多模态推理领域最近迎来了一项有意思的进展——SCoT(自结构化推理链)框架。简单来说,它把推理过程拆解成最小的语义单元,然后根据问题的复杂度动态生成最合适的推理结构。这样一来,既避免了简单问题上的过度思考,也解决了复杂问题上的推理天花板。

为了让这个想法落地,研究团队还同步推出了一个名为AtomThink的全流程框架,涵盖了数据构造、训练、推理和评估四个关键环节,专门用来提升多模态大模型在复杂推理任务上的表现。
从实验结果来看,SCoT确实展现出了自适应能力——复杂问题的推理链条会自动变长,简单问题的链条则相对精简。在多个公开数据集上,AtomThink框架都显著提升了基线模型的准确率,同时数据利用效率和推理效率同样表现亮眼。更有意思的是,通过原子能力评估,研究人员还发现了多模态模型在不同推理能力上的分布特征,这为理解多模态推理机制提供了一个全新的视角。
这项研究由来自中山大学、香港科技大学、上海交通大学、香港大学、华&为诺亚方舟实验室的研究人员合作完成。接下来,我们展开聊聊具体的技术细节。

SCoT、AtomThink长啥样?
先说说当前结构化与非结构化CoT各自面临的困境。现有的方法,要么依赖固定模板进行结构化推理,要么采用自由形式的非结构化推理。前者的问题是推理行为单一、需要人工设计模板,后者则容易出现计算效率低下、在简单问题上过度思考的毛病。
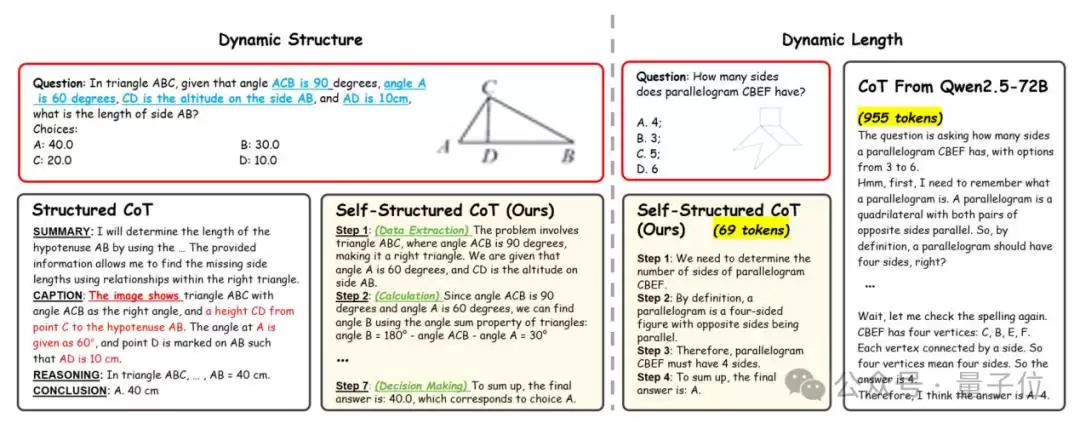
基于这样的观察,团队提出了两个核心假设:一是不同类型的问题可能需要不同的推理能力;二是推理的复杂性应当与问题本身的难度相匹配。为了给不同复杂度的问题动态生成合适的推理结构,研究人员引入了自结构化思维链(SCoT)以及全程框架AtomThink。
SCoT的核心思路,是把推理过程分解成最小的语义单位——也就是原子步骤。模型每轮只预测一个原子步骤,然后把这个步骤追加到已有的推理链条中,作为下一轮推理的输入。为了防止模型在推理过程中间出现重复或停滞等异常行为,团队还设计了基于规则的过滤机制和温度累积策略,用来增强推理的多样性和流畅性。
AtomThink框架则包含四个关键模块:
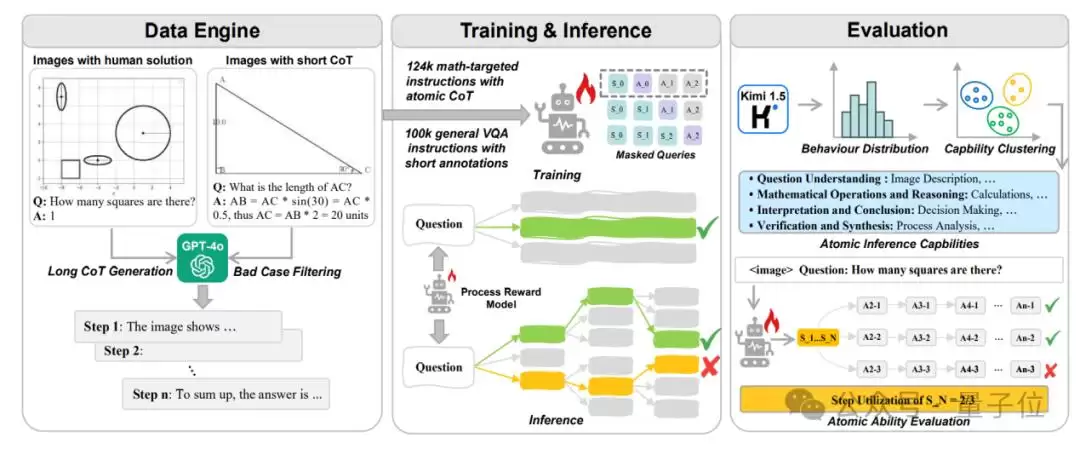
数据引擎:通过动态提示策略和短推理增强方法,生成高质量的多步推理路径,构建了一个包含2万道多模态数学问题和12.4万个原子步骤标注的数据集AMATH。
原子步骤微调:采用步骤级掩码训练,迫使模型学会独立推理每个步骤。
策略引导的多轮推理:在过程监督模型的基础上,结合路径搜索和步骤搜索策略(如多数投票、最优候选选择、贪婪算法和束搜索),扩展推理空间。
原子能力评估:基于推理行为聚类和步骤利用率计算,系统评估模型在不同推理能力上的表现。
实验结果如何?
