AI Agent的“记忆力”与“工具箱”
基于Manus,探讨AI Agent的上下文工程
AI Agent这个方向,最近可以说是热度很高。它不像传统的问答系统那样,你问一句它答一句。Agent的核心在于能自主思考、规划、执行,并且跟外部环境产生互动——听起来很酷,但真要落地到代码生成、科学研究、自动化办公这些场景里,光靠大语言模型本身的强大能力,其实是远远不够的。
这里有一个非常关键,但又经常被忽略的环节:上下文工程。
说白了,就是怎么高效管理和利用Agent在执行任务过程中产生的所有信息,包括用户说了什么、之前的对话记录、调用过哪些工具、环境给了什么反馈等等。上下文管得好不好,直接决定了Agent的智商、运行效率,以及你兜里的钱够不够烧。
接下来要讲的,是Manus团队在他们官方博客里分享的一些实战经验。这些策略是他们从零构建和优化AI Agent过程中,实打实踩坑踩出来的。我们一个个来看。
KV-Cache:“短期记忆”优化术
KV-Cache,听着像很底层的技术名词,其实就是大语言模型推理时的一个“速记本”。模型在处理文本的时候,会生成一些中间计算结果(键值对),KV-Cache把这些结果存下来。下次如果碰到语义上能匹配的前缀,直接复用就行,不用重新算一遍。
这就像你跟人连续聊天,不用每次开口都从自我介绍开始。在普通的聊天机器人场景里,用户输入和模型输出都比较短,这个优化效果不明显。但放到AI Agent身上,情况就完全不同了。
Agent干活,是一个“思考-行动-观察”不断循环的过程。每次循环都会往“记忆”里塞新东西,上下文越拉越长。Manus团队发现,Agent输入的内容和实际用来做决策输出的比例,最高能到100:1。在这种“长输入、短输出”的场景下,KV-Cache命中率直接决定了Agent反赌不快、花不花钱。
那么,怎么提高这个命中率?
首先,保持Prompt前缀的稳定性。大模型对上下文的微小变动极其敏感,哪怕一个字符变了,后面的缓存可能就都废了。比如,有人在系统Prompt里加了个精确到秒的时间戳,结果每次运行前缀都不一样,KV-Cache基本等于没用。
