 Claude Opus 4.7 封面图展示
Claude Opus 4.7 封面图展示
Anthropic 再次发布重磅更新——Claude Opus 4.7 正式亮相,号称迄今为止最强大的 AI 模型。与上一代 Opus 4.6 相比,本次升级的核心关键词是“严谨”与“可靠”。长任务处理更加稳定,指令执行更为精准,而且模型在输出反馈前会自动进行自我检查。简单来说,你可以更放心地将那些复杂且需要持续监控的任务交给它,节省大量精力。
核心能力大幅升级
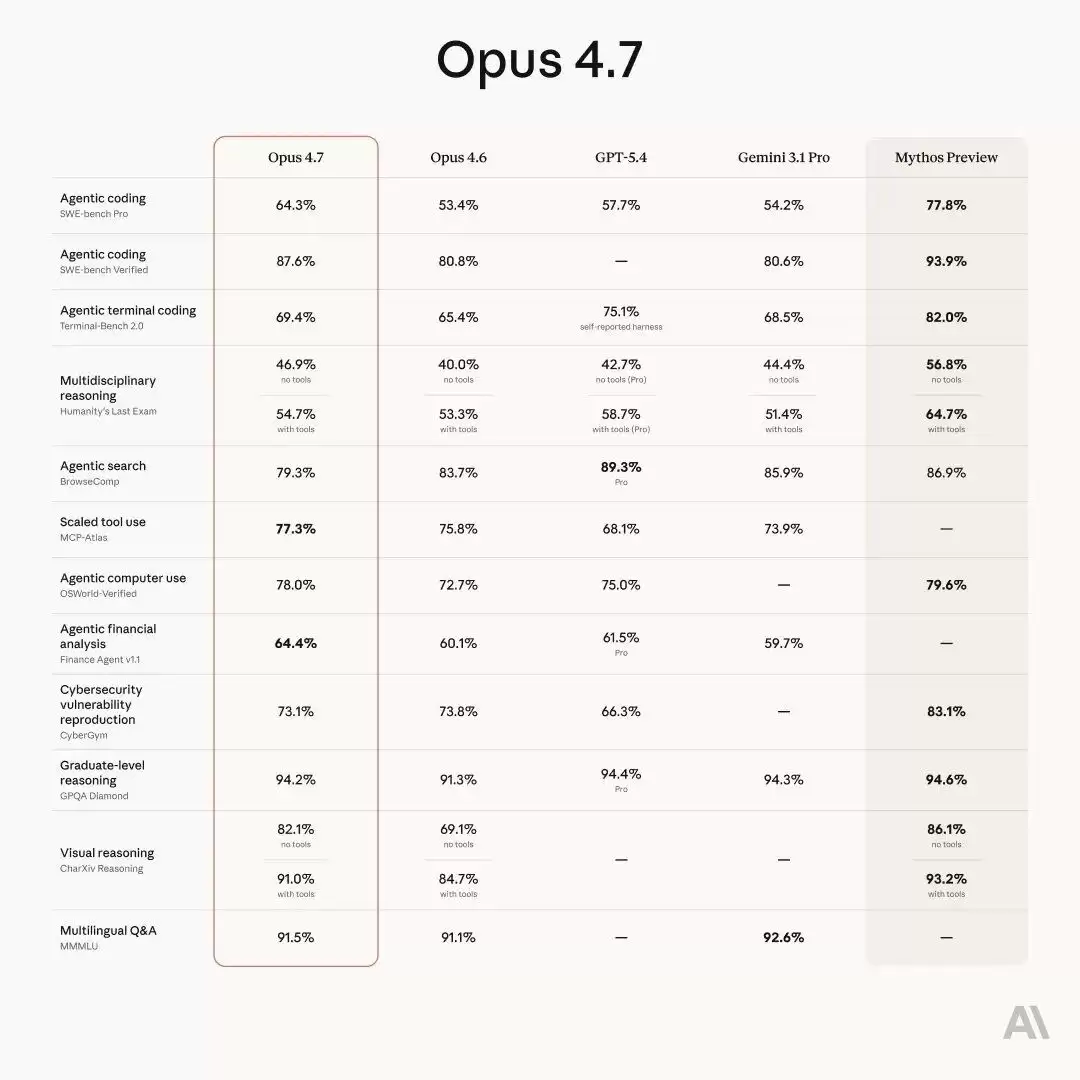
长任务严谨性:Opus 4.7 在复杂且长时间运行的任务中保持了高度一致性。早期测试者反馈,一些此前需要紧盯的棘手编码工作,现在模型能够独立完成。值得关注的是,该模型在计划阶段就能识别自身逻辑错误并加速执行,相当于边工作边自我检查,从而显著提升效率。
视觉能力突破:支持更高分辨率图像,长边最高达 2576 像素(约 375 万像素),是此前 Claude 模型的 3 倍以上。这意味着读取密集截图、从复杂图表中提取数据等此前效果不佳的应用场景,如今具备了实际可行能力。
指令遵循精度:Opus 4.7 对指令细节把控极为严格。一个副作用是:以前为旧模型编写的提示词可能需要重新调整。实际使用中,它会与你展开技术讨论,帮助做出更稳妥的决策,而非简单盲从。
记忆能力提升:Opus 4.7 更擅长利用文件系统级别的记忆功能。在跨会话、跨任务的长线工作中,它能记住重要备忘录,切换新任务时也可减少重新说明前情提要的负担。
企业级应用实测表现
