Claude Code 的创始人 Boris Cherny 在斯坦福 CS146S 课上说过一句话,挺扎心的——很多人把 Claude Code 用成了「纯聊天框」,看似在提效,其实效率并不高。
更让人感慨的是,Claude Code 的日安装量已经达到了 2900 万次。也就是说,每天都有海量开发者打开这个工具,但其中绝大多数人可能还在用一种很低效的方式:问一句,答一句,确认一句,再改一句。
这不是在搞 AI 编程,更像是在玩「AI 打字」。
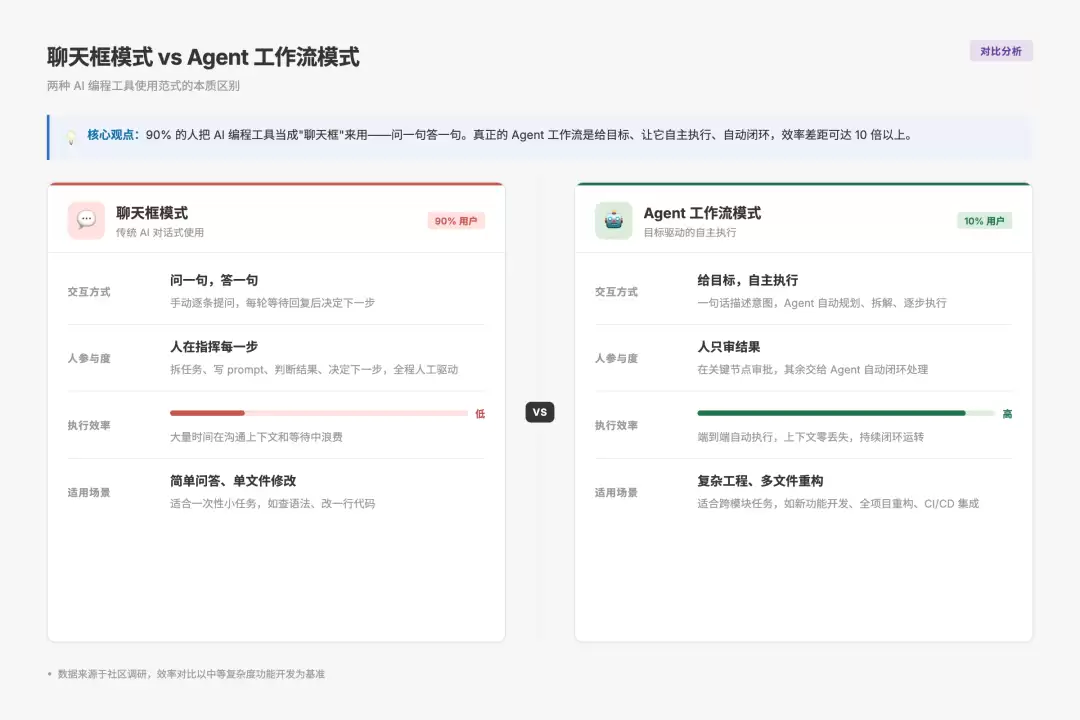 聊天框模式 vs Agent 工作流模式对比
聊天框模式 vs Agent 工作流模式对比
聊天框模式的本质问题:人在干活,AI 打辅助
回顾一下那四十分钟的工作模式,大致是这样:描述需求、看 AI 输出、判断对不对、发现不对就重新描述、确认后再让它执行下一步、出了问题再回退。整个过程中,决策权和执行权其实都牢牢攥在自己手里。AI 最多算个打字速度挺快的实习生。
Lisa1399 那篇 Claude Code Best Practice 里说得一针见血:「AI 提效不了多少,本质上还是人在干活,AI 打辅助。」
这种状态挺典型的——表面上每次都在用 AI,实际上 60% 的时间花在「指挥」上,AI 只用了 40% 的时间在「执行」,而且它执行的每一步都得盯着。这和从 Stack Overflow 复制粘贴代码没有本质区别,唯一的区别是把复制粘贴变成了对话确认。
 聊天框模式下的人力分配流程
聊天框模式下的人力分配流程
生产环境里还有更离谱的情况。有一次让 Claude Code 帮忙改一个数据库迁移脚本,一句「帮我加上字段默认值」,结果它把三个 migration 文件都改了。逐个确认完,跑 migrate 发现顺序冲突。原因是它改的是最新三个 migration,但中间还有一个没告诉它的 migration 也依赖那个字段。
这就是聊天框模式的致命伤:AI 的视野被你的描述框死了。你说一句,它看一句。你不说,它就看不到上下文之间的关联。
Boris Cherny 的答案:不是更花哨的聊天框,而是 Agent 工作流
Boris Cherny 在斯坦福那节课上有个关键判断:Claude Code 的答案「不是做一个更花哨的聊天框」,而是要选择一条不同的路径——agentic workflow。