其次,只在末尾追加内容。要保证缓存有效,Agent的上下文就应该只允许在尾巴上追加新东西,不要从中间改或者插入。而且,数据在转成模型能读懂的格式时,内部的元素顺序也得固定住,不然有些编程语言在处理键值对时不保证顺序,缓存就莫名其妙失效了。
最后,必要时手动设置缓存断点。有些模型平台没那个自动增量缓存的功能,那就得自己动手,明确告诉系统“缓存到这里为止”。设置的时候,至少要把系统Prompt的结尾部分包含进去,同时别忘了考虑缓存失效的可能。
KV-Cache优化,看起来是模型推理层的技术细节,但实际上,这是Agent系统设计里成本与效率博弈的艺术。在多步推理的场景下,每一次命中都意味着实打实的算力节省和响应速度提升。
Mask, Don"t Remove
Agent能力越强,它手里的工具就越多。发邮件、查数据、浏览网页、写代码……工具箱里的家伙事儿,可能多达几百个。当用户还能自己往里面加工具时,“工具爆炸”的问题就来了——模型面对太多选择,反而容易犯懵,做出错误决策。Manus团队说得挺直接:过度武装的Agent,反而会变“钝”。
解决这个问题的直觉思路,是“动态工具箱”,也就是按需加载工具,有点像检索增强生成。但Manus的经验表明,除非万不得已,别在Agent干活的时候频繁地往里添工具或者往外拿工具。
为什么呢?一是动态增减会破坏KV-Cache。工具定义通常在上下文靠前的位置,一改就相当于改了前缀,缓存全废。二是模型会产生幻觉。假如Agent之前用过某个工具,但后来被移除了,它的“记忆”里还留着这个使用的记录,而模型又缺乏“约束解码”,就可能生成不合规的指令,开始满嘴跑火车。
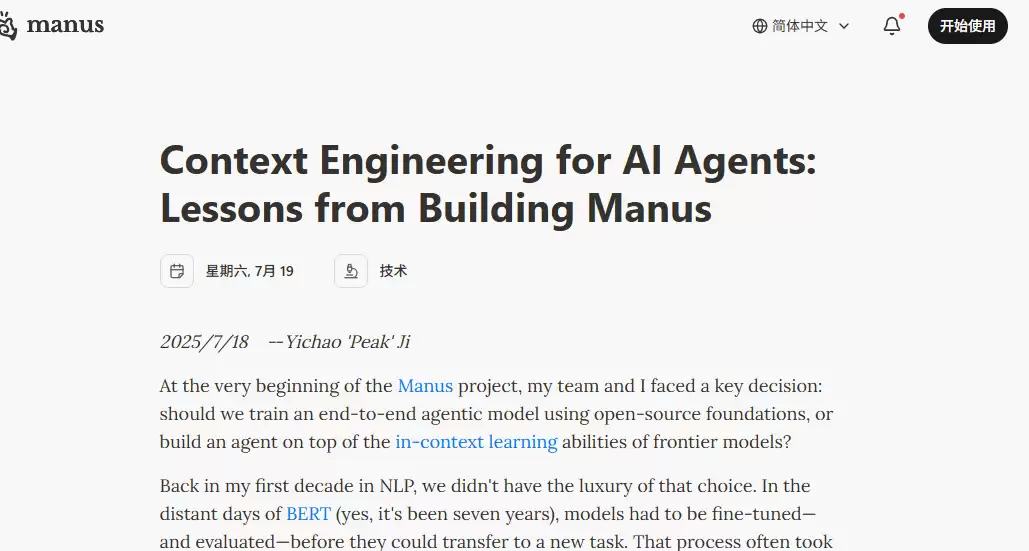
那怎么办?Manus团队用的是“掩码”策略——不是把工具移走,而是通过掩码Token logits的方式,让模型在“思考”阶段根本看不到那些不该用的工具,或者只能看到允许它用的工具。这有点像给工具箱加了一把无形的锁,你心里知道扳手在那个抽屉里,但锁上了就拿不出来。
实际操作中,很多模型服务商支持“响应预填充”功能,可以在不修改工具定义的前提下,限制Agent的行为。比如用户刚发出指令,Agent应该先回复一下,而不是直接上手调用工具。Manus还建议给工具命名时用统一前缀,像browser_给浏览器工具,shell_给命令行工具,这样在特定场景下,就能很方便地限制Agent只能在某一类工具里挑。