根据 28 家企业的实地反馈,Opus 4.7 在多个领域拿出了扎实数据:
Hex:低努力级别的 Opus 4.7 性能大致相当于中等努力级别的 Opus 4.6,意味着只需更少算力就能达到之前的中档效果。
Cursor:在 CursorBench 上通过率达到 70%,较 Opus 4.6 的 58% 提升明显。
CodeRabbit:代码审查召回率提升超过 10%,尤其在复杂 Pull Request 中能挖掘出最隐蔽的 Bug。
XBOW:视觉识别准确率从 54.5% 跃升至 98.5%,这一巨大提升几乎解锁了此前无法使用的场景。
新增功能
xhigh 努力级别:在 high 和 max 之间新增一个高努力档位,为棘手问题提供更精细的推理延迟权衡控制。当需要更多思考时间时,可选择此档位。
/ultrareview 命令:专门用于代码审查的会话模式,可标记出审阅者特别关注的问题。Pro 和 Max 用户可免费试用 3 次。
自动模式扩展:为 Max 用户扩展自动模式,减少长任务运行过程中的中断次数。
安全特性
作为 Project Glasswing 计划的一部分,Opus 4.7 的网络安全能力被有意限制,并内置了自动检测和阻止高风险网络安全请求的防护机制。安全专业人员可通过新的网络安全验证计划申请合法用途。
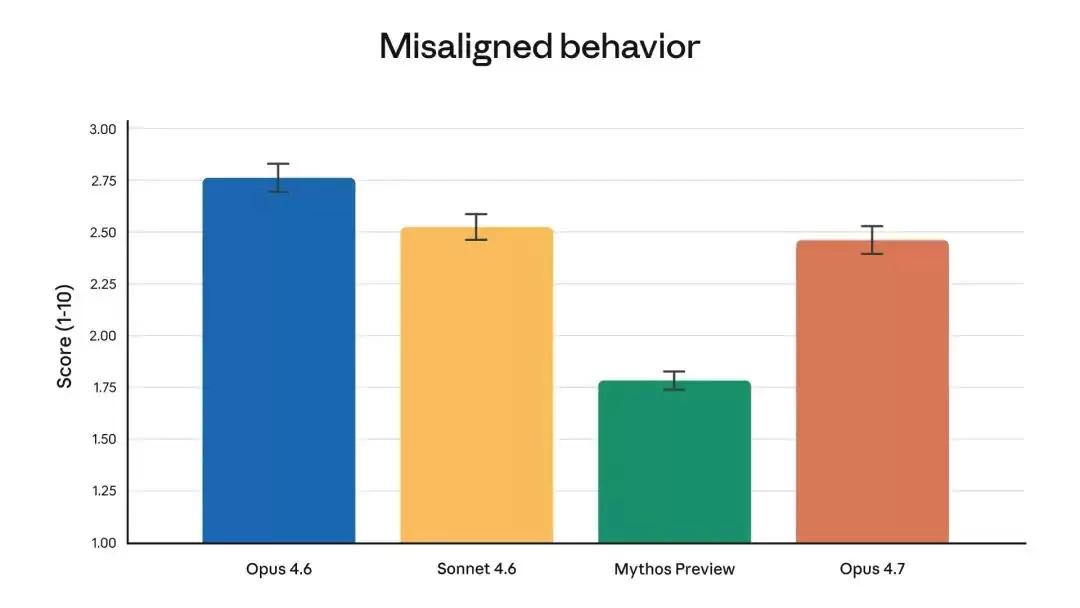 安全性能对比示意图
安全性能对比示意图
技术迁移注意事项
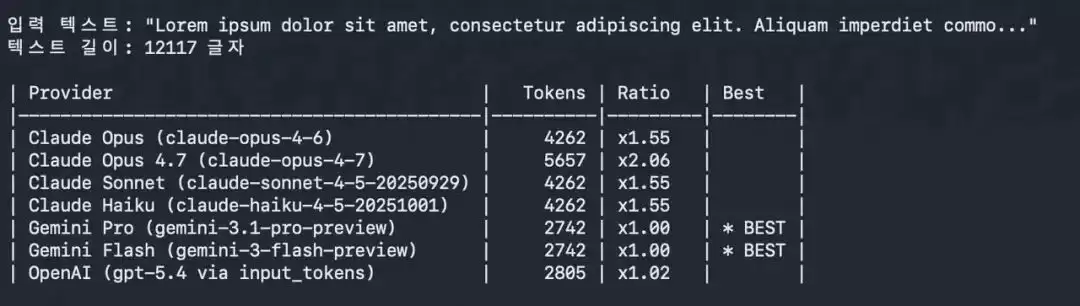
