不妨设想这样一个场景:让 M1 从零开始为你搭建一个测试打字速度的网页——在演示中,它清晰地设定了 WPM(每分钟字数)与准确率(Accuracy)两项指标,连上方文字也会随你的输入进程同步变色,细节处理相当到位。再比如,让 M1 制作一个可拖拽的便签墙,同样信手拈来。
这些演示传递着同一个信号:通用 agent 在产品化进程中那些关键能力——长上下文理解、智能体机制——恰恰是 M1 的核心优势所在。这条路径与 MiniMax 早年以产品起势的打法一脉相承。而这家公司近来在基础模型层面持续的激进探索,以 M1 的发布为节点,在当下大模型普遍技术突破放缓的背景下,展现出难得的发展后劲。
从 MoE 到 Linear,再到 MiniMax-M1
M1 的问世背后是一条清晰的演进脉络:从传统的稠密模型与 Transformer 架构,转向 MoE(混合专家)与线性注意力机制。当初 MiniMax 决定押注这两条路径时,几乎找不到可参考的先例。
2023 年底,Mistral AI 用开源模型 Mistral 8×7B 击败了当时最优秀的开源模型之一——700 亿参数的 Llama 2。而早在 2023 年夏天,MiniMax 就已开始筹备从稠密模型转向 MoE,投入了当时公司 80% 的算力与研发资源。在 Mistral 8×7B 发布一个月后,他们上线了国内首个 MoE 大模型 abab 6。由于架构过于新颖,团队还自研了更适配的训练和推理框架。
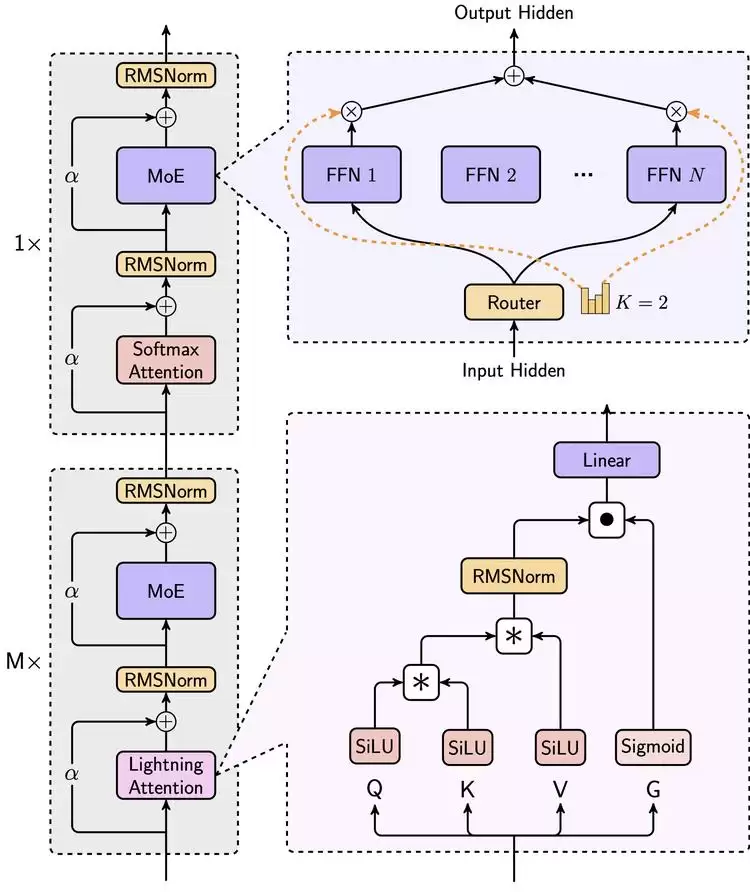
MoE 架构示意
M1 混合架构的另一块拼图——线性注意力(Linear Attention)——始于今年年初发布的 MiniMax-Text-01。MiniMax 从 2024 年 4 月开始投入线性注意力研究,当时还没有任何模型敢在千亿参数级别挑战传统的 Transformer。这迫使 MiniMax 对分布式训练和推理框架进行了彻底重设计,确保模型能在大规模 GPU 集群上高效运行。今年 1 月的 MiniMax-Text-01 成为首个依赖线性注意力机制大规模部署的模型,为整个行业从“小规模可行”的共识到“大规模规模化”的可行性完成了一次验证。而推理模型 M1,本质上就是基于 MiniMax-Text-01 的又一次升级与架构创新。
MiniMax 也公开了 M1 基于 MiniMax-Text-01 的训练细节:团队以 MiniMax-Text-01 为基座,进行了 7.5 万亿 token 的定向增强预训练,将 STEM(科学、技术、工程、数学)、编程代码与复杂推理三类核心领域的数据权重提升至总语料的 70%。随后通过监督微调注入链式思考(CoT)机制,系统性地构建模型的分步推理能力,为强化学习奠定基础。
这种激进式的创新最终收获了积极验证——M1 是目前全球最先达到 80k 上下文输出的推理模型,在长上下文处理、软件工程以及 Agent 工具使用方面均展现了明显优势。
此前,星野和 Talkie 在商业化上的优异表现,让 MiniMax 早早成为一家能够独立行走的大模型公司,外界也因此给它贴上了“产品驱动”的标签。这个说法虽然笼统,却在一定程度上掩盖了 MiniMax 在模型研发层面的强悍实力。值得注意的是,MiniMax 官方公告透露,M1 系列模型同时拉开了为期五天的 MiniMaxWeek 的序幕,接下来五天,公司会围绕文本、语音和视觉等多模态模型公布更多技术进展。
与此前 MoE 的 abab 6 模型刚出现时类似,此次发布的混合注意力机制 M1,在底层架构上依然是一个“非共识”的推理模型。但恰恰是这些屡次深入底层架构“无人区”的技术创新,一次次印证了 MiniMax 骨子里是一家“模型驱动”的 AI 公司——而这一点,早该成为一种共识。