“掩码而非移除”,这个思路很巧妙。它保留了Agent的灵活性,同时用更优雅的方式维持了系统的稳定和可控。这提示我们,在设计Agent时,不能光盯着模型能力和工具数量,更要学会利用LLM自身的特性,用巧劲儿解决问题。
Use the File System as Context
现在大模型的上下文窗口虽然扩展到了128K甚至更大,但在AI Agent的实际工作中,这个容量往往还是个“甜蜜的负担”。信息过载会溢出,模型看太长的文本会“忘事”,而且哪怕有KV-Cache优化,传输和预填充大量Token的成本依然高得吓人。
很多系统为了应对这个,会直接截断或压缩上下文。但问题在于,过度或不可逆的压缩,可能会丢掉关键信息。Agent的每一步行动都依赖于所有历史状态,任何不可逆的信息损失都可能带来风险。
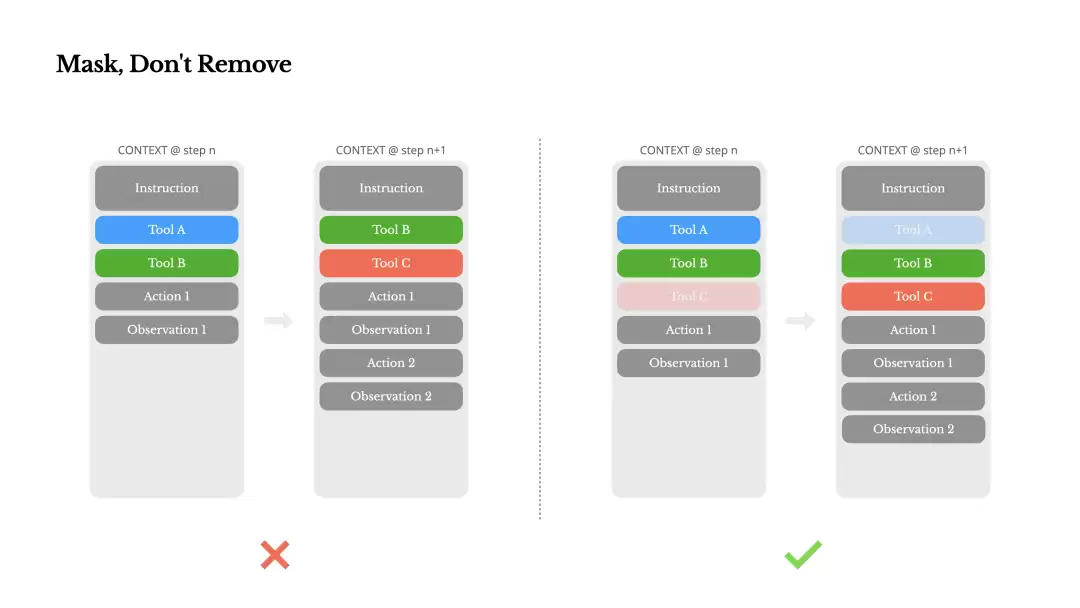
Manus提出了一个很创新的解决方案:把文件系统当成Agent的“终极上下文”。文件系统的容量几乎是无限的,还能持久化,Agent又能直接读写。通过让模型学会按需读写文件,文件系统就从一个普通的存储介质,变成了一个结构化、外部化的“记忆库”。这就像人类把大量知识存在书本、电脑和互联网里,要用的时候再去查。
Manus的上下文压缩策略是可恢复的。比如网页内容可能暂时从上下文里移除,但它的URL会被记下来;文档内容不直接放进去,只记录它在沙盒里的路径。这样一来,Agent的上下文变短了,信息却不会弄丢。
把文件系统当成Agent的“外部大脑”,这个策略非常前卫。它不仅绕开了上下文长度的硬限制,更重要的是革新了信息处理的方式——像人一样,把“短期记忆”(LLM上下文)和“长期记忆”(文件系统)结合起来。
Manipulate Attention Through Recitation
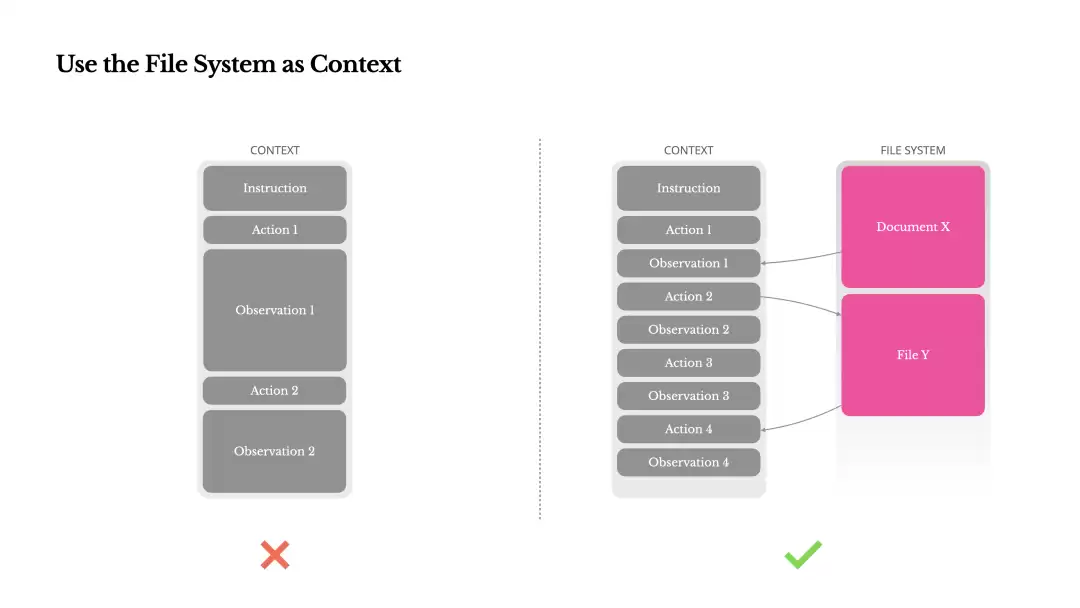
用过Manus的人可能会注意到,它在处理复杂任务时,会创建一个todo.md文件,并且随着任务进展不断更新,标记已完成项。这不是个随意的习惯,而是精心设计出来的“注意力操纵”策略。
