上一篇结尾,我们探讨了第三种出发点。它既不同于Karpathy为研究者设计的“知识积累成百科”,也有别于范凯为创作者打造的“知识变成内容产出”,而是一个更为朴素的目标:将陌生而复杂的行业,逐步纳入自己的认知版图。
有几位读者私信表示,这句话让他们瞬间产生了强烈共鸣。但也有更多人追问:你提到的“认知底座”,具体形态是怎样的?它跟前两种方案有哪些本质区别?
本文将全面剖析这一概念。
一、一个真实的场景
假设你是一家保险公司的AI架构师。团队技术能力毋庸置疑,RAG、Agent、Fine-tuning等各项技术都驾轻就熟。但总有一个场景让你头疼:团队提交的方案,技术上无可挑剔,可一旦呈现给业务方,对方沉默三秒后,抛出这样一句——“你们没考虑再保分出的影响。”
你知道“再保分出”是什么。但你不确定它在当前这个具体场景中,会如何影响产品定价的下限;不清楚监管部门对此的最新口径;更不了解业务方真正的顾虑,究竟在于合规还是利润。概念可以查到,但缺少的是将概念串联为判断的“手感”。
这才是做AI+传统行业的真正难点。并非不懂AI,甚至也不是不懂行业术语——问题在于,作为架构师,你必须在行业的灰度地带做出架构判断。这些判断没有标准答案,也没有任何教程能提供。它们只能从大量的碎片化行业认知中慢慢生长出来:一份监管文件背后的深层意图、一次与精算师的午间闲聊、一个竞品方案失败的真实原因。
更令人疲惫的是你的处境。你是公司里唯一一个需要同时深度理解AI能力边界与行业运作逻辑的人。AI团队觉得你过于保守——“为什么不能直接上RAG?”;业务团队又觉得你过于激进——“你不懂这个行业。”你每天在两种语言之间做翻译,而两边都不把你视为自己人。
你需要的不是一个“知识百科”,也不是一个“内容弹药库”。你需要的是一块地基——一块不断垫厚、持续生长的行业认知层。让你在每次架构决策的瞬间,能凭借对行业的真实理解做出判断,而非仅凭技术直觉去猜测。
这就是“认知底座”。
二、为什么前两种方案不够用
先看Karpathy的方案。
其核心是Wiki——每个概念对应一篇笔记,由AI自动维护交叉引用。这对研究者而言堪称完美,因为研究者的知识是“概念→概念”的网状结构,一个概念可以独立存在。
但架构决策并非靠概念就能做出。
你要判断“核保环节该不该上RAG”,涉及的并非某一个概念,而是一整个情境——再保分出的比例会影响哪些产品线、业务方的真实顾虑是合规还是利润、监管对AI辅助决策的口径是否有变化。这些要素必须捆绑在一起,才能形成一个可以指导架构的结论。
行业知识的最小单位不是“概念”,而是“情境”——谁、在什么条件下、为什么这么做、我据此做了什么决策。Karpathy的Wiki模式天然倾向于将情境拆解为独立概念。一旦拆散,即便链接再紧密,也补不回来那个“活的决策上下文”。
再来审视范凯的方案。
其核心是产出——知识必须转化为文章、视频、SOP。弹药库再充实,如果不开枪,就等于没有。
但作为架构师,你的“产出”并非内容,而是架构判断和技术决策。这些东西无需写成文章发布出去,它们需要在你的脑海中慢慢变厚、变准、变快。你不是不产出,只是产出形态不是“内容”——而是每次技术评审中的关键判断,是每份架构方案背后那个“为什么选A不选B”的深层考量。
三、两个反常识的设计
上一篇预告过,这套方案有一些“反Karpathy”的地方。这里展开谈谈。
反常识一:Raw不能“只进不改”
Karpathy的raw/是原始档案,只进不改。这对于网页文章、论文来说没问题——原文就是原文,改了反而失真。
但行业素材却不同。
你存了一份监管文件的摘录。三个月后,你终于理解了那段话的真实含义——它表面上说的是“偿付能力充足率”,实际上约束的是产品定价策略。这个理解如果不写回原始记录,下次你翻到它,依然会感到迷惑。