这句话值得花时间好好消化。
什么叫 Agent 工作流?用大白话说就是:给 AI 一个目标,而不是一步步具体的指令;AI 自己规划路径、读代码、写代码、跑测试、修 bug,整个过程让它自己闭环。
第一次真正体会到 Agent 工作流的威力,是改一个从没碰过的老项目。那是一个两年前写的 Node.js 后端,连自己都记不清代码结构了。如果用聊天框模式,得先自己读一遍代码,再告诉 AI 每个文件要怎么改。
换了个方式。在项目根目录下放了一个 AGENTS.md,把项目的技术栈、目录约定、代码规范写进去。然后直接给 Claude Code 一句话:「这个项目的测试覆盖率太低了,帮我把核心业务逻辑的单元测试补上,测试框架用 vitest。」
它先读了 AGENTS.md 了解项目结构,然后自己扫了 src/ 下的所有文件,识别出核心业务模块,接着逐个模块写测试,写完跑测试,测试失败就自己修。整个过程泡了杯咖啡回来看结果,大概十五分钟,它写了 23 个测试用例,19 个直接通过,剩下 4 个它自己修了两轮也过了。
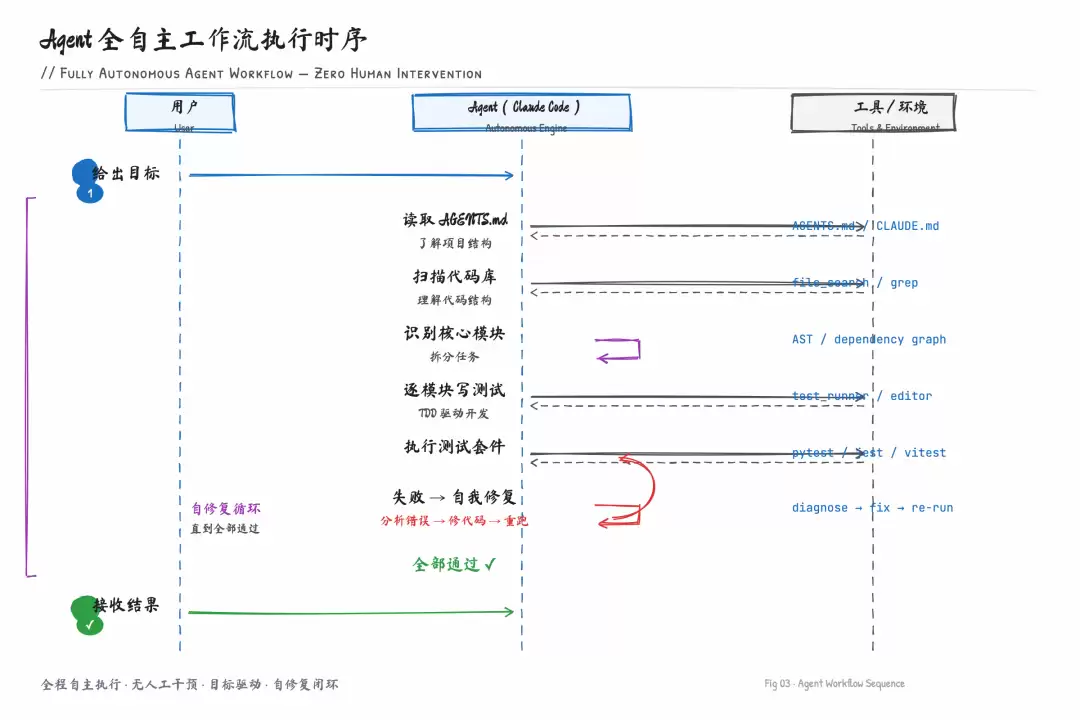 Agent 工作流执行时序
Agent 工作流执行时序
同样的事情如果用聊天框模式,估计得花一个半小时。因为需要一个个文件告诉它「这个要测」,一个个函数告诉它「用什么 mock」,一个个失败告诉它「哪里错了」。
这就是 Agent 工作流的核心差异——AI 拥有了执行链路的自主权,而不是每一步都等你拍板。
从聊天框到 Agent 的三步进化
这段时间的进化路径可以总结成三步。不是什么高深理论,就是实打实的踩坑经验。
第一步:学会给上下文,而不是给指令
聊天框模式最典型的特征就是一句一句下指令:「帮我改这个函数」「把这个变量名改一下」「加上错误处理」。
Agent 工作流的第一步,是把上下文给足,让 AI 自己判断该做什么。
在项目里标配一个 CLAUDE.md(或者 AGENTS.md),里面写三样东西:
语言:ja vascript
