TraeSolo手搓古文教学系统搭建全攻略
时间:2026-06-23 15:34
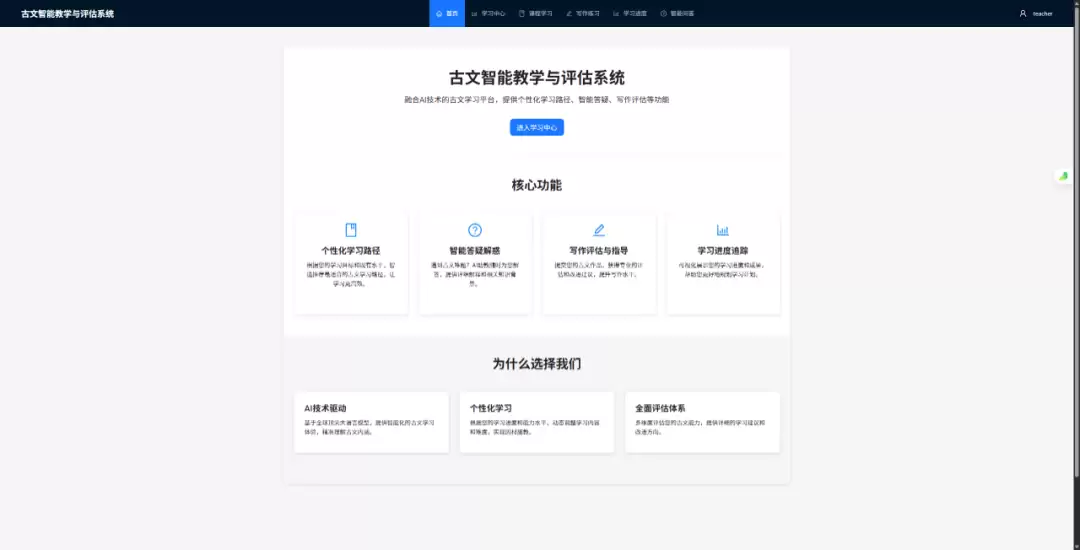
针对算法工程师面临的模型到产品工程落地难题,利用TraeSolo搭建古文智能教学系统。工具自动生成前后端分离架构、流式传输及容错解析代码,高效解决架构、流式响应与数据清洗等关键工程细节,两天内完成全栈项目交付。
日常工作中,算法工程师的阵地往往在数据、模型权重和训练管线之间。手里攥着一个调优过的模型,想把它变成用户能直接上手的产品,中间那堵“工程墙”——前端交互、后端并发、鉴权逻辑、数据库设计——总能把验证想法的热情浇灭大半。最近为了试水一个“AI 传统文化”的垂直场景,我需要搭一套“古文智能教学与评估系统”。核心逻辑倒不复杂:大模型做基座,上层做垂类应用。真正的难点在工程落地:得自己搞定 React 全家桶、Node.js 服务端以及 MongoDB 的数据流转。
为了不让这个项目烂在环境搭建这一步,我试着把工程实现全部丢给了 Trae Solo。
这篇内容不是软广,是一次严肃的开发效能复盘。从算法工程师的视角出发,聊聊 Trae Solo 是怎么帮我把“模型”到“产品”这最后一公里跑通的。
## 01 从 Model 到 Product:架构的“开箱即用”
项目启动时的第一个卡点,往往出在架构选型。
对习惯了写 Python 脚本或 C++ 的人来说,前端生态那套复杂的配置——Webpack/Vite、TypeScript Config、Redux Boilerplate——简直能把人逼疯。根本没心思研究 React 18 的最新目录规范,只想尽快看到界面。
在 Trae Solo 里,我直接输出了系统设计需求:“基于 React 和 Node.js,设计一个前后端分离的教学系统,需包含 JWT 鉴权和 MongoDB 连接池管理。”
它给出的不只是代码片段,而是一套符合工程最佳实践的脚手架。`Controller`、`Service`、`Model` 层划分得清清楚楚,前端的状态管理逻辑也清晰有序。这种代码结构的可维护性,比不少专职后端写的还规范。那一刻才意识到,它帮我省掉的不是打字时间,而是查文档和纠结架构的时间。
