 SGLang项目架构示意图
SGLang项目架构示意图
面对一个拥有30万行代码的庞大项目,通常需要花费多长时间才能真正读懂它?
近日,SGLang团队发布了一个极具价值的教育型项目——mini-SGLang。简单来说,该团队将原本庞大的30万行代码库,大幅精简至仅5000行。更为关键的是,项目保留了所有核心优化技术:重叠调度(Overlap Scheduling)、FlashAttention-3、基数缓存(Radix Cache)等。在在线服务场景下的性能测试中,迷你版的推理效率几乎与完整版本持平,丝毫不打折扣。
为何需要迷你版?
道理并不复杂。许多开发者渴望深入理解现代大语言模型(LLM)推理引擎的内部运转机制,但面对30万行的工业级生产代码,光是通读一遍就需要整整一周,更不用说完全吃透了。mini-SGLang正是为解决这一学习痛点而诞生。它不仅涵盖了所有关键优化技巧,代码量还压缩得足够小巧——即便你只在周末抽出时间,也能通读并掌握其精髓。
核心功能完整保留
不妨看看迷你版究竟保留了哪些“看家本领”:
- 高效的请求重叠调度技术
- FlashAttention-3与FlashInfer高性能内核
- 基数缓存机制与分块预填充技术
- 张量并行支持
- JIT编译CUDA内核
- 兼容OpenAI的API接口
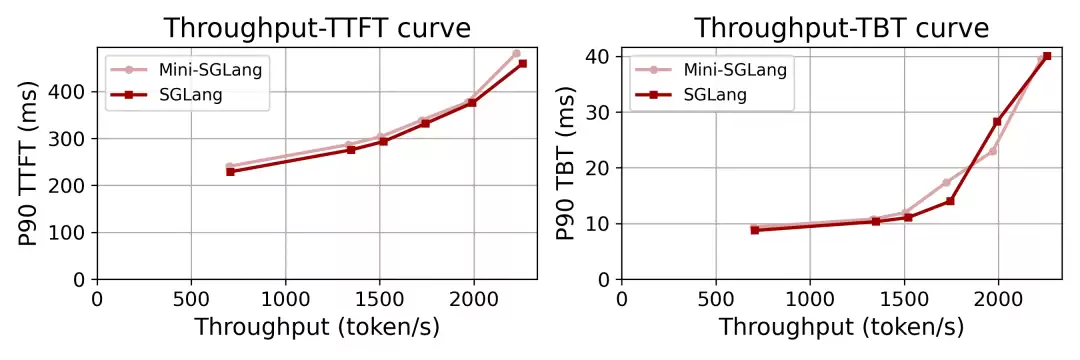 Mini-SGLang与完整版性能对比图
Mini-SGLang与完整版性能对比图
在Qwen3-32B模型搭配4张H200显卡的实际负载测试中,mini-SGLang的表现与完整版不相上下。从性能数据来看,这次代码压缩的“功力”确实相当扎实。
定位明确:学习与实验
不少开发者关心mini-SGLang是否支持GGUF格式服务。开发团队的态度非常明确:这个版本主打教学与实验目的,不推荐用于生产环境或需要完整后端扩展的场景。如果真正需要GGUF这类生产级能力,还是应当直接使用完整的SGLang项目。
另一个常见问题是低比特量化支持。目前mini-SGLang主要聚焦于展示核心推理优化技术,对于8比特以下的量化格式,官方尚未明确支持计划。
技术细节
作为目前唯一能够同时支持在线/离线服务、流式传输以及请求重叠调度的小型化推理引擎,mini-SGLang展现了极高的精简设计水平。有趣的是,有开发者指出,这种极致的精简方案甚至为将来将核心逻辑从Python迁移到其他编程语言,提供了天然的实验基础。
当然,如果你需要最新的CUDA内核(例如支持sm_120/Blackwell架构),或者高性能的NVFP4、FP8等格式,mini-SGLang可能还需要一段时间才能跟进更新。
相关链接:
- GitHub仓库:https://github.com/sgl-project/mini-sglang
- 完整性能测试报告:https://lmsys.org/blog/2025-12-17-minisgl/