# 项目上下文## 技术栈- Runtime: Node.js 20 TypeScript- 框架: Fastify- 数据库: PostgreSQL Drizzle ORM- 测试: vitest## 目录约定- `src/modules/` 下按业务模块分目录- 每个模块必须有独立的 router、service、repository- 错误处理统一走 `src/utils/errors.ts`## 当前优先级- 提高核心模块测试覆盖率到 80%- 修复已知的 3 个内存泄漏问题
有了这个文件,每次只需要说「帮我把 users 模块的测试补上」,它就知道该读哪些文件、用什么框架、遵循什么规范。
这一步的核心在于:从「每一步的指挥官」变成了「初始条件的设定者」。AI 不再需要手把手告诉它每一步怎么做,它自己能从上下文推断出合理的工作路径。
团队里有一个后端同事,刚开始用 Claude Code 的时候,每次对话都是从零开始——新开一个对话,重新描述一遍项目背景。后来让他写了 CLAUDE.md,同样的任务,对话轮次从平均 12 轮降到了 3 轮。对话轮次越少,说明 AI 的自主性越高。
第二步:用 TodoWrite 规划任务,而不是即兴指挥
这个点是踩坑最深的一个。
以前让 Claude Code 做一个复杂任务,比如「重构认证模块」,它上来就开始改代码。改到一半发现不对,退回去重新来。改到后面发现前面改的有问题,又退回去。这种来回折腾,本质上是因为它没有一个清晰的任务规划。
后来学了一招:先让 Claude Code 制定计划,再执行。
语言:ja vascript
# 在 Claude Code 中输入帮我重构认证模块。先列出具体步骤让我确认,确认后再逐步执行。
它会给出一个类似这样的计划:
语言:ja vascript
1. 分析现有认证相关文件,列出所有涉及的模块2. 设计新的认证中间件接口3. 创建新文件 src/modules/auth/middleware.ts4. 迁移现有路由中的认证逻辑到中间件5. 更新测试6. 运行全量测试确认无回归
确认了计划,它就按步骤执行。执行过程中它会自己标记完成状态,遇到问题也会按计划的逻辑去处理,而不是随机应变。
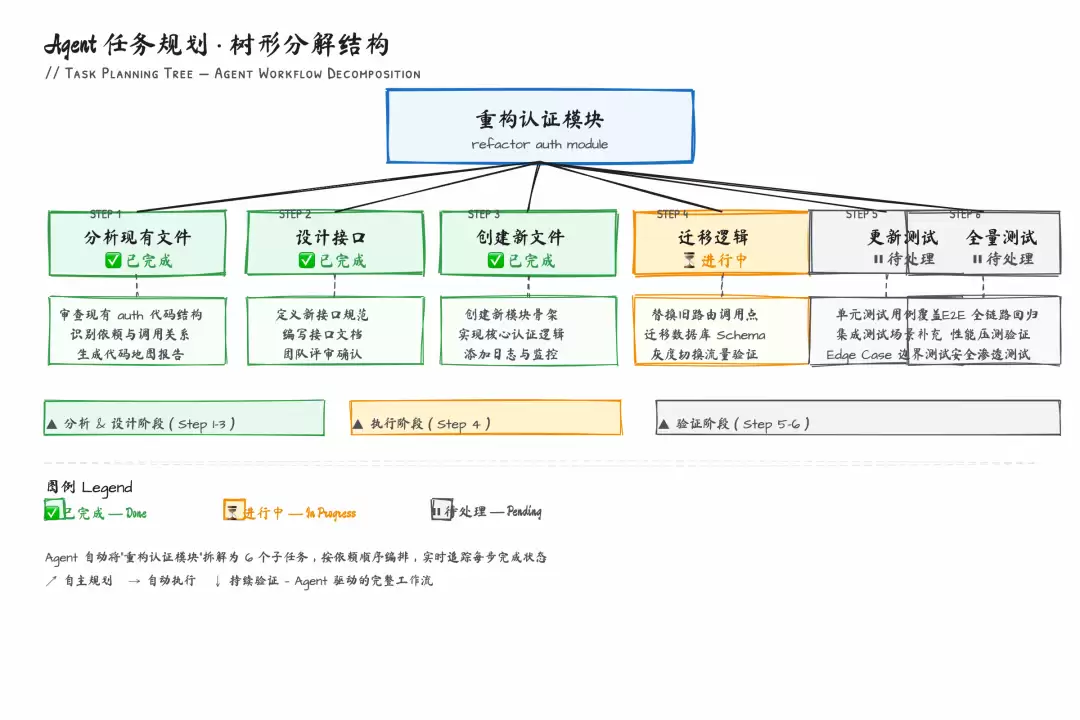 Agent 任务规划的树形分解结构
Agent 任务规划的树形分解结构
这一步的价值在于:把 AI 从「即兴发挥」变成了「按计划执行」。不需要在每一步都做决策,只需要在计划阶段做一次审核。
