今天,DeepSeek 联合北大放出了一个值得关注的新东西——DSpark 推理加速框架。这玩意儿的目标很明确:解决大模型在真实高并发场景下的推理效率问题,也就是怎么让用户感觉响应更快、系统吃得消更多人同时用。
目前,这个框架已经用在了 DeepSeek-V4-Flash 和 V4-Pro 的预览版服务里。效果如何?简单说,在保持同样吞吐量的前提下,单个用户能感受到的生成速度,比他们之前用的 MTP-1 基线方案快了 60% 到 85%。论文和代码也已经开源在 GitHub 上。
先聊点背景。大语言模型生成文本时,是典型的“自回归”模式:每吐出一个新 token,就得完整跑一次前向传播。模型输出长度越长,推理延迟就线性增长。这其实是很多 AI 对话系统响应偏慢的核心所在。
推测解码:一个可行的解决方向
推测解码技术提供了一条路径。思路很聪明:先拿一个轻量级的小模型快速猜出一段候选 token,然后再由大模型一次性并行验证这批候选,只保留符合要求的连续前缀。因为验证阶段是并行计算的,再加上拒绝采样机制能严格保证输出分布和原始模型一致,所以理论上可以在不损失生成质量的前提下,大幅提升速度。
但理想很丰满,现实有两个坎:一是候选生成的质量,二是验证阶段对目标模型计算资源的占用。
目前主流方案分成两派。
一派是自回归式草稿模型,比如 Eagle3。它逐个 token 串行生成候选,依赖关系建模能力强,接受率高,但候选越长,生成延迟就越长,逼得实际部署中只能用短候选块和浅层网络。
另一派是并行式草稿模型,比如 DFlash。它一次前向传播就能产出全部候选,生成延迟几乎和候选长度无关,理论上支持更长的候选块。但问题在于,并行生成每个位置时,它无法依赖块内前面已经采样的 token,这就导致随着候选位置往后移,不同语义路径会相互冲突,接受率迅速衰减。长候选块后面的 token,经常在验证阶段被大量拒绝,造成目标模型计算资源的浪费。尤其在高并发环境下,固定长度的验证策略,会让大模型宝贵的批量处理能力,耗费在高拒绝风险的尾部 token 上,最终拖累整体吞吐量。
而 DSpark 的设计,正是围绕这两个瓶颈展开的,提出了两项互补机制。
半自回归架构:并行能力与顺序依赖的结合
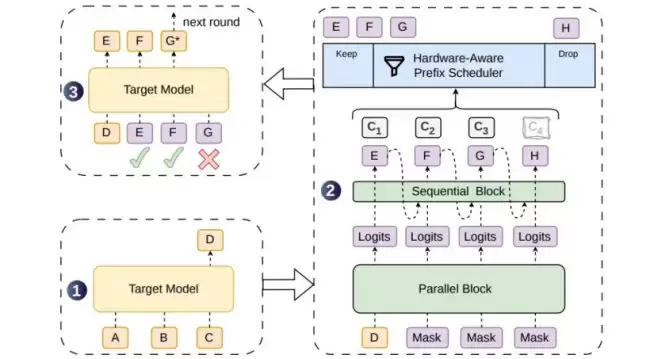
在候选生成阶段,DSpark 采用了一种“半自回归”架构。简单说,计算量较大的并行主干网络(基于 DFlash 改进)先一次性产出所有候选位置的隐藏状态和基础 logits;随后,一个轻量级的顺序模块再逐 token 注入前缀依赖信息。这个顺序模块有两种实现方式:一种是只依赖前一个 token 的马尔可夫头,另一种是通过循环状态累积完整前缀信息的 RNN 头。
实验数据证明,两层 Transformer 深度的 DSpark,在所有测试领域上,接受长度已经超越了五层深度的 DFlash。这说明:只要引入少量自回归依赖,参数效率就能完胜单纯堆叠并行层。
置信度调度验证:让验证计算花在刀刃上
在验证调度阶段,DSpark 引入了一套“置信度调度验证”机制。模型在每个候选位置会输出一个置信度分数,预测这个 token 在给定此前所有 token 都被接受的情况下,存活下来的概率。训练完成后,团队在验证集上通过逐位置温度缩放,对置信度进行校准,使其与经验接受率对齐。
在此基础上,一个“硬件感知前缀调度器”将验证长度选择,建模成全局吞吐量最大化问题。给定一批并发请求及其各位置置信度,结合预先实测的引擎吞吐量曲线,调度器会为每个请求动态决定验证多长的候选前缀。它的核心逻辑很简单:优先将目标模型的计算资源,分配给那些全局存活概率最高的 token。
离线测试与在线实战
