尽管 Gemini 3 Flash 发布后获得了广泛好评,但 AA-Omniscience 基准的最新数据却为这股热情浇了一盆冷水:该模型的幻觉率高达 91%,在所有参测模型中几乎垫底。所谓幻觉率,简而言之,就是模型在应该回答“我不知道”的时候,强行编造出一个答案的比例——这恰恰是大型语言模型最致命的缺陷之一。
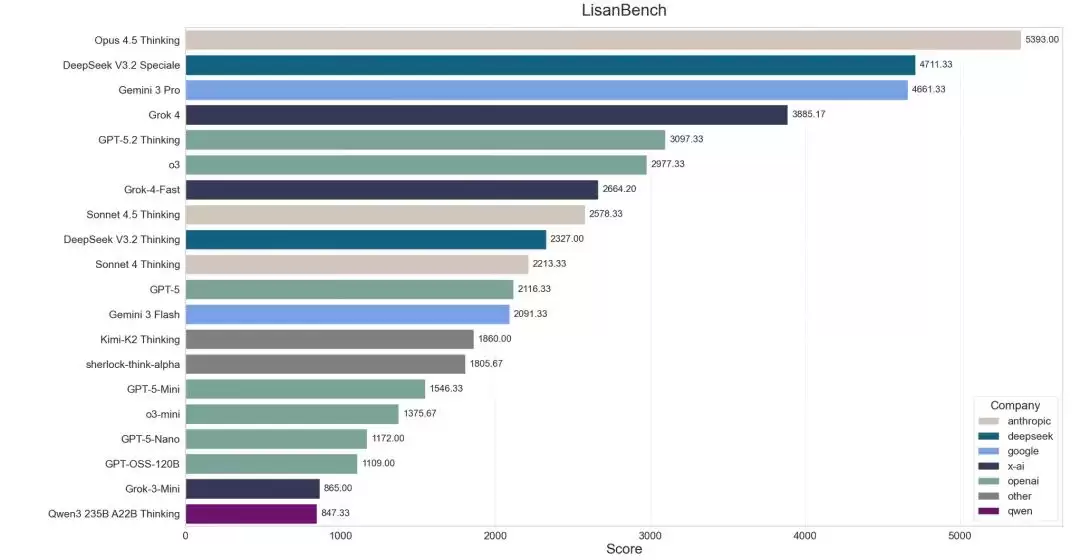
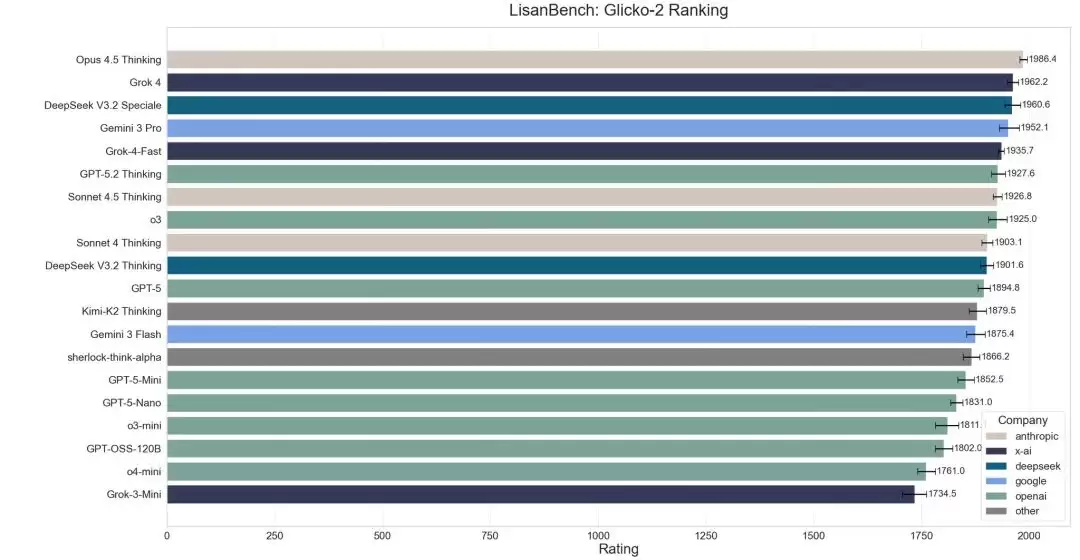
在覆盖范围更广泛的 LisanBench 测试中,Gemini 3 Flash 仅位列第 12 名(Glicko-2 Elo 排名第 13)。该基准专门评估模型的前瞻性规划、词汇深度、约束遵循、注意力以及长上下文持久力——听上去颇为复杂,本质上却是一个词汇链游戏:模型需要借助莱文斯坦距离为 1 的变换规则,连续生成有效的单词链条。测试者 Lisan al Gaib 采用了“reasoning effort high”设置,整项测试成本仅略高于 16 美元。结果表明,Gemini 3 Flash 的表现与 DeepSeek-V3.2 Thinking、Kimi-K2-Thinking 等开源模型,以及 GPT-5、Sonnet-4 等业界前沿模型大致持平。
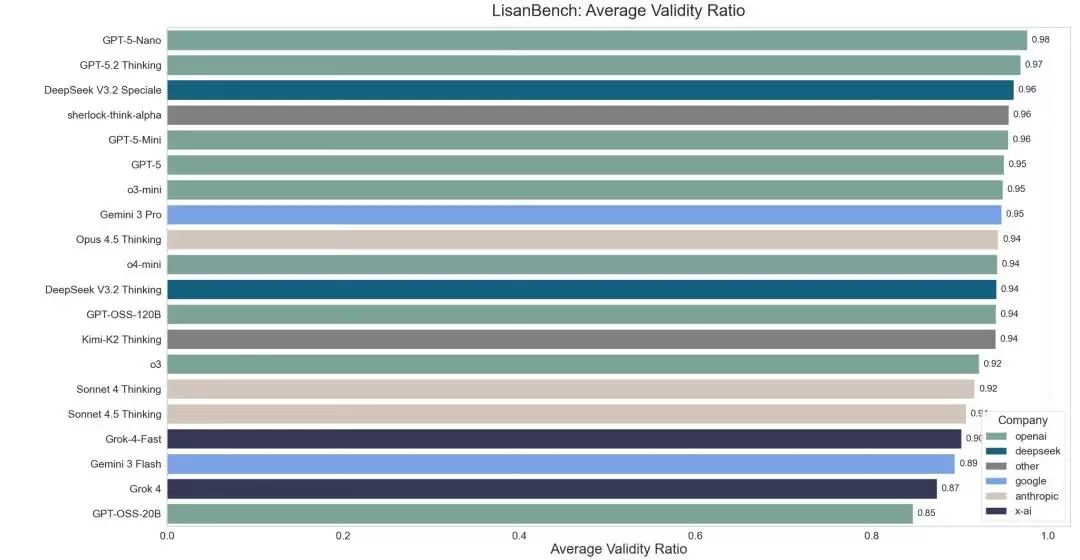
然而更值得关注的指标是平均有效性比率,它直接反映了模型在词汇链中生成错误链接或错误单词的概率。Gemini 3 Flash 在此项仅获得 87%,数据颇为刺目,也正好印证了此前高幻觉率的问题——并非偶然,而是系统性的短板。
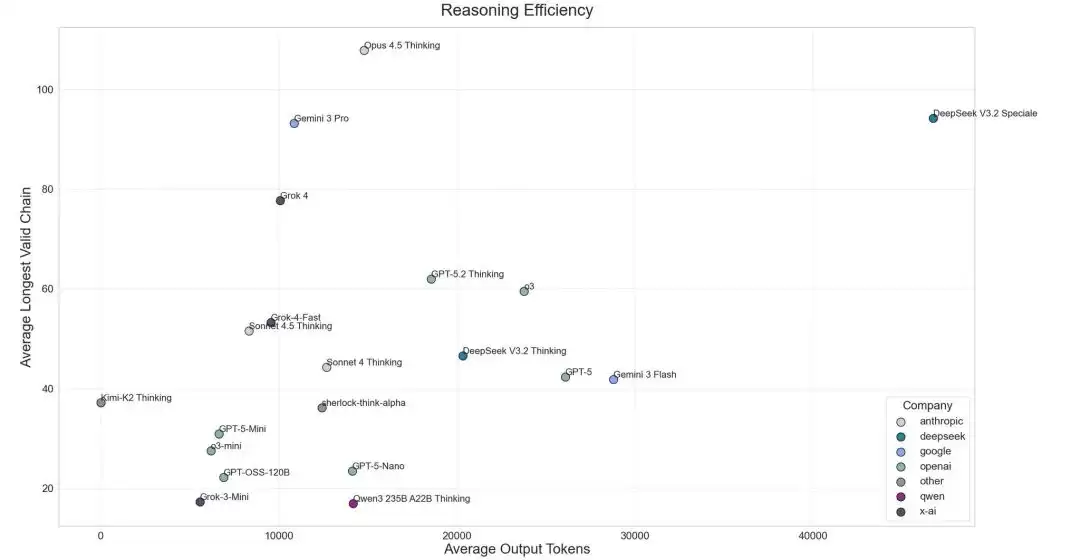
从推理效率图来看,Gemini 3 Flash 在平均输出 Token 数量与平均最长有效链长度之间的平衡并不理想。与开源替代品相比,性价比差距一目了然:Gemini 3 Flash 输入定价 0.5 美元、输出定价 3.00 美元,而 DeepSeek-V3.2 Thinking 仅需输入 0.28 美元、输出 0.42 美元——后者不仅得分更高、价格更实惠,而且使用的 Token 数更少。如果切换至低资源设置,Gemini 3 Flash 的低配版表现更为惨淡:得分大约只有高配版的一半,Token 用量同样减半,有效性比率更是“极为糟糕”。
当前 AI 模型竞争白热化,Gemini 3 Flash 的表现再次引发了一个老生常谈的问题:模型能力之间的平衡究竟该如何取舍?当年 DeepSeek R1 推出时也曾面临类似的争议。高幻觉率绝非小事——虽然有人可能将其视为“创造力”的体现,但在实际落地场景中,不准确性可能直接导致严重后果。归根结底,稳定性和准确性才是衡量模型质量的核心标尺。