因此,在认知底座中,Raw不叫Raw,而叫sources/。原始素材进来之后,你可以——而且应该——在旁边添加批注。批注用明确的标记隔开,例如 > [我的理解],这样原文和你的认知层次分明,但又共存于同一处。
你的理解会变化。三个月前的批注可能是错误的。没关系,划掉旧的,写上新的,并标注日期。这个“覆盖”的过程,本身就是认知在生长的有力证据。
反常识二:不追求“每个概念一篇笔记”
Karpathy的Wiki追求原子化——一个概念对应一个文件,便于AI维护和交叉引用。
认知底座则反其道而行之。核心单位不是“概念”,而是“判断”。
什么是判断?就是你在工作中基于多个信息源形成的一个架构级结论。比如下面这段:
这段话涉及RAG、重疾险、核保、隐性知识、文档化缺失,最后落到了一个明确的技术路线选择。如果拆成五篇Wiki笔记,每篇都只剩下碎片,而最重要的东西——那个决定了整个项目走向的架构判断——反而无处安放。
因此,认知底座的核心区不叫wiki/,而叫insights/。每篇笔记是一个判断,而非一个概念。标题不是名词(“再保分出”),而是句子(“重疾险核保的瓶颈不在模型能力,在隐性知识的采集”)。
这些判断积累到一定厚度,就是你做架构评审时的底气来源。
四、文件夹结构
MyBrain/
├── sources/ # 带批注的原始素材
│ ├── regulations/ # 监管文件、政策解读
│ ├── industry/ # 行业报告、竞品分析
│ ├── internal/ # 内部文档、会议纪要、口头经验
│ ├── tech/ # 技术文章、论文、工具评测
│ └── conversations/ # 与同事/业务方的关键对话
│
├── insights/ # 你的判断(核心区)
│ ├── validated/ # 已验证的判断
│ └── tentative/ # 暂时的判断,待验证
│
├── maps/ # 认知地图
│ ├── domain.md # 行业全景图:这个行业的关键环节是什么
│ ├── gaps.md # 盲区清单:我还不懂什么
│ └── changelog.md # 认知变更记录:我的理解哪里变了、为什么变了
│
└── schema.md # 整体说明 + AI 协作规则
整体说明 + AI 协作规则
跟前两个方案做个对比——
| Karpathy | 范凯 | 认知底座 | |
|---|---|---|---|
| 原始素材 | raw/ 只进不改 | Notes/ 分三类 | sources/ 带批注,可覆盖 |
| 核心区 | wiki/ 概念为单位 | Knowledge/ + Writing/ | insights/ 判断为单位 |
| 独有的层 | 无 | 产出层、行动层 | maps/ 认知地图 |
| AI角色 | 主笔 | 参谋 | 陪练 |
| 核心动词 | 积累 | 产出 | 理解 |
重点说说maps/这个文件夹,它是认知底座独有的组成部分。
domain.md是对整个行业的全景理解。刚开始可能只有五六个粗糙的方框,半年后会演变成一张密密麻麻的地图。这张地图并非展示给别人看,而是为自己所用——每次做架构决策前扫一眼,确认自己没有遗漏任何关键环节。
gaps.md是盲区清单。你可以随时记录“我不懂XXX”。AI会定期扫描这个清单,与你已有的sources/和insights/进行交叉比对,告诉你哪些盲区其实已有足够的素材可以攻克——你只是还没静下心来思考。
changelog.md是最容易被忽视、但最具价值的文件之一。每次你的理解发生重大变化,就记录一笔。例如:
2025-03-12:修正了对“再保分出影响产品定价下限”的理解。原来以为只影响定价模型,与精算师沟通后才发现它同时影响合规层面的准备金计提,这意味着RAG系统里必须同时索引这两类文档。
半年后翻阅changelog,你会清晰地看到自己的认知是如何一步步修正的。这种“看到自己在成长”的感觉,是坚持走下去最强的动力。
一个必须讲清楚的副作用
做架构师的人读到这里会意识到一件事:你的insights/积累到一定厚度后,它们就是你为企业搭建AI系统时的“架构草图”。
这并非比喻,而是字面意义上的对应——
- 每一条validated判断,都可能直接变为规则引擎里的一条逻辑,或者RAG系统里一段高质量的System Prompt;
- domain.md的行业全景图,本质上就是系统的领域模型(Domain Model)的初稿;
- changelog.md里记录的“我的理解哪里变了”,对应着系统设计里最容易被忽略的东西:为什么我们上一版这样做,以及为什么现在必须改。
优秀的系统设计始终建立在对领域的深度理解之上。DDD(领域驱动设计)讲了二十年的事,在AI系统上以一种更残酷的方式重现——你不理解领域,你的Prompt就是空的,你的检索就是乱的,你的Agent就是盲目运行的。
但顺序不能颠倒。如果一开始就冲着“为系统积累素材”去构建认知底座,你会不自觉地跳过那些“暂时没用但帮你理解行业全貌”的内容,最终搭建的系统看似完整,实则只覆盖了你碰巧了解的部分。先有理解,再有系统。认知底座是因,架构草图是果。颠倒过来,就是另一个失败项目的开端。
五、日常动作与协作规则
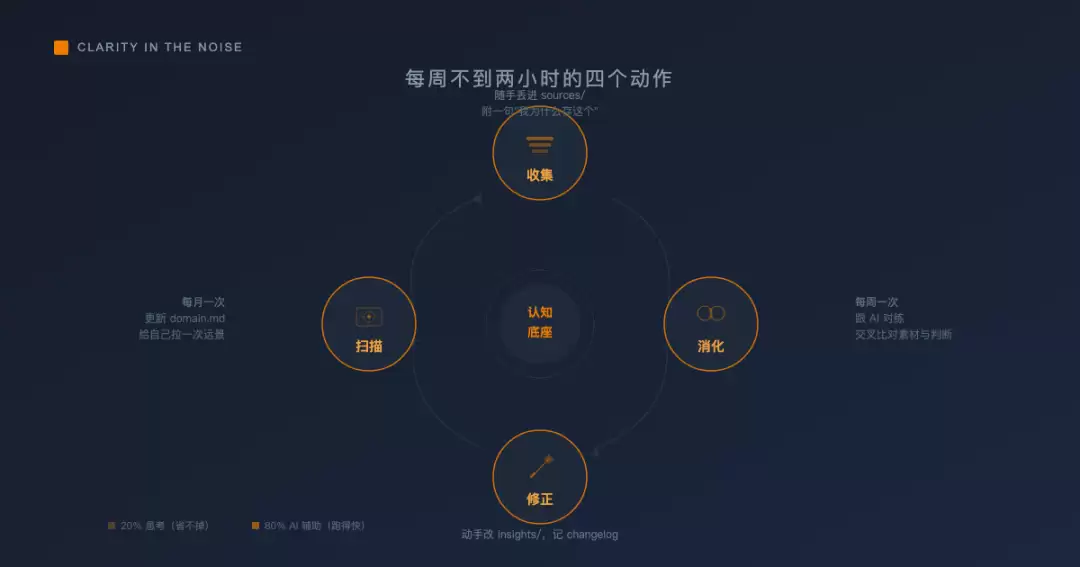
落实到日常,只需四个动作,每周耗时不到两小时。
收集——随手进行,但需附带一句话
最有价值的素材往往不是文章和论文,而是最容易消失的东西:一个提案被否决的真实原因(通常不会写在会议纪要里)、一个业务老手随口说出的半句话、一次技术评审后走廊里的补充说明。这些东西如果不在24小时内存入sources/,就永远消失了。
存入时,在最上方写一句话——“我为什么存这个”。一句就足够。比如“跟上周老王提到的定价逻辑有关”。不写这句话,三个月后这篇文章就成了信息孤岛。
消化——每周一次,与AI对练
请基于我最近一周新增的sources/,对比我现有的insights/,找出:哪些新素材与现有判断一致(加固),哪些暗示旧判断需要修正(挑战),哪些覆盖了全新的盲区(新增)。针对每一条,给我一个具体的问题让我思考,而不是直接下结论。
这一步是整套系统的核心。AI并非在“帮你做笔记”,而是在用你自己的素材来反向考你。
修正——动手调整insights
AI给出建议后,由你来决定:这个旧判断确实需要改,还是AI理解错了?这个新判断我是否同意?修改完成后,在changelog.md记录一笔。这20%的思考时间省不掉——但也只需要20%。
扫描——每月一次,更新全景图
根据insights/当前的状况,重新审视maps/domain.md,建议哪些区域需要补充细节、哪些连线需要修正。
你根据建议,手动完善地图。做AI+传统行业最容易掉入的陷阱,就是埋头于某个局部无法自拔。每月一次的全景扫描,是给自己拉一次远景。
AI的角色:陪练,不是主笔
Karpathy让AI主笔维护Wiki,范凯让AI先报方案再执行。在认知底座中,AI的角色进一步后退——它是陪练,而非助手。
你跟AI说“帮我理清这个逻辑链”,它会将你已有的素材串联起来,指出哪些环节你已有材料支撑,哪些环节仍是空白。它不替你下结论,而是帮你认清自己的认知地图上哪里还有缺口。
你可能要问:这种陪练,一个资深同事不是能做得更好吗?
