OpenAI憋了很久的“杀手锏”——o3模型,终于正式亮相了。从官方放出的预告和早期测试来看,这次升级的幅度不小,尤其是在推理能力和多模态理解上,确实带来了不少让人眼前一亮的东西。
有意思的是,有医学专家专门拿临床问题去“拷问”o3,结果o3给出的回答,水平直逼顶级专科医生。这说明什么?说明模型在专业领域的知识深度和推理精度上,又往前迈了一大步。
如何验证?不妨来个直观测试。比如让o3和o4-mini分别去解读“洛就完了”这个表情包:
o3给出的解读:

o4-mini的解读:


两个模型给出的答案各有侧重,你更倾向于哪一个?
强化学习的Scaling Law
这次o3最值得关注的地方,倒还不是具体分数,而是它背后那条“强化学习的Scaling Law”。
开发过程中,研究人员发现了一个有意思的趋势:大规模强化学习,正在复现预训练阶段那个“更大计算量=更好性能”的规律。简单来说,在强化学习这个维度上,计算量堆得越多,模型性能也跟着水涨船高。

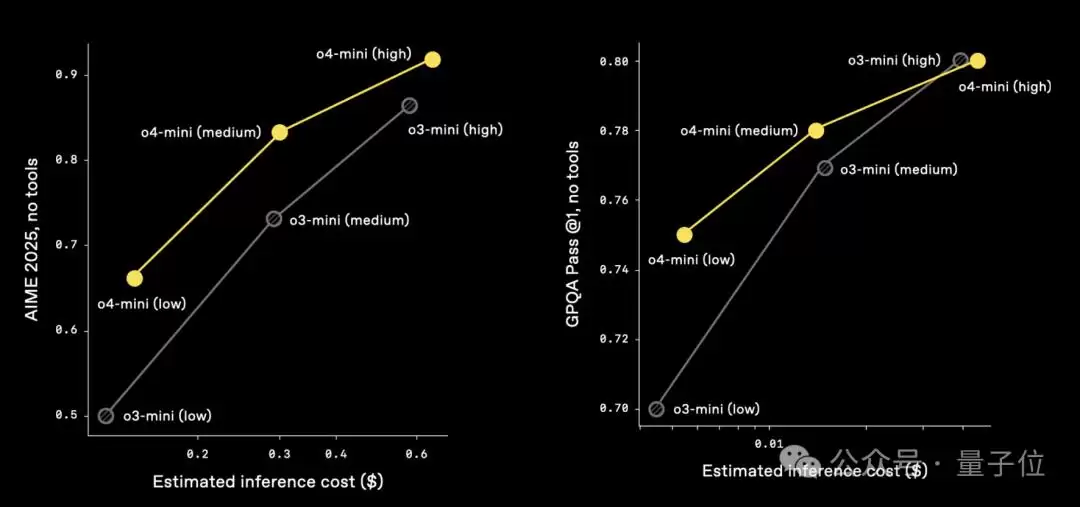