研究团队选取了不同规模的LLaVA1.5-7B和Llama3.2-Vision-11B作为基线模型,利用AMATH-SFT数据集进行微调,然后在MathVista、MathVerse、MathVision和Humanity’s Last Exam四个基准数据集上做评估。实验设置涵盖直接推理、普通CoT、SCoT,以及结合过程奖励模型(PRM)的SCoT推理。
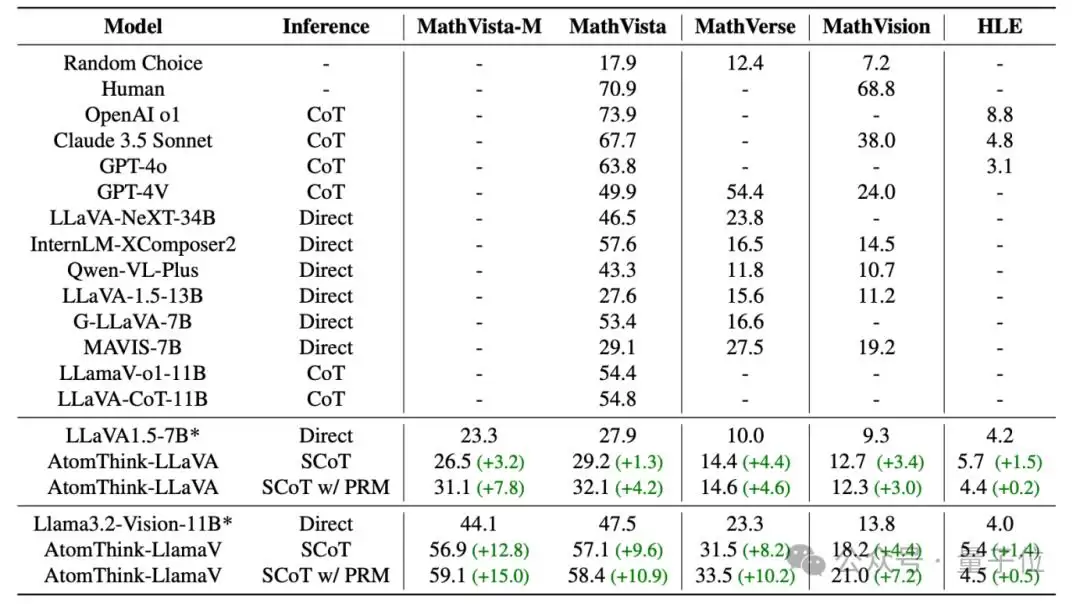
在MathVista、MathVerse和MathVision三个数据集上,AtomThink框架让Llama3.2-Vision-11B模型的准确率分别提升了10.9%、10.2%和7.2%,这个提升幅度已经相当可观。
