debug 这种问题靠的是对通信拓扑的理解——你必须在脑子里建一个分布式系统的模型才能定位到哪个 rank 卡在哪个 barrier、哪个 collective 操作顺序错了。agent 循环在反馈信号空白的空间里就是瞎撞。
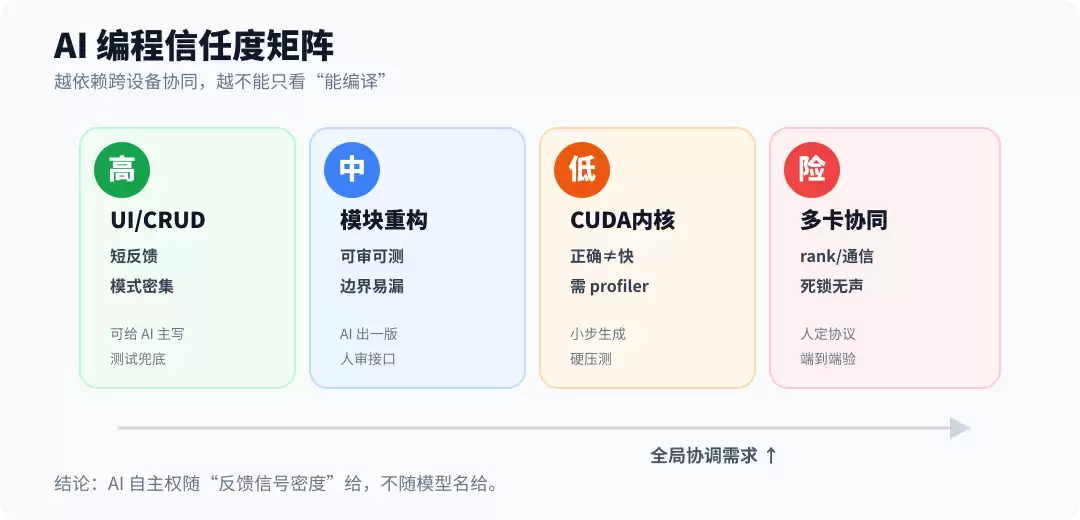
AI 编程信任度矩阵
从单卡到多卡,AI编程的可靠性逐层崩塌
把 87 个任务按「局部 vs 全局」「模式化 vs 协调需求高」两个维度切开,你看到的是一张有明确断崖的地图——每一层对应不同的分层可靠性水平。先说清楚:下面这张图不是 PKB 官方分类,而是把它的 collective primitive、tensor/context/expert parallel、FSDP/ZeRO 等任务,翻译成开发者更容易用的信任度地图。PKB 的 87 个任务主要落在后两层;前两层是我们日常使用 AI 编程时的对照组。
第一层——单设备、模式密集、有即时反馈信号的任务。AI 在这里已经非常可靠。你画个 UI 组件,写个 CRUD 接口,生成测试用例,补充文档——这些事 AI 做起来又快又好,因为互联网上到处都是这些代码,模型见过的样本量足够大,而且你做错了浏览器直接报错、测试直接挂,反馈回路极短。可信度:高。
第二层——单模块重构、中等规模的业务逻辑。AI 能写出不错的第一版,但你必须审。它可能漏边界条件,可能改了 A 函数影响到 B 模块的一个隐含依赖,但因为还在单进程单设备上跑,出错了你能立刻看到。可信度:中,需要人工 review。
第三层——CUDA kernel、性能敏感代码。AI 能生成语法正确的代码,但「正确」和「高效」之间隔着一套它没有内化的人的经验。它能写出对的规约求和,但用 shared memory 省几次 global memory 访问、怎么躲 bank conflict、寄存器压力多大——这些它只能碰运气。不过好在单 GPU 的 kernel 错了至少报错,反馈回路还在。可信度:中低,跑得过编译不等于跑得出正确结果。
第四层——多设备、多 rank、分布式协同。这是当前 AI 编程的断崖区。模型够聪明,问题在于这层代码的正确性锚点取决于「八个 rank 对全局状态的一致理解」,本地逻辑写得再严密也白搭。你写一个 all-reduce,代码在每一个 rank 上的逻辑看起来都对,但只要 rank 3 的通信顺序和 rank 5 差了一个调用,整个集群就死了。跨设备协同的反馈信号是空的,agent 循环也救不了。可信度:低,除非你同时配了硬测试、profiler 和人工审核。
ParallelKernelBench 里也有相当漂亮的正面案例:一些 AI 生成的 kernel 打败了公开的参考实现,比如 NeMo-RL 的 vocab-parallel log-prob/top-k/top-p、Hyena 的 context parallelism、SAM 3 的 mask IoU suppression——这些结果在 4 块 H100 上经过重复随机测试验证过。AI 在这个层次上的真正问题是「不可靠」——你不知道它这一次行还是下一次行,这一个任务行还是下一个任务行。