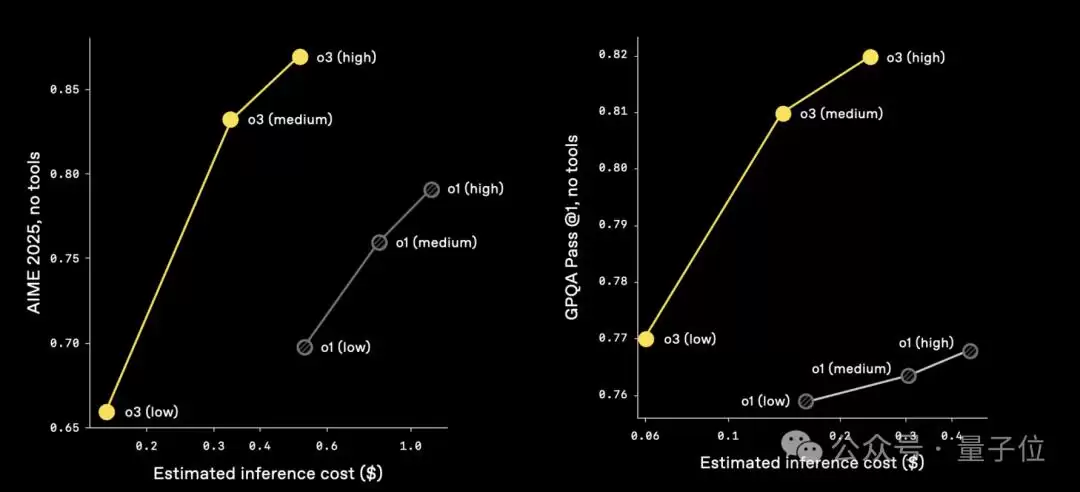
与此同时,OpenAI也开始在性价比上花心思了。自从DeepSeek成为搅动格局的鲶鱼之后,市场上的声音都在倒逼各家优化成本。o3和o4-mini就证明了这一点:在AIME 2025的测试里,o4-mini对比o3-mini,o3对比o1,在相同的推理成本下,都能拿到更高的分数。
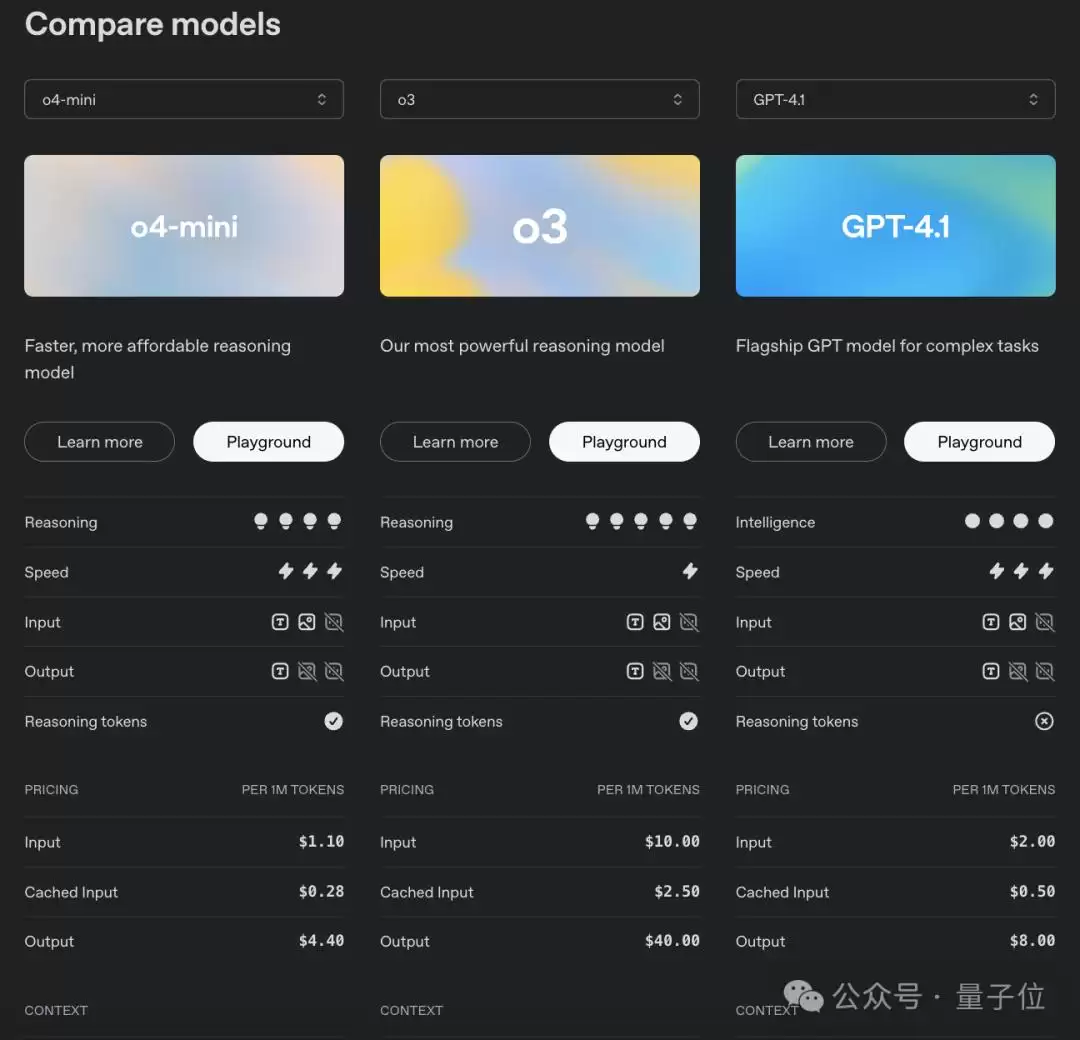
至于API定价,这里拉上前一天刚亮相的GPT-4.1一起做个对比,具体价格一目了然:
One More Thing
消息还不止这些。OpenAI再次向社区开源,这次带来的是一个本地运行的代码智能体——Codex CLI。它的核心能力,是将自然语言指令直接转化为可运行的代码,而且兼容所有OpenAI模型,包括刚发布的o3、o4-mini和GPT-4.1。
这个工具显然是给那些习惯终端操作的开发者准备的。它提供了ChatGPT级别的推理能力,同时又支持实际运行代码、操作文件和迭代开发——一种聊天驱动的开发方式,能够直接理解并执行本地代码库。