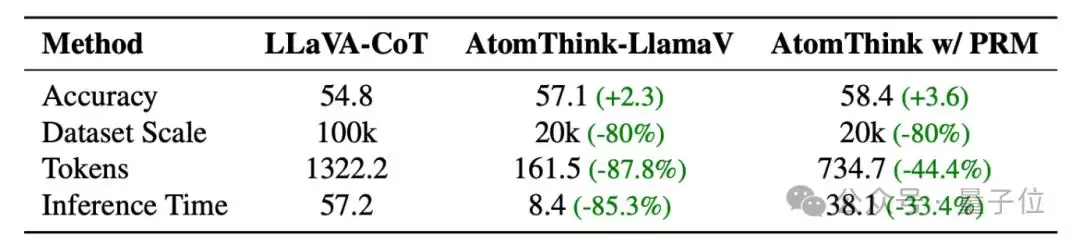
和现有的结构化CoT方法相比,AtomThink在准确率、数据利用效率和推理效率上都有明显优势。具体来说,在超越LLaVA-CoT准确率的前提下,数据利用效率提升了5倍,推理效率提升了85.3%。
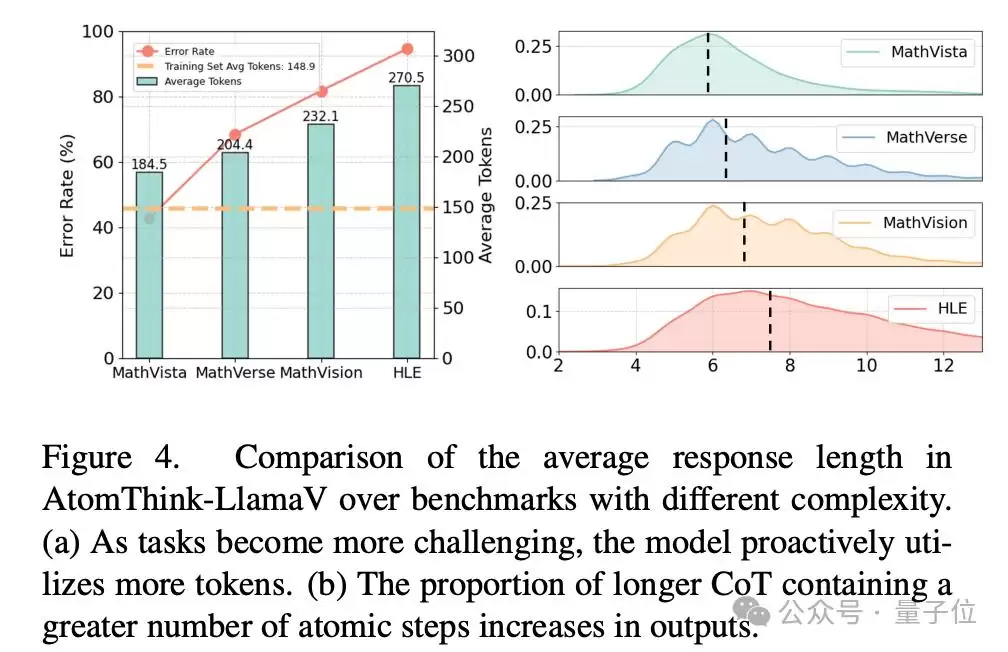
值得关注的是,与结构化方法相比,SCoT生成的推理结构更加多样化,涵盖了图像描述、数据提取、逻辑推理、因果推理等多种能力。模型还能根据问题复杂度自动调整推理链长度——复杂问题推理步骤更长,表现出一种自适应的深度探索能力。