反馈信号耗尽以后,模型只会原地打转
agent 循环在约 20 步后增益归零,这个现象值得单独拎出来讲。
在单设备任务上,agent 循环的价值很大。你让它写一个 React 组件,跑起来不对,浏览器控制台有错,它读报错修代码再跑,三五轮下来基本能搞定。这是因为错误信号和修复路径之间存在清晰的映射——报错说 props 类型不对,改 props 类型;报错说 API 404,检查 URL。
但在多 GPU 协同任务上,错误信号和修复路径之间的映射是断裂的。八个 rank 全卡住,你能看到的只有「跑不动了」。是通信顺序错了?是某个 rank 的数据 tensor 维度和其他 rank 不一致?是某个 src/dst 配错了?没有报错告诉你。模型只能猜,猜不到就往回退,退回到它训练分布里最常见的模式——而那往往是错的。
agent 循环的能力边界等于它所依赖的反馈信号的丰富程度。信号密集的空间里它能自我进化,信号空白的空间里它就是瞎撞。多 GPU 编程是信号空白的典型代表:它的错误藏在代码之间的运行时交互里,单元测试根本碰不到。
这才是开发者真正需要内化的东西。你需要的是分层可靠性判断——「在什么场景下可以给它多大自主权」——而不是一个「AI 编程靠不靠谱」的简单答案。你给 AI 一个 CRUD 接口写完直接合,问题不大;你给 AI 一个需要协调八个 rank 的集体通信 kernel 让它自己跑,那是你心大。
把 AI 当成一个见过海量代码但从来没有真正跑过多 GPU 集群的初级工程师。它写的东西看起来像模像样,局部逻辑无可挑剔,但你得替它想清楚那些它没见过的全局约束。在你给它这些约束之前,它的输出是一枚编译通过的死锁冲击波——不爆纯粹靠运气。
我会把它落成一个很土的把关法:
- 可让 AI 自主写:UI、CRUD、脚手架、测试样例、文档补齐;前提是测试能立刻给反馈。
- 可让 AI 写第一版:单模块重构、业务逻辑、单 GPU kernel;前提是人审接口、补边界用例、跑 profiler。
- 不能让 AI 独自决定:多 rank 通信、跨设备数据搬运、分布式训练里的 collective 顺序;协议由人定,AI 只能当实现助手。
官方结果给的是 87 个任务上的成功率;本文的“分层可靠性”是把这些结果翻译成日常开发决策。你可以不同意分层的边界,但至少别再用一个总分回答“AI 编程行不行”。真正要问的是:这段代码的反馈信号够不够密,失败会不会藏在多个进程之间。
延伸阅读
ParallelKernelBench: Frontier LLMs can't write fast multi-GPU kernels (yet) — https://www.together.ai/blog/parallelkernelbench
ParallelKernelBench paper — https://openreview.net/forum?id=4IGomFc9dx
ParallelKernelBench GitHub — https://github.com/togethercomputer/ParallelKernelBench