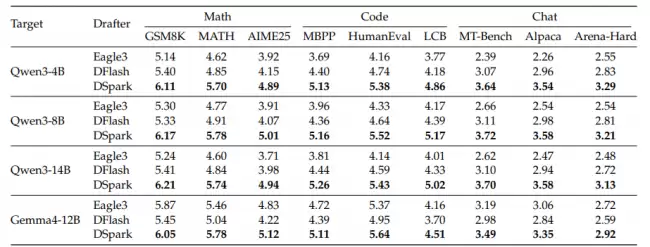
在离线基准测试中,研究团队选了 Qwen3 系列和 Gemma4-12B 作为目标模型,对比了自回归方案 Eagle3 和并行方案 DFlash。在数学推理、代码生成和日常对话三类任务上,DSpark 的平均每轮接受长度,均优于两类基线。
举个例子,在 Qwen3-4B 上,DSpark 的接受长度比 Eagle3 提升约 30.9%,比 DFlash 提升约 16.3%。进一步分析位置级条件接受率就会发现:DFlash 首位接受率高,靠的是并行架构能支撑更深网络带来的容量优势,但从第 2 位起接受率迅速下滑;Eagle3 正好相反,后续位置保持稳定甚至上升,但首位受限于浅层网络。DSpark 则两条路都占了:继承了并行架构的首位容量优势,同时通过顺序依赖缓解了后续位置的衰减。
到了真实的生产环境部署,DSpark 草稿模型与 DeepSeek-V4-Flash 及 V4-Pro 预览版共同运行。并行主干包含了 3 个 MoE 层与滑动窗口注意力,最大候选块长度设为 5,并采用马尔可夫头作为顺序模块。
训练阶段还有两项系统优化。其一,并行训练时只传递目标模型的隐藏状态而非完整词表 logits,将通信复杂度从 O(V) 降至 O(d);其二,采用锚点定长序列打包策略,把训练序列中随机采样的多个预测块压缩为密集批次,避免了传统填充带来的计算和内存浪费。
实际系统集成时,调度器还遇到了两个工程约束。
第一个是 CUDA 图重放和零开销调度要求下一轮批处理大小必须在当前轮完成前确定,同步调度会导致 GPU 流水线停滞。解决办法是改造为异步模式:用当前轮置信度排序候选 token,但截断长度依据两轮前的历史置信度来预测,从而隐藏了调度延迟。
第二个是动态变长验证前缀,会导致标准解码内核因填充和负载不均而利用率下降。团队将物理执行与逻辑序列跟踪解耦,把所有 token 展平为独立元素处理,通过稀疏注意力中的标记张量传递序列内依赖关系,只需修改索引注意力与压缩内核就能支持动态调度。
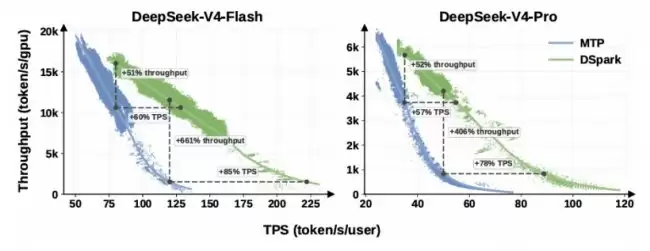
在线生产环境的实测结果更说明问题。在 V4-Flash 引擎上,当系统保证单用户生成速度不低于 80 token/s 时,DSpark 的聚合吞吐量比基线提升了 51%。当 SLA 收紧到 120 token/s 时,单 token 基线已经接近运行边界,而 DSpark 依然能维持可用并发批处理,实现了标称 661% 的吞吐量优势。
在 V4-Pro 引擎上,35 token/s 的 SLA 下,吞吐量提升 52%;50 token/s 的 SLA 下,提升直接来到 406%。而在匹配的实际吞吐量水平下,DSpark 将单用户生成速度提升了 57% 到 85%。
调度器也表现出了负载自适应的能力。系统并发数低时,它会分配 4 到 6 个 token 的验证长度,充分用足空闲计算资源;并发数一高,就平滑缩减验证长度,避免资源争用。
当然也有局限。即便后缀 token 最终被调度器截断,并行主干仍需为所有请求生成完整的初始候选块。对那些本身接受率就低的复杂查询,这部分草稿计算开销是无法回收的。
目前,DeepSeek 已经在 GitHub 的 DeepSpec 项目里开源了 DSpark、DFlash 和 Eagle3 三种草稿模型的训练代码、评估脚本及模型检查点。
参考资料:
GitHub:https://github.com/deepseek-ai/DeepSpec
Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark




