 GLM-4.7 官方基准测试详情
GLM-4.7 官方基准测试详情
经过多日市场预热,12月22日,智谱AI正式发布了新一代旗舰模型GLM-4.7。此次升级在编程能力和复杂推理能力上取得了重大突破,性能直接对标当前顶尖的闭源模型。消息公布后,迅速引发行业高度关注。
基准测试表现突出
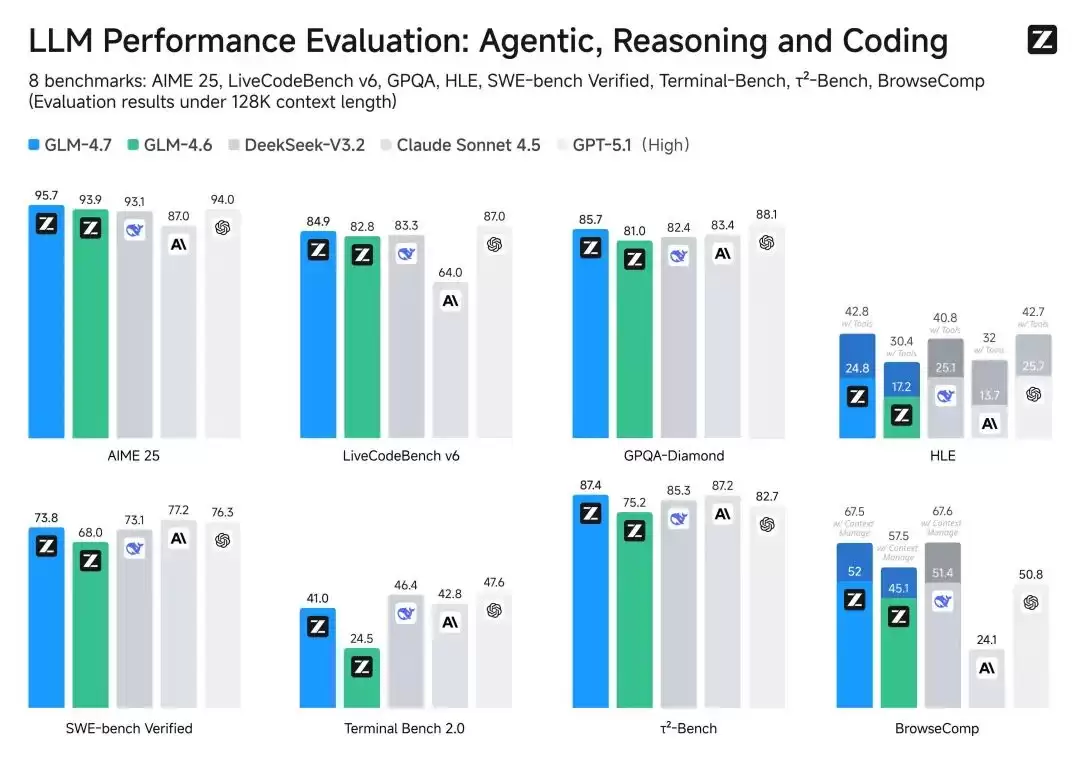
据Z.ai团队披露,GLM-4.7在编程、复杂推理及工具使用等核心能力上均有显著提升,同时在聊天、创意写作和角色扮演场景下的表现也进一步增强。具体来看,多项关键基准测试的结果十分亮眼:
- LMArena代码竞技场(盲测):在开源模型中排名第一,成功超越GPT-5.2
- LiveCodeBench V6:得分84.8,超过Claude 4.5 Sonnet
- AIME 2025(数学):表现优于Claude 4.5 Sonnet和GPT-5.1
- 人类终极考试(HLE):得分42%,相较GLM-4.6提升38%,逼近GPT-5.1水平
- τ²-Bench:在真实世界交互测试中与Claude 4.5 Sonnet持平
 LM Arena 代码竞技场盲测结果
LM Arena 代码竞技场盲测结果
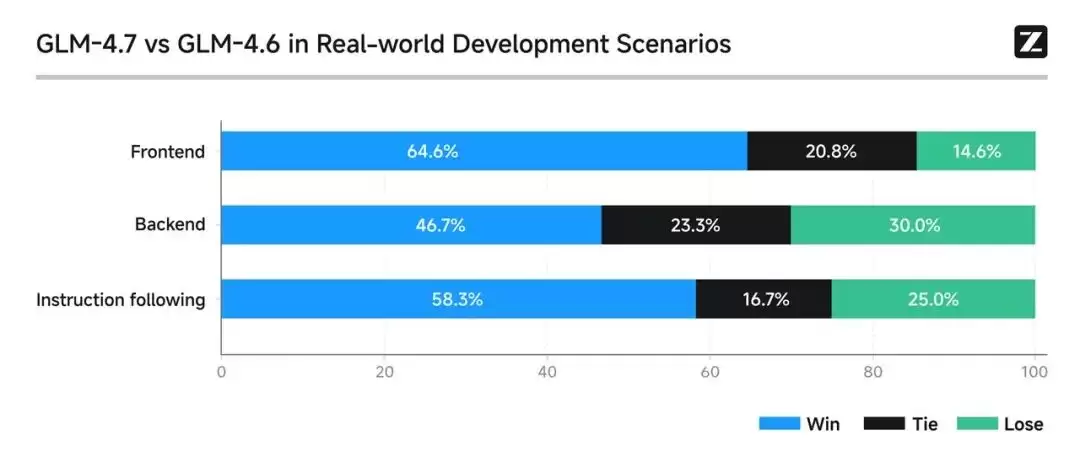
在实际开发场景的对比测试中,GLM-4.7在前端任务上以64.6%的胜率领先GLM-4.6,后端任务胜率为46.7%,指令遵循任务胜率为58.3%。这一数据分布表明,新模型在前端交互和指令理解方面进行了最大力度的优化。
技术规格与核心特性
GLM-4.7支持200K上下文窗口,最大输出可达128K tokens,处理速度约为每秒55 tokens。同时,模型进一步优化了交织思维模式,引入了保留思维和回合级思维机制——简单来说,即在执行动作之间进行思考,并保持跨回合的一致性,从而让复杂任务的执行更加稳定、可控。
定价与订阅策略
GLM-4.7已成为GLM Coding Plan的默认模型。该计划提供多种订阅选项,起价为每月3美元,兼容Claude Code、Cursor等十余种编程工具。对开发者而言,这一门槛相对较低。
总结
基准测试数据确实引人注目,部分内测用户反馈,实际编程能力有大幅提升,甚至有人觉得这可能是又一个“deepseek时刻”。不过,也有早期用户的实际测试反馈相对保守——有用户表示,在有限的测试中,GLM-4.7的表现并未明显优于Claude 4.5 Sonnet或GPT-5.2,甚至可能不及Minimax M2.1。客观而言,测试场景和任务类型对结果影响很大,具体表现仍需更多用户实际使用后才能得出结论。
智谱近期密集发布新模型,有用户调侃“GLM-4.6还没熟悉,4.7就来了”。这背后或许与智谱冲刺“中国大模型第一股”的战略有关——智谱AI刚刚宣布将于明年1月在香港进行IPO。值得注意的是,minimax也传出了在港股上市的消息。相比之下,minimax业务更为多元,海外市场影响力更强,拥有超过2.12亿个人用户,覆盖200多个国家和地区,海外市场贡献了超过70%的收入。从这个角度看,智谱加速迭代、频繁动作,显然是在为提升国际影响力铺路。