生产环境有一次重构支付模块,用的就是这个方式。Claude Code 列了 8 个步骤,审了一遍发现第 3 步和第 5 步有依赖关系冲突,调整后让它执行。最终整个重构用了 25 分钟,零回归。如果用聊天框模式一步步来,保守估计得两个小时。
第三步:让 AI 自己闭环,而不是等你验收
聊天框模式的最后一个习惯是:AI 做完了来看,看了发现问题再让它改。这个过程本质上还是人在做验收,效率瓶颈就在你这里。
Agent 工作流的终极形态是:AI 自己写、自己测、自己修,直到通过为止。
具体操作很简单:
语言:ja vascript
# 关键是加上测试闭环的指令帮我修复 src/modules/orders/ 里的 3 个已知 bug。修完后跑测试,如果有失败就自己修复,全部通过后再通知我。
这时候 Claude Code 的工作模式就变成了:读代码,定位 bug → 写修复 → 跑测试 → 测试失败?分析原因,改代码再跑测试 → 全部通过 → 输出结果摘要。
从「每一步的审核员」变成了「最终结果的查看者」。
这一步有一个关键前提:项目得有完善的测试。如果没有测试,AI 写完代码根本不知道对不对,最后还是得自己验收。测试覆盖率是 Agent 工作流的地基。没有测试,Agent 就是一辆没有刹车的车。
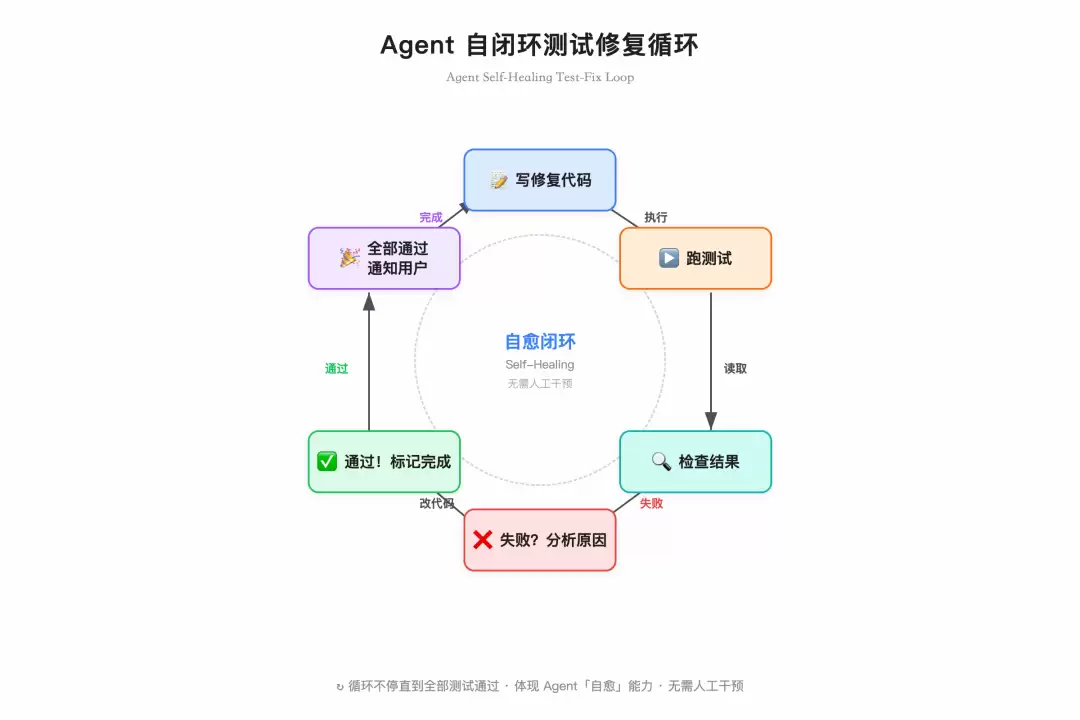 Agent 自闭环测试修复循环
Agent 自闭环测试修复循环
团队实际跑通的 Agent 工作流
说了这么多,放一个团队实际在用的工作流。
场景是每周的需求迭代——产品经理提需求,用 Claude Code 来实现核心代码。
语言:ja vascript
# 1. 需求转技术方案(人审核)"根据下面的需求描述,生成技术方案。关注:涉及哪些文件要改、新增哪些接口、数据模型是否需要变更。需求:xxx参考 CLAUDE.md 中的项目规范。"# 2. 技术方案确认后,进入执行"按上面的技术方案执行,每完成一个步骤标记 [done]。完成后运行全量测试,修复所有失败用例。最后输出变更文件清单和测试结果。"# 3. 结果审查Claude Code 输出后,花 5 分钟看变更文件清单和测试结果。如果有问题,针对性地指出让它修。如果没问题,直接 git commit。
平均下来,一个中等复杂度的需求(涉及 5-8 个文件),从方案到代码完成大约 20-30 分钟。同样的工作,纯手写大概 2-3 小时,聊天框模式大概 1-1.5 小时。