三个理由说明这件事必须由AI来完成。
第一,规模。半年后你的sources/里会有两三百篇素材,insights/里会有几十条判断。你自己不可能每周全量扫描并做交叉比对,任何同事也不会承担这种苦差事。AI可以。这并非“AI帮你省时间”,而是人类根本做不到。
第二,主动性。优秀的AI陪练会主动说:“你在validated/里的第23条判断,与本周新存的那篇监管文件存在冲突,是没注意到还是有意忽略?”——或者:“你在‘隐性知识采集’这个主题上过去半年改了5次判断,可能表明你的理解还不够稳定。”这种跨时间、跨文件的模式发现,你自己身处其中反而无法察觉。
第三,无社交成本。你在insights/里需要能够写出“这条核保规则大概率是老王拍脑袋定的,缺乏精算支撑”这种极其诚实的判断。这话在任何真人面前都说不出口——哪怕他是你最信任的同事。AI是唯一一个可以让你诚实到这种程度的陪练对象。认知底座一旦失去这种诚实,立刻就变成一份漂亮的自我欺骗。
它看起来不像前两种方案中AI那样“一直在忙碌”,但它所做的工作不可替代。
这个定位写进schema.md,Claude Code每次打开文件夹时就会遵守。核心规则包括:
你的角色
你是我的认知陪练,不是笔记助手。目标是加深我对行业的理解,而非帮我产出精美的笔记。
绝对不做的事
- 不替我下判断。可以说“素材A和B似乎指向X”,不能说“结论是X”。
- 不在我确认的情况下修改insights/。
- 不删除sources/里的任何内容。
- 不编造sources/里没有的行业知识。素材不足时,直接说“现有sources无法支撑该判断”。
insights/规则
- 标题是判断句,不是名词。
- 分validated/和tentative/两个状态。
- 当tentative判断被至少三条独立素材支撑时,建议我移至validated/。
- 当新素材与已有判断矛盾时,立即提醒我。
完整模板可放在文末链接中,根据行业和习惯进行调整。但“不替我下判断”这条建议请务必保留。认知底座的全部意义在于:理解是你自己生长出来的,AI只是帮你更清晰地看到哪里尚未成长。
六、它会长多大,如何成长

到这里有人会产生一个真实的疑虑:判断如此零散,真的能长成一个有用的系统吗?还是最终只是一堆砖头,永远无法建成房屋?
