在单张GPU上同时部署多个模型实例,是推理服务中十分常见的需求。以阿里云PAI-EAS为例,操作流程并不复杂:先购买GPU专有资源组(包月),再将模型打分服务部署至该资源组。
首先,我们来聊聊硬件选型。推理卡通常选用A10(32核)、gu30或L20等型号。例如,A10的显存容量为24G(实际可用略低于24G),可切分为3个实例,每个实例分配7G显存——请注意不要设置为8G,保留一定余量更为稳妥。
参数详解
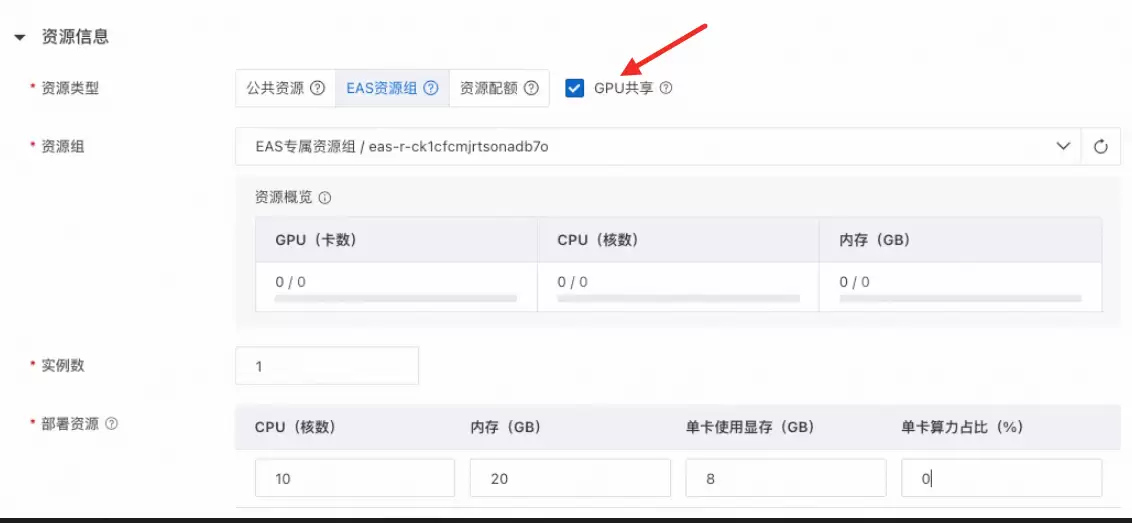
以下是几个关键参数,具体操作将在下一节详细说明。请牢记,PAI-EAS服务配置中最核心的参数是 gpu_memory 字段,其值应设为7(即7GB)。
需要注意一个常见陷阱:gpu_core_percentage 参数最好不进行配置,否则可能导致GPU响应时间(RT)出现毛刺。此外,在EasyRec中需设置 cuda: "11.2"。
引擎配置单(pairec)中还有一个重要参数 BatchCount,该参数决定了每次打分处理的物品数量。
操作步骤
(1)点击“更新服务”
(2)启用“GPU”共享,依次设置CPU数量、内存容量以及显存大小
(3)点击“确定”完成服务更新
(4)前往PAI-EAS服务“监控”标签页,查看CPU内存与GPU显存占用情况
若内存和GPU显存显示正常,且服务状态为“运行中”,则表明配置已成功生效。
CPU核心:32个
内存容量:188G
gu30显卡:每个实例分配7G显存
GPU核心占比:30%


(5)调整引擎配置单中的BatchCount
BatchCount通常设置在100到300之间。举个例子:当BatchCount=300、精排数量为900时,精排PAI-EAS服务至少需要3个实例才能快速返回打分结果;如果仅部署1个实例,则需分3次打分,耗时将增加至3倍。

参考TorchEasyRec版本的配置文件
TorchEasyRec Processor: https://help.aliyun.com/zh/pai/torcheasyrec-processor
EasyRec版本:参考DataWorks部署任务的脚本
在EasyRec中,必须将 cuda 参数设置为 "11.2"