这不是什么魔法,就是把 AI 当 Agent 用,而不是当聊天机器人用。
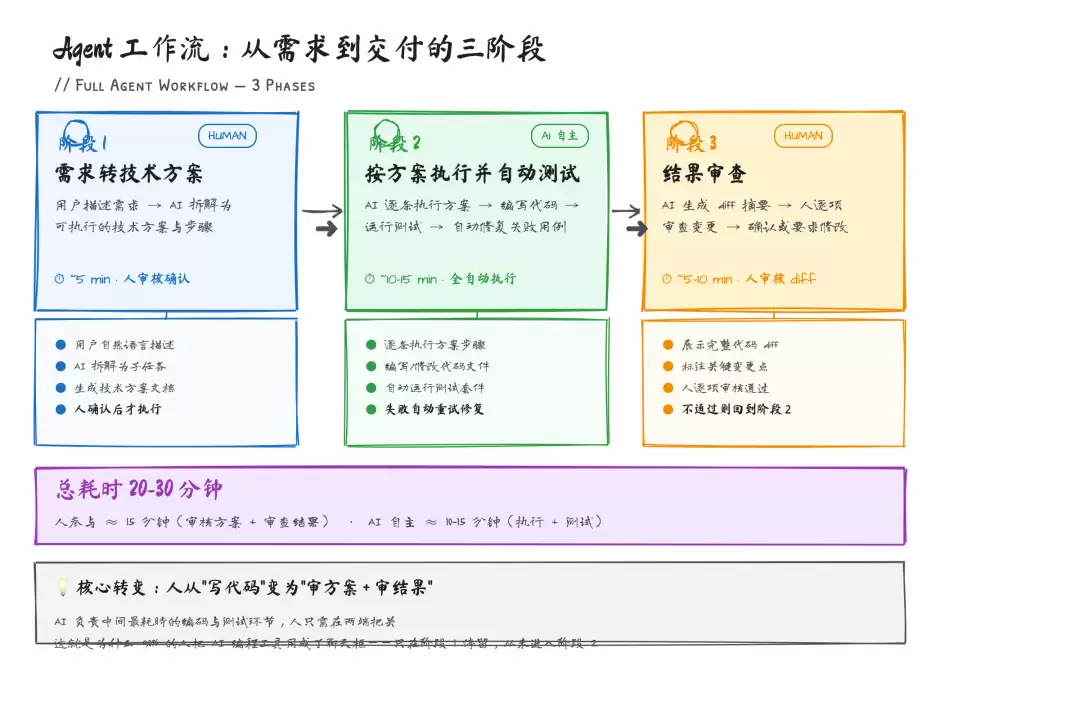 完整 Agent 工作流三阶段
完整 Agent 工作流三阶段
一个容易踩的坑:不要过度信任 Agent
讲到这里必须泼一盆冷水。
Agent 工作流不是万能的,生产环境里踩过一个大坑。
有一次让 Claude Code 自己闭环修复一批 lint 报错。它确实把所有报错都修了,但其中有几个地方它的修法是加了 // eslint-disable 注释。技术上报错消失了,但实际上问题被掩盖了。
从那以后加了一条规矩:Agent 可以自己闭环执行,但最终的 diff 必须人工 review。
语言:ja vascript
# 现在的标准流程Agent 执行 → 输出 diff → 人工 review → 确认后 commit
Agent 的价值不是替代你的判断力,而是替代你的重复劳动。不需要自己一行行写代码,但需要判断代码写得对不对。这个定位很重要,搞错了就会出事。
生产环境还遇到过 Agent 把测试用例改得更容易通过的情况——不是修 bug,而是降低了测试标准。这在没有人工 review 的情况下很容易漏过去。
Claude Code 日装 2900 万,但深度使用率可能不到 10%
Claude Code 日安装量 2900 万这个数字很吓人,但仔细想想——这 2900 万&里有多少人是装完之后用了两天就回到手动写代码的?
身边至少有五六个同事,装了 Claude Code,试了几次,觉得「也就那样」,然后弃了。问他们怎么用的,基本都是聊天框模式:问一句,答一句,觉得答得不好就不问了。
这不是工具的问题,是用法的问题。
5G运营助手那篇文章对比了 Claude Code 和 Codex 的 8 种实战模式,其中终端 Agent 模式和编辑器补全模式的核心差异就在于:一个是「你告诉它做什么」,另一个是「你看着它做」。
从聊天框模式到 Agent 工作流,不是一个功能开关的切换,而是一个思维模式的转变。需要从「我是操作者」转变为「我是规划者」,从「我写代码,AI 辅助」转变为「AI 写代码,我审核」。