一个典型的Manus任务可能要调用50次工具,这是一个很长的循环。在上下文过长或任务太复杂时,大模型容易出现“注意力漂移”,忘了最初要干什么,这就是所谓的“lost-in-the-middle”现象。人干多线任务时也会这样,中途被打断几次就不知道刚才要干嘛了。
Manus的解法很简单:不断重写todo.md,把目标反复“复述”到上下文的末尾。这个策略非常有效,它把全局计划强制推到了模型最近的注意力范围里,从而有效避免了“lost-in-the-middle”,让Agent始终保持目标感。
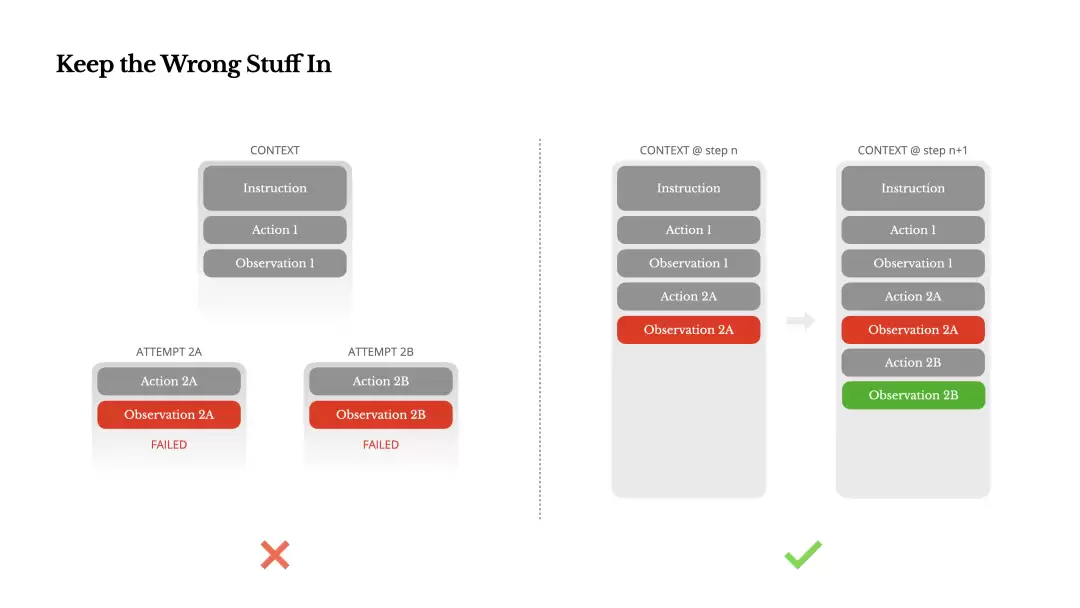
Keep the Wrong Stuff In
Agent在工作过程中犯错是必然的。模型会幻觉,环境会报错,工具调用也可能不按预期跑。在多步骤任务里,失败不是偶然,而是循环过程的固有组成部分。
但很多人在面对错误时,第一反应是“擦干净”:清理错误日志,重新试一次,甚至重置模型状态,然后归咎于那个“神奇”的temperature参数。这种做法看似安全,代价却是抹掉了失败的证据,让模型失去了从错误里学习的机会。
Manus的经验揭示了一个简单却有效的方法:把错误的尝试,连同它的错误信息或者堆栈跟踪,原封不动地保留在上下文里。当模型“看到”一个失败的动作及其反馈时,它会默默更新自己的“认知”——“哦,原来这样行不通”。下次再碰到类似情况,它就会自动绕开。
Manus甚至认为,Agent从错误中恢复的能力,是判断它是否真的具备“智能”的最明显标志之一。遗憾的是,目前大多数的学术研究和公开评测,还是只关注理想条件下的成功率,而忽视了这种从失败中学习的能力。
总结
上下文工程,对于AI Agent系统来说,是一门新兴且至关重要的学问。大语言模型本身的能力当然在持续增强,推理更快、成本更低,但它们无法替代Agent的“记忆力”、与环境交互的能力,以及从反馈中持续学习的能力。最终,Agent的智能、恢复能力和可扩展性,都取决于你为它搭建的那个“上下文舞台”。
Manus团队分享的这些经验,来自无数次的迭代和挑战,背后是数百万真实用户的反馈沉淀。这些策略不是放之四海而皆准的真理,但它们在Manus的实践中已经被证明非常有效。能帮你避开一些潜在的坑,少走点弯路,那就达到目的了。