先给出结论:零散不是缺陷,而是起点。系统化不是靠你设计出来的,是从密度中涌现出来的。
接下来详细阐述。
量级
作为AI+传统行业的架构师,你实际面对的判断问题来自至少六个层面——技术选型、数据边界、业务规则、组织诉求、监管口径、行业演化。这六层交叉叠加,仅保险行业就能产生数百个独立的判断问题。
因此,insights/的增长曲线大致如下:第一年快速积累到80-120条,第二年缓慢增至150-200条但大量tentative转为validated,第三年之后新增极少、每条持续变厚。这种形状是对数增长——与下一节要讲的“判断力拐点”,是同一件事的两个侧面。
系统化发生的三个机制
机制一:聚类。当insights/达到30-50条时,AI每月扫描会发现簇。例如:“你过去三个月的17条判断中,有6条都指向同一个底层约束——保险业的隐性知识比显性知识多。场景完全不同,但都在讲述同一件事。”这个簇抽象出来就是一条上位判断,它不是你强行总结的,而是自下而上浮现的。上位判断一旦确立,它就成了你这个领域的公理,后续所有新判断都会受到它的筛选。
机制二:冲突驱动的精化。当两条判断相互矛盾时,系统化被迫发生。
A(半年前):“RAG在重疾险核保不可行,瓶颈是隐性知识。”
B(上周):“某医疗险客户用RAG做辅助核保,效果不错。”
AI指出冲突。你被迫思考:是A错了,B错了,还是两者都对但适用条件不同?你最终写出:
C:“RAG在保险核保中的可行性取决于该险种规则的显性化程度。重疾险 < 医疗险 < 车险,分界点在X。”
C比A和B都高一个级别——它不是并列的砖,而是梁。梁出现之后,系统才开始拥有骨架。冲突越多,梁就越多。两年之后,你的insights/将从“一堆砖”变成“一栋房屋”。
机制三:domain.md的反向牵引。每次做架构决策前扫一眼全景图,你会发现某些区域判断密集(你在那里思考较多),某些区域几乎空白(你从未深入思考过)。空白区就是gaps.md新增的来源——你甚至不知道自己不知道的事情,通过地图的不均匀分布被暴露出来。没有domain.md的知识库,你永远无法认识到自己的偏科。
最终形态
两年之后,你不会得到一个“目录整齐的知识库”。你得到的是一个从底部长出来的行业理解框架。它看起来仍然是零散的砖和梁,但你站在其中,能一眼看清这个行业的承重结构。
这就是“系统性”真正的面貌——不是目录整齐,而是判断之间互相承重。
七、三个冷静的提醒
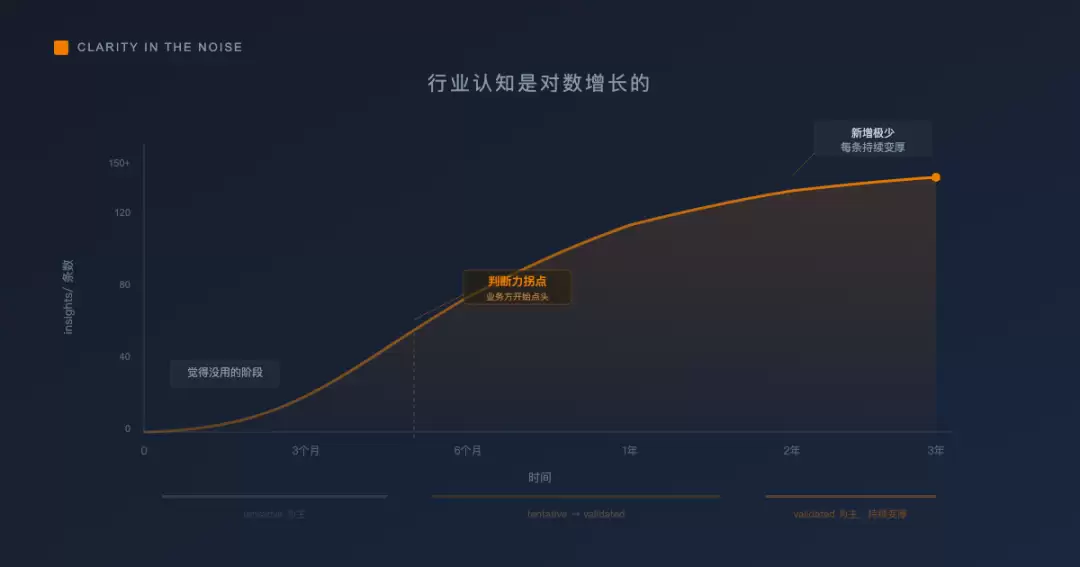
第一,前三个月会觉得没用——直到那个拐点来临。
Karpathy的方案搭建完成即可查询,范凯的方案搭建完成即可输出。认知底座则不同——前三个月你的insights/里可能只有十几条半生不熟的判断,domain.md就像小学生画的地图一样粗糙。
行业认知并非翻倍增长,而是对数增长。一开始很慢,慢到你反复怀疑这套方法到底有没有用。
然后某一天会发生这样的事:你坐在一个跨部门技术评审会上,业务方抛出一个问题,过去的你会本能地看向精算师或核保负责人求助,这次你在他们开口之前已经想明白了。你听见自己说:“这个方案不可行,不是因为技术,而是因为渠道差异会让它在三四线市场失真。我们应该先做A,再做B。”会议室安静了几秒钟,业务方点头认可。
那一刻你知道底座已经长成。它不会在第一个月到来,也不会以“啊哈时刻”的方式降临。它是在某天突然发现自己已经站在那里了。