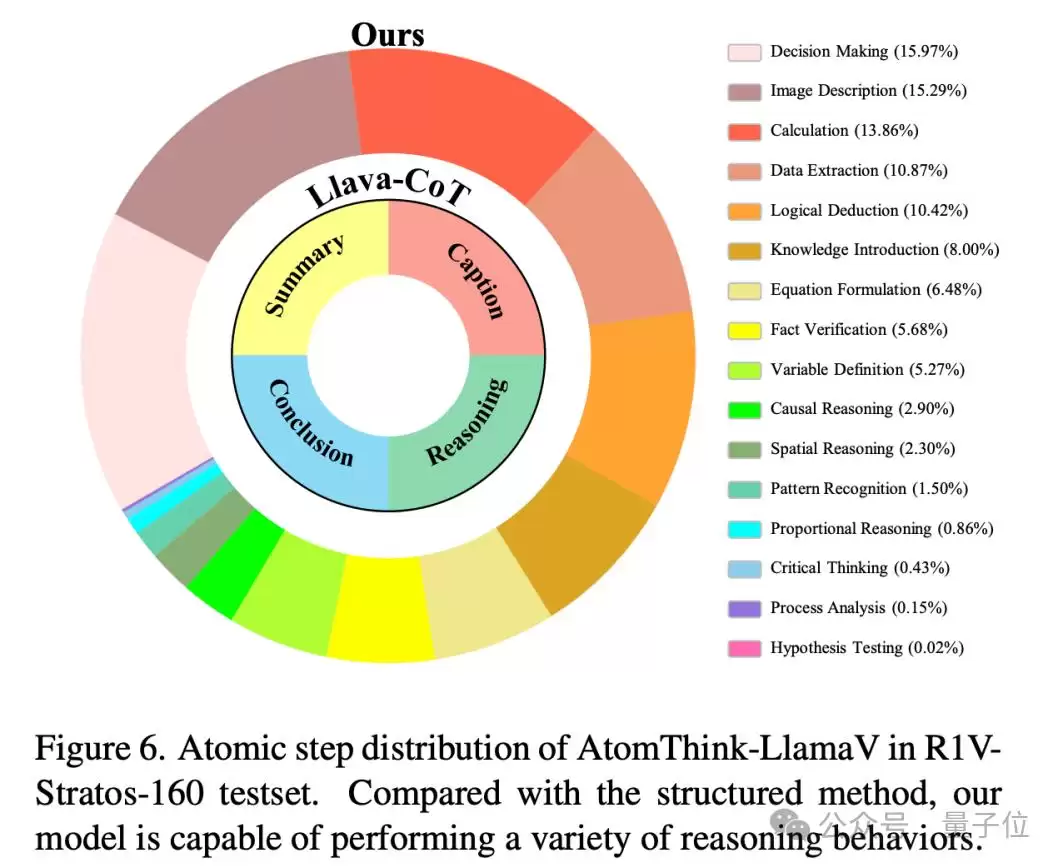
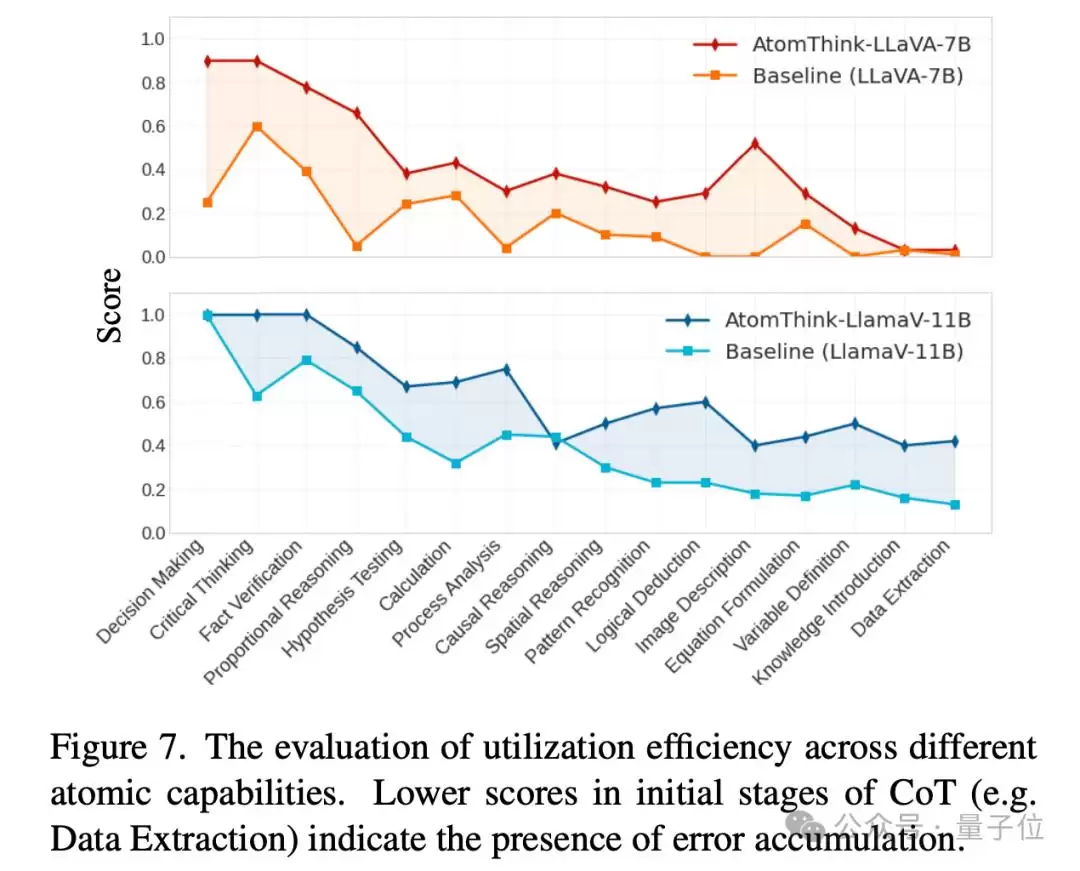
为了更深入地评估模型对不同中间步骤的利用能力,团队还设计了一套全新的评估方法。他们首先通过聚类GPT-4o的推理行为,生成一个包含16种行为的原子步骤分布集合,然后构建历史步骤,通过rollout计算模型对最近步骤的利用效率。
原子能力评估的结果揭示了一个值得警惕的现象:模型在推理过程中存在误差累积效应。尤其是在CoT早期阶段,比如数据提取和图像描述环节,错误继承率较高。这意味着,未来的工作可能需要更关注推理初期的质量控制。