分词器更新:Opus 4.7 采用全新分词器,相同输入可能映射更多 token(约 1.0-1.35 倍,依内容类型而异)。测试数据很直观:处理相同内容时,Opus 4.7 消耗 5657 个 token,较 4.6 版本的 4262 个高出 33%,相比 Gemini Pro 的 2742 个则多出 106%。因此,尽管定价未变,但同等任务需消耗更多 token,实际成本有所上升。
思考深度增加:在更高努力级别下(尤其是会话设置中靠后的回合),模型会进行更多思考,可靠性提升,但也意味着产生更多输出 token。
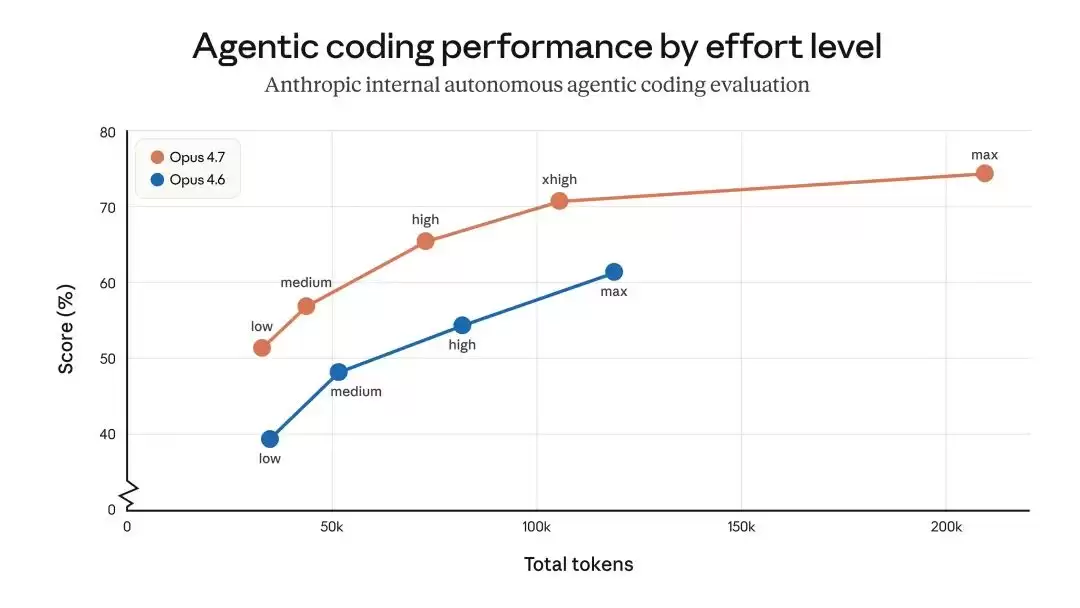 Token 效率对比数据
Token 效率对比数据
实际应用案例
Rust 语音引擎:Opus 4.7 自主构建了完整的 Rust 文本转语音引擎,涵盖神经网络模型、SIMD 内核和浏览器演示,并通过语音识别器验证输出与 Python 参考的匹配度。整个过程完全由模型独立完成。
企业文档分析:在 Databricks 的 OfficeQA Pro 评估中,使用源信息时的错误率较 Opus 4.6 降低 21%。
终端操作:通过 Terminal Bench 任务,成功处理了 Opus 4.6 无法解决的并发 Bug,新模型攻克了这一难题。
定价和可用性
Opus 4.7 现已通过 Claude 官网、Claude 平台及所有主流云平台提供。定价与 Opus 4.6 保持一致:输入 token 每百万 5 美元,输出 token 每百万 25 美元。开发人员可通过 Claude API 调用 claude-opus-4-7 模型。