## 02 解决“最后一公里”:流式传输与异步处理
做大模型应用,最考验体验的莫过于流式响应。算法侧通常关注 TTFT 和推理速度,但到了 Web 端,就得处理 SSE 协议、二进制流的解码和 Markdown 的增量渲染。
如果手写这部分逻辑,至少得花半天翻 MDN 文档处理 `TextDecoder` 的边界情况。
把这个需求描述清楚后丢给 Trae Solo,它生成的代码非常老练:后端用 `res.write` 做分块传输,前端封装了一个健壮的 Hook 来处理流式读取,还自动加了网络异常中断后的重连机制。
代码跑通的那一刻,看着古文解析在屏幕上逐字跳动,没有任何卡顿和乱码。这种工程侧的“确定性”,让人非常安心。
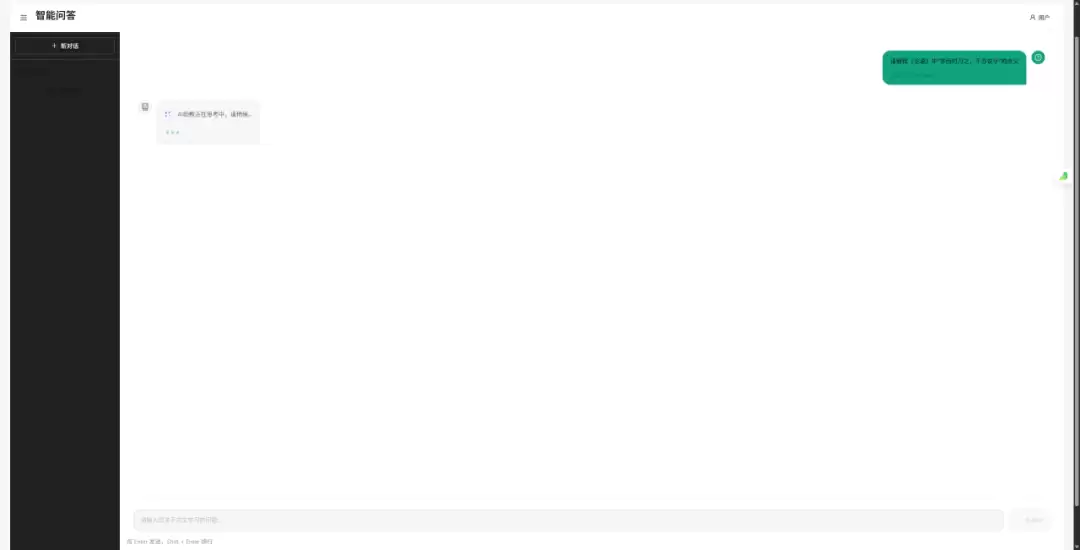
## 03 鲁棒性设计:非结构化数据的“清洗工”
这个系统最复杂的功能是“多维评估”——需要把学生的文言文发给模型,从准确性、文学性等维度打分。
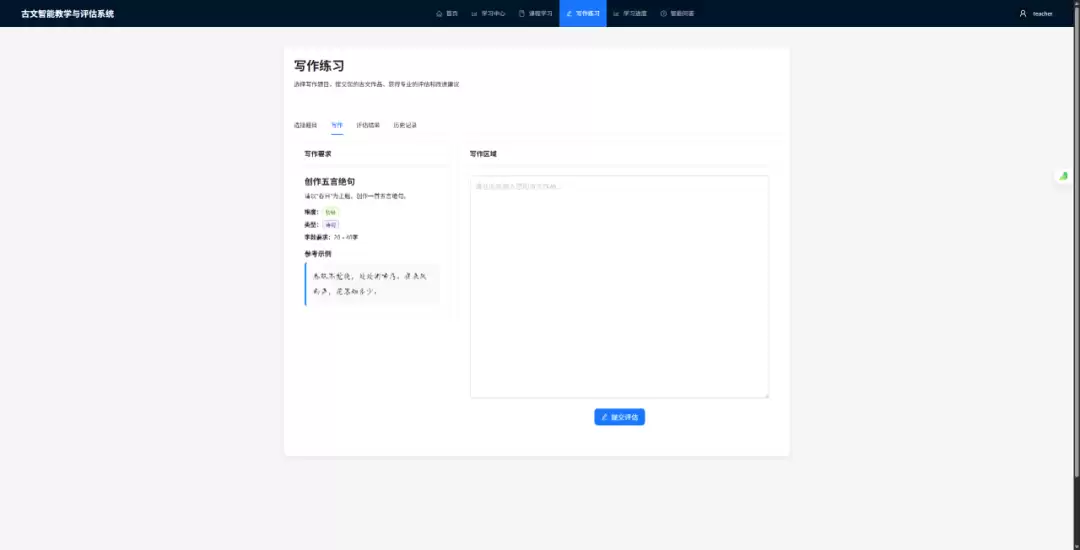
算法工程师都清楚,LLM 的输出在未加约束时存在不确定性。如何保证模型输出的 JSON 能被前端 Charts 稳定渲染,是工程上的一个硬骨头。
Trae Solo 在这里展现了它的价值。它不仅优化了 System Prompt,强制模型输出特定的 JSON Schema,还写了一套带容错机制的解析器。用正则匹配提取 JSON 块,包裹了完整的异常捕获逻辑。即使模型偶尔输出了一些“废话”前缀,后端也能精准提取有效数据,保证前端雷达图不崩。
这种对边界情况的处理能力,很多初级 Copilot 往往会忽略,但 Trae Solo 做得相当到位。
## 04 让专业的人做更专业的事
两天时间,这个全栈项目完成了从 0 到 1 的落地。
回顾整个过程,Trae Solo 并没有替代核心思考——业务逻辑的拆解、Prompt 的调优、评估指标的定义,依然由我主导。但它完美地承担了“全栈工程师”的角色,把那些不擅长且重复度极高的工程细节全部屏蔽掉了。
对于算法工程师来说,Trae Solo 就像一个不知疲倦、懂架构、代码风格严谨的工程搭子。它让我们不再局限于 Notebook 里的实验,有能力以极低的成本,把算法能力封装成高质量的软件产品。
如果你也想突破技术栈的边界,快速验证自己的算法 Idea,Trae Solo 值得加到工具链里试试。