第二,这套方案的天花板就是你的投入。
Karpathy的天花板取决于AI的维护能力,范凯的天花板取决于产出频率。认知底座的天花板只取决于一件事:你每周是否真的坐下来进行那20分钟的消化。AI能将素材摆在你面前,但那个“啊,原来是这样”的顿悟时刻,只能由你自己到达。
但也正因如此,认知底座是你手中最抗通胀的资产。做AI+传统行业的人都有一种特殊的焦虑:AI技术每周都在变,行业知识却要以年为单位积累,你觉得自己同时在追逐两条赛道,哪条都追不上。认知底座帮你将这两条赛道分开:sources/tech/里的内容会不断过时,但你insights/里的行业判断——“核保的瓶颈不在模型能力,在隐性知识的采集”——不会因为模型从GPT-4换成GPT-5就失效。技术在变,但你对行业的理解才是真正持久的。
第三,合规是硬约束,不是可选项。
作为架构师,你比谁都清楚:传统行业最有价值的素材往往也是最敏感的——核保案例、赔付数据、内部决策纪要。如果你使用的是公网大模型(包括Claude Code默认模式),这些内容会离开你的电脑。金融、医疗、政务行业对此零容忍。
务实的做法是分层处理:sources/internal/中涉及真实业务数据的部分,要么脱敏后再提供给AI,要么使用本地部署的模型(如Qwen、DeepSeek本地版)来运行消化流程。你自身在合规方面的做法,就是在为团队树立标杆。
八、三种方案,三种人

三篇文章写完,做一次总收束。
| 你的身份 | 你的焦虑 | 你需要的 | 方案 |
|---|---|---|---|
| 研究者、学习者 | 知识碎片化,每次从零开始 | 一本越来越厚的百科 | Karpathy原版 |
| 创作者、运营者 | 知道很多却写不出来 | 一个能随时使用的弹药库 | 范凯改造版 |
| AI+传统行业架构师 | 要在灰度地带做架构判断 | 一块慢慢变厚的认知底座 | 本篇方案 |
三种方案使用同一组工具,解决的却是三个完全不同的问题。
搭建知识库的真正第一步,从来不是安装软件,而是认清自己是哪种人。这件事,上一篇已经探讨过。这一篇则把最后一块拼图补充完整。
最后一个问题
但我明白你心中还有一个问题,读到此处仍未得到解答。
“我花一周想清楚一条insight,而同一时间模型可能已经爬取了一百万条新数据。我如此辛苦地建设底座,值得吗?”
这个问题大到需要单独一篇文章来回答。因此,将其留到下一篇——作为这个系列的番外篇,也是整个三篇方法论体系最底层的基石。
先给出一个结论,供你在感到不安的那些日子里使用:与AI比拼学习速度,是一场必输的赛跑。但你还有另一场稳赢的比赛——只是赛道不同,大多数人尚未意识到。
这一篇教你如何建设底座。下一篇将告诉你,为什么值得建设。
今天就做的一件事
打开你的Obsidian,创建一个maps/文件夹,在其中新建一个gaps.md文件。然后做一件可能让你感到些许不适的事情——
写下三个你上周刚刚为团队拍板做出的决定,但今天回想起来,你并没有十足把握那个判断是正确的。
不是“我不懂的三个概念”——那种清单,老手随便就能写出一页。而是“我已经拍了板、团队已经在执行、但如果现在重来一次,我其实答不上来为什么是这个选择而不是另一个”的三个决定。
如果你写不出来,恭喜你,说明你不需要认知底座。
如果你写出来了——那三条就是你认知底座的第一块砖。它们太烫手了,必须立刻开始砌筑。