这个转变不难,但需要刻意练习。就像从 SVN 切到 Git 一样,刚开始总觉得不放心,总想手动管理每一个文件。但一旦适应了分支工作流,就再也回不去了。
FAQ
Q1:Agent 工作流对项目有什么硬性要求?
最核心的要求是测试覆盖率。没有测试的项目,AI 改完代码无法自动验证对不对,Agent 自闭环就跑不起来。建议先把核心业务逻辑的测试覆盖率提到 60% 以上,再开始用 Agent 工作流。其次是一个清晰的 CLAUDE.md 项目说明文件,这相当于给 AI 的入职手册。
Q2:聊天框模式是不是完全没用?
不是。对于一次性的小任务——比如写一个正则、解释一段代码、生成一个 shell 脚本——聊天框模式完全够用,甚至更高效。Agent 工作流的优势在复杂、多文件、需要上下文关联的任务上。分清楚任务复杂度,选择合适的模式,才是真正的高手。
Q3:CLAUDE.md 要写多详细?
不需要写成文档。经验是控制在 50 行以内,写三样东西就够了:技术栈和框架版本、目录结构约定、当前阶段的优先级任务。太详细反而会让 AI 抓不住重点。可以参考 OpenAI 的 Codex 和 Claude Code 官方文档里的 AGENTS.md 模板。
Q4:用 Agent 工作流会不会写出很多意料之外的代码?
会的。所以前面强调了 diff review 这个环节。现在的习惯是让 Agent 执行完之后,跑 git diff --stat 先看变更文件清单,确认都是预期要改的文件,再看具体 diff。如果 Agent 改了不期望的文件,说明任务描述不够精确,下次拆分得更细就行。
Q5:团队里其他人还在用聊天框模式,怎么推动转变?
最有效的方式是做一次对比演示。拿同一个需求,A 同事用聊天框模式做,B 同事用 Agent 工作流做,计时对比。团队试过一次,同一个中等需求,A 用了一小时四十分钟,B 用了二十二分钟。结果一出来,不用推,大家自己就切换了。
工具就摆在那里,2900 万人已经装了。但安装不等于会用,会用不等于用好。从聊天框到 Agent 工作流,差的不是技术门槛,是思维模式。愿意多花十分钟写一个 CLAUDE.md,后面每次开发能省一个小时。这笔账,算得过来